 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Aware Neural Collapse Prompt Tuning for Long-Tailed Generalization of Vision-Language Models
May 12, 2026Prompt learning has emerged as an efficient alternative to fine-tuning pre-trained vision-language models (VLMs). Despite its promise, current methods still struggle to maintain tail-class discriminability when adapting to class-imbalanced datasets. In this work, we propose cluster-aware neural collapse prompt tuning (CPT), which enhances the discriminability of tail classes in prompt-tuned VLMs without sacrificing their overall generalization. First, we design a cluster-invariant space by mining semantic assignments from the pre-trained VLM and mapping them to prompt-tuned features. This computes cluster-level boundaries and restricts the constraints to local neighborhoods, which reduces interference with the global semantic structure of the pre-trained VLM. Second, we introduce neural-collapse-driven discriminability optimization with three losses: textual Equiangular Tight Frame (ETF) separation loss, class-wise convergence loss, and rotation stabilization loss. These losses work together to shape intra-cluster geometry for better inter-class separation and intra-class alignment. Extensive experiments on 11 diverse datasets demonstrate that CPT outperforms SOTA methods, with stronger performance on long-tail classes and good generalization to unseen classes.
Amped: Adaptive Multi-stage Non-edge Pruning for Edge Detection
Mar 29, 2026Edge detection is a fundamental image analysis task that underpins numerous high-level vision applications. Recent advances in Transformer architectures have significantly improved edge quality by capturing long-range dependencies, but this often comes with computational overhead. Achieving higher pixel-level accuracy requires increased input resolution, further escalating computational cost and limiting practical deployment. Building on the strong representational capacity of recent Transformer-based edge detectors, we propose an Adaptive Multi-stage non-edge Pruning framework for Edge Detection(Amped). Amped identifies high-confidence non-edge tokens and removes them as early as possible to substantially reduce computation, thus retaining high accuracy while cutting GFLOPs and accelerating inference with minimal performance loss. Moreover, to mitigate the structural complexity of existing edge detection networks and facilitate their integration into real-world systems, we introduce a simple yet high-performance Transformer-based model, termed Streamline Edge Detector(SED). Applied to both existing detectors and our SED, the proposed pruning strategy provides a favorable balance between accuracy and efficiency-reducing GFLOPs by up to 40% with only a 0.4% drop in ODS F-measure. In addition, despite its simplicity, SED achieves a state-of-the-art ODS F-measure of 86.5%. The code will be released.
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
PC-bzip2: a phase-space continuity enhanced lossless compression algorithm for light field microscopy data
Oct 14, 2023Light-field fluorescence microscopy (LFM) is a powerful elegant compact method for long-term high-speed imaging of complex biological systems, such as neuron activities and rapid movements of organelles. LFM experiments typically generate terabytes image data and require a huge number of storage space. Some lossy compression algorithms have been proposed recently with good compression performance. However, since the specimen usually only tolerates low power density illumination for long-term imaging with low phototoxicity, the image signal-to-noise ratio (SNR) is relative-ly low, which will cause the loss of some efficient position or intensity information by using such lossy compression al-gorithms. Here, we propose a phase-space continuity enhanced bzip2 (PC-bzip2) lossless compression method for LFM data as a high efficiency and open-source tool, which combines GPU-based fast entropy judgement and multi-core-CPU-based high-speed lossless compression. Our proposed method achieves almost 10% compression ratio improvement while keeping the capability of high-speed compression, compared with original bzip2. We evaluated our method on fluorescence beads data and fluorescence staining cells data with different SNRs. Moreover, by introducing the temporal continuity, our method shows the superior compression ratio on time series data of zebrafish blood vessels.
Learning Cross-view Geo-localization Embeddings via Dynamic Weighted Decorrelation Regularization
Nov 10, 2022Cross-view geo-localization aims to spot images of the same location shot from two platforms, e.g., the drone platform and the satellite platform. Existing methods usually focus on optimizing the distance between one embedding with others in the feature space, while neglecting the redundancy of the embedding itself. In this paper, we argue that the low redundancy is also of importance, which motivates the model to mine more diverse patterns. To verify this point, we introduce a simple yet effective regularization, i.e., Dynamic Weighted Decorrelation Regularization (DWDR), to explicitly encourage networks to learn independent embedding channels. As the name implies, DWDR regresses the embedding correlation coefficient matrix to a sparse matrix, i.e., the identity matrix, with dynamic weights. The dynamic weights are applied to focus on still correlated channels during training. Besides, we propose a cross-view symmetric sampling strategy, which keeps the example balance between different platforms. Albeit simple, the proposed method has achieved competitive results on three large-scale benchmarks, i.e., University-1652, CVUSA and CVACT. Moreover, under the harsh circumstance, e.g., the extremely short feature of 64 dimensions, the proposed method surpasses the baseline model by a clear margin.
Textual Analysis of Communications in COVID-19 Infected Community on Social Media
May 03, 2021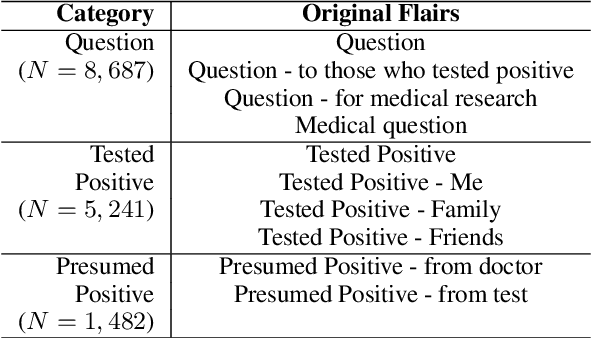

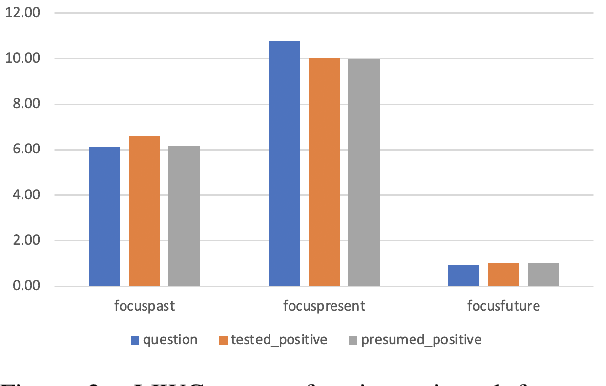
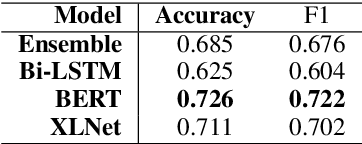
During the COVID-19 pandemic, people started to discuss about pandemic-related topics on social media. On subreddit \textit{r/COVID19positive}, a number of topics are discussed or being shared, including experience of those who got a positive test result, stories of those who presumably got infected, and questions asked regarding the pandemic and the disease. In this study, we try to understand, from a linguistic perspective, the nature of discussions on the subreddit. We found differences in linguistic characteristics (e.g. psychological, emotional and reasoning) across three different categories of topics. We also classified posts into the different categories using SOTA pre-trained language models. Such classification model can be used for pandemic-related research on social media.