 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-shot Action Recognition with Captioning Foundation Models
Oct 16, 2023
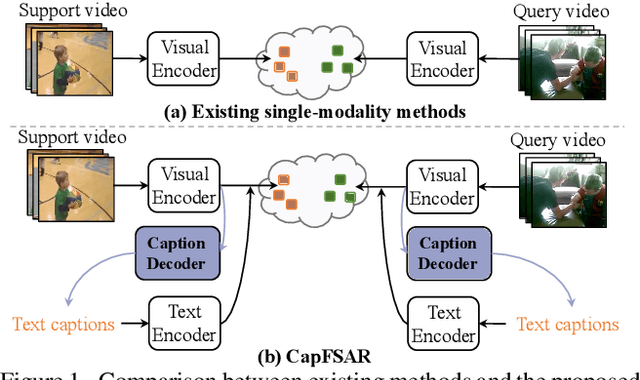
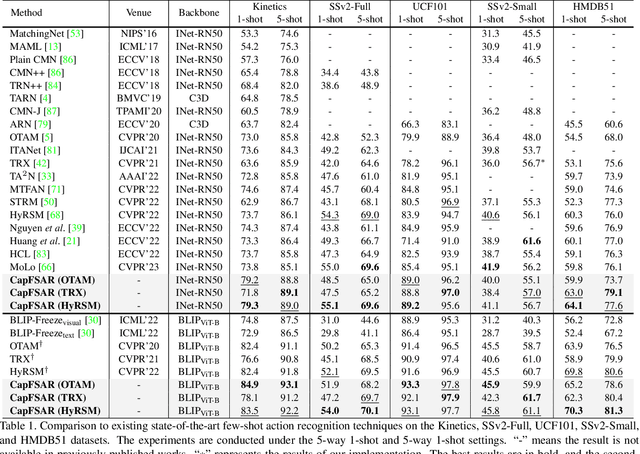
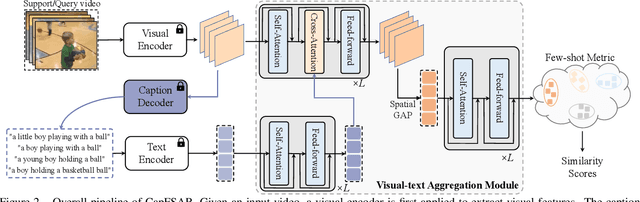
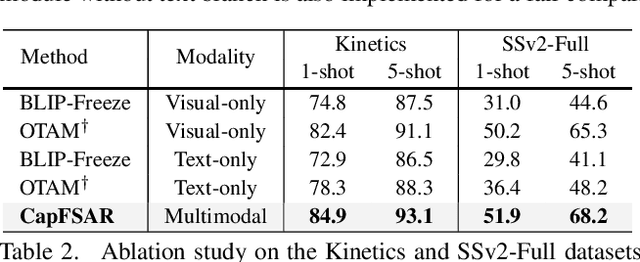
Transferring vision-language knowledge from pretrained multimodal foundation models to various downstream tasks is a promising direction. However, most current few-shot action recognition methods are still limited to a single visual modality input due to the high cost of annotating additional textual descriptions. In this paper, we develop an effective plug-and-play framework called CapFSAR to exploit the knowledge of multimodal models without manually annotating text. To be specific, we first utilize a captioning foundation model (i.e., BLIP) to extract visual features and automatically generate associated captions for input videos. Then, we apply a text encoder to the synthetic captions to obtain representative text embeddings. Finally, a visual-text aggregation module based on Transformer is further designed to incorporate cross-modal spatio-temporal complementary information for reliable few-shot matching. In this way, CapFSAR can benefit from powerful multimodal knowledge of pretrained foundation models, yielding more comprehensive classification in the low-shot regime. Extensive experiments on multiple standard few-shot benchmarks demonstrate that the proposed CapFSAR performs favorably against existing methods and achieves state-of-the-art performance. The code will be made publicly available.
Interpreting and Exploiting Functional Specialization in Multi-Head Attention under Multi-task Learning
Oct 16, 2023
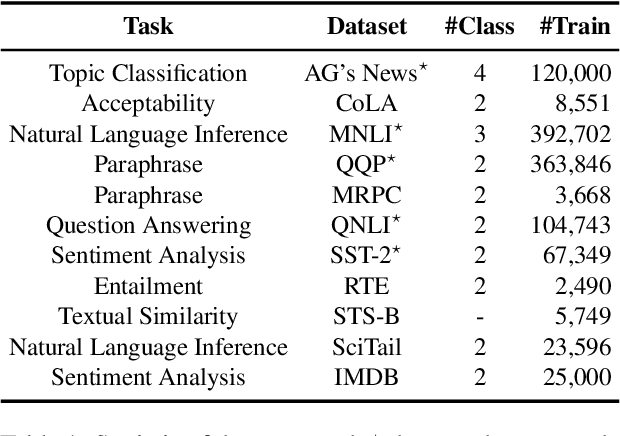
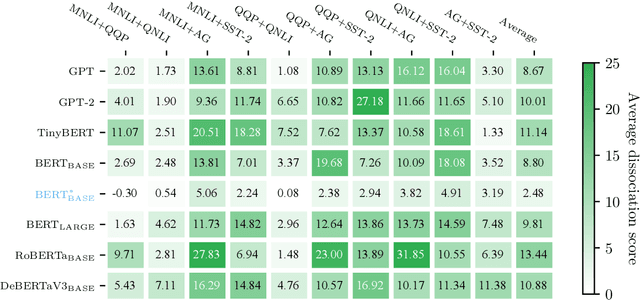
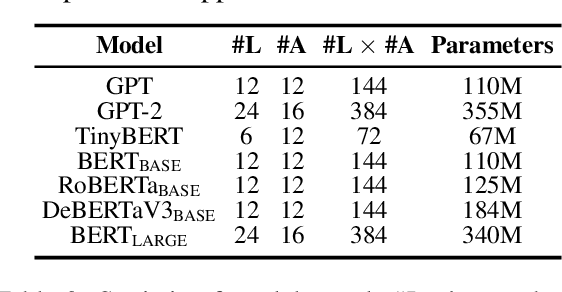
Transformer-based models, even though achieving super-human performance on several downstream tasks, are often regarded as a black box and used as a whole. It is still unclear what mechanisms they have learned, especially their core module: multi-head attention. Inspired by functional specialization in the human brain, which helps to efficiently handle multiple tasks, this work attempts to figure out whether the multi-head attention module will evolve similar function separation under multi-tasking training. If it is, can this mechanism further improve the model performance? To investigate these questions, we introduce an interpreting method to quantify the degree of functional specialization in multi-head attention. We further propose a simple multi-task training method to increase functional specialization and mitigate negative information transfer in multi-task learning. Experimental results on seven pre-trained transformer models have demonstrated that multi-head attention does evolve functional specialization phenomenon after multi-task training which is affected by the similarity of tasks. Moreover, the multi-task training strategy based on functional specialization boosts performance in both multi-task learning and transfer learning without adding any parameters.
A Comprehensive Evaluation of Tool-Assisted Generation Strategies
Oct 16, 2023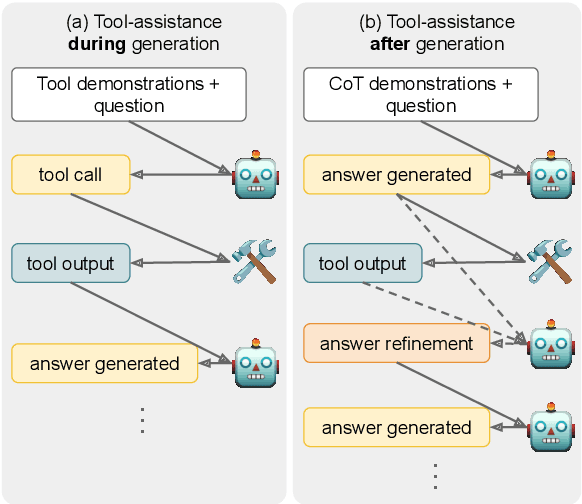

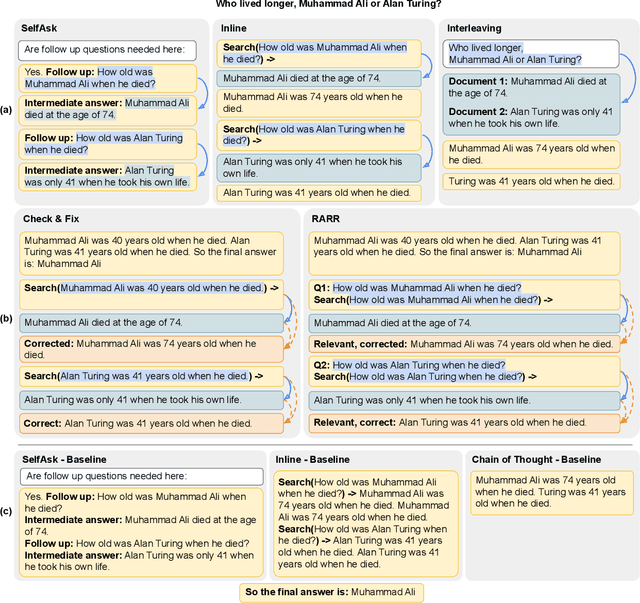
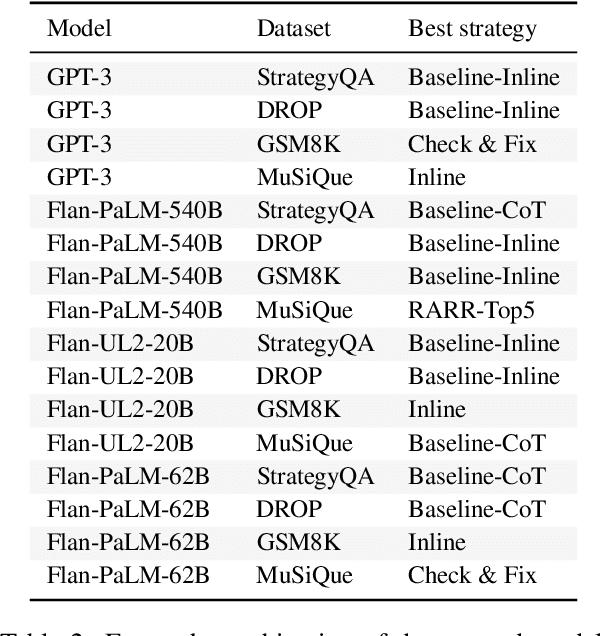
A growing area of research investigates augmenting language models with tools (e.g., search engines, calculators) to overcome their shortcomings (e.g., missing or incorrect knowledge, incorrect logical inferences). Various few-shot tool-usage strategies have been proposed. However, there is no systematic and fair comparison across different strategies, or between these strategies and strong baselines that do not leverage tools. We conduct an extensive empirical analysis, finding that (1) across various datasets, example difficulty levels, and models, strong no-tool baselines are competitive to tool-assisted strategies, implying that effectively using tools with in-context demonstrations is a difficult unsolved problem; (2) for knowledge-retrieval tasks, strategies that *refine* incorrect outputs with tools outperform strategies that retrieve relevant information *ahead of* or *during generation*; (3) tool-assisted strategies are expensive in the number of tokens they require to work -- incurring additional costs by orders of magnitude -- which does not translate into significant improvement in performance. Overall, our findings suggest that few-shot tool integration is still an open challenge, emphasizing the need for comprehensive evaluations of future strategies to accurately assess their *benefits* and *costs*.
Joint Music and Language Attention Models for Zero-shot Music Tagging
Oct 16, 2023Music tagging is a task to predict the tags of music recordings. However, previous music tagging research primarily focuses on close-set music tagging tasks which can not be generalized to new tags. In this work, we propose a zero-shot music tagging system modeled by a joint music and language attention (JMLA) model to address the open-set music tagging problem. The JMLA model consists of an audio encoder modeled by a pretrained masked autoencoder and a decoder modeled by a Falcon7B. We introduce preceiver resampler to convert arbitrary length audio into fixed length embeddings. We introduce dense attention connections between encoder and decoder layers to improve the information flow between the encoder and decoder layers. We collect a large-scale music and description dataset from the internet. We propose to use ChatGPT to convert the raw descriptions into formalized and diverse descriptions to train the JMLA models. Our proposed JMLA system achieves a zero-shot audio tagging accuracy of $ 64.82\% $ on the GTZAN dataset, outperforming previous zero-shot systems and achieves comparable results to previous systems on the FMA and the MagnaTagATune datasets.
Prompt Tuning for Multi-View Graph Contrastive Learning
Oct 16, 2023In recent years, "pre-training and fine-tuning" has emerged as a promising approach in addressing the issues of label dependency and poor generalization performance in traditional GNNs. To reduce labeling requirement, the "pre-train, fine-tune" and "pre-train, prompt" paradigms have become increasingly common. In particular, prompt tuning is a popular alternative to "pre-training and fine-tuning" in natural language processing, which is designed to narrow the gap between pre-training and downstream objectives. However, existing study of prompting on graphs is still limited, lacking a framework that can accommodate commonly used graph pre-training methods and downstream tasks. In this paper, we propose a multi-view graph contrastive learning method as pretext and design a prompting tuning for it. Specifically, we first reformulate graph pre-training and downstream tasks into a common format. Second, we construct multi-view contrasts to capture relevant information of graphs by GNN. Third, we design a prompting tuning method for our multi-view graph contrastive learning method to bridge the gap between pretexts and downsteam tasks. Finally, we conduct extensive experiments on benchmark datasets to evaluate and analyze our proposed method.
Deep learning applied to EEG data with different montages using spatial attention
Oct 16, 2023The ability of Deep Learning to process and extract relevant information in complex brain dynamics from raw EEG data has been demonstrated in various recent works. Deep learning models, however, have also been shown to perform best on large corpora of data. When processing EEG, a natural approach is to combine EEG datasets from different experiments to train large deep-learning models. However, most EEG experiments use custom channel montages, requiring the data to be transformed into a common space. Previous methods have used the raw EEG signal to extract features of interest and focused on using a common feature space across EEG datasets. While this is a sensible approach, it underexploits the potential richness of EEG raw data. Here, we explore using spatial attention applied to EEG electrode coordinates to perform channel harmonization of raw EEG data, allowing us to train deep learning on EEG data using different montages. We test this model on a gender classification task. We first show that spatial attention increases model performance. Then, we show that a deep learning model trained on data using different channel montages performs significantly better than deep learning models trained on fixed 23- and 128-channel data montages.
PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
Oct 16, 2023Although supervised image denoising networks have shown remarkable performance on synthesized noisy images, they often fail in practice due to the difference between real and synthesized noise. Since clean-noisy image pairs from the real world are extremely costly to gather, self-supervised learning, which utilizes noisy input itself as a target, has been studied. To prevent a self-supervised denoising model from learning identical mapping, each output pixel should not be influenced by its corresponding input pixel; This requirement is known as J-invariance. Blind-spot networks (BSNs) have been a prevalent choice to ensure J-invariance in self-supervised image denoising. However, constructing variations of BSNs by injecting additional operations such as downsampling can expose blinded information, thereby violating J-invariance. Consequently, convolutions designed specifically for BSNs have been allowed only, limiting architectural flexibility. To overcome this limitation, we propose PUCA, a novel J-invariant U-Net architecture, for self-supervised denoising. PUCA leverages patch-unshuffle/shuffle to dramatically expand receptive fields while maintaining J-invariance and dilated attention blocks (DABs) for global context incorporation. Experimental results demonstrate that PUCA achieves state-of-the-art performance, outperforming existing methods in self-supervised image denoising.
Spatial-information Guided Adaptive Context-aware Network for Efficient RGB-D Semantic Segmentation
Aug 11, 2023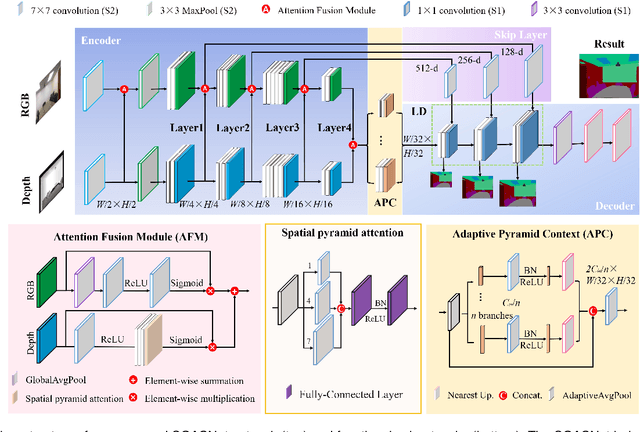
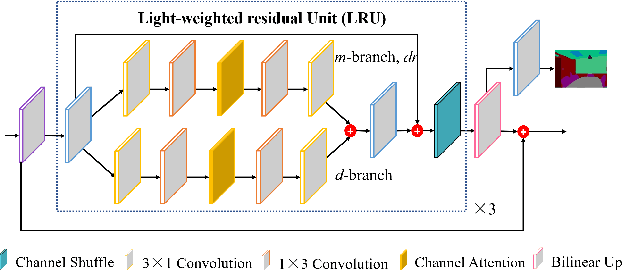
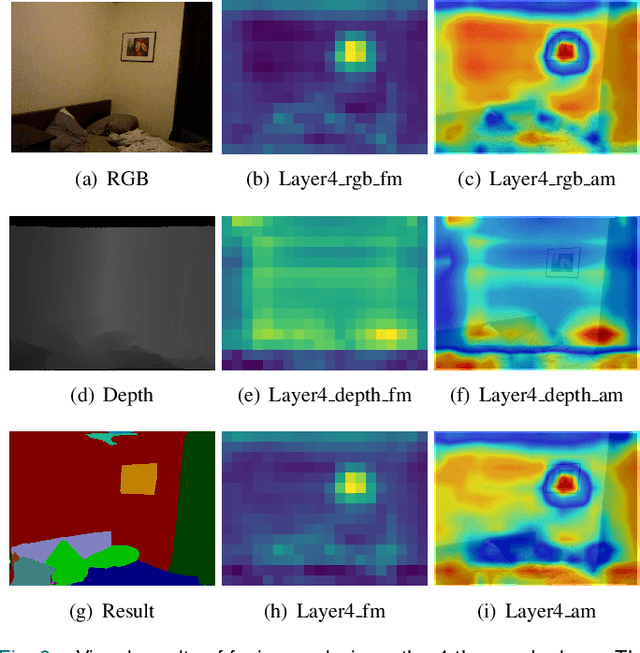
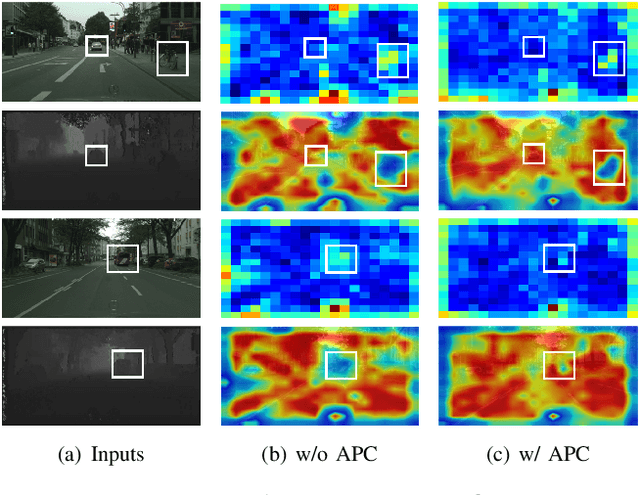
Efficient RGB-D semantic segmentation has received considerable attention in mobile robots, which plays a vital role in analyzing and recognizing environmental information. According to previous studies, depth information can provide corresponding geometric relationships for objects and scenes, but actual depth data usually exist as noise. To avoid unfavorable effects on segmentation accuracy and computation, it is necessary to design an efficient framework to leverage cross-modal correlations and complementary cues. In this paper, we propose an efficient lightweight encoder-decoder network that reduces the computational parameters and guarantees the robustness of the algorithm. Working with channel and spatial fusion attention modules, our network effectively captures multi-level RGB-D features. A globally guided local affinity context module is proposed to obtain sufficient high-level context information. The decoder utilizes a lightweight residual unit that combines short- and long-distance information with a few redundant computations. Experimental results on NYUv2, SUN RGB-D, and Cityscapes datasets show that our method achieves a better trade-off among segmentation accuracy, inference time, and parameters than the state-of-the-art methods. The source code will be at https://github.com/MVME-HBUT/SGACNet
Causally Linking Health Application Data and Personal Information Management Tools
Aug 11, 2023The proliferation of consumer health devices such as smart watches, sleep monitors, smart scales, etc, in many countries, has not only led to growing interest in health monitoring, but also to the development of a countless number of ``smart'' applications to support the exploration of such data by members of the general public, sometimes with integration into professional health services. While a variety of health data streams has been made available by such devices to users, these streams are often presented as separate time-series visualizations, in which the potential relationships between health variables are not explicitly made visible. Furthermore, despite the fact that other aspects of life, such as work and social connectivity, have become increasingly digitised, health and well-being applications make little use of the potentially useful contextual information provided by widely used personal information management tools, such as shared calendar and email systems. This paper presents a framework for the integration of these diverse data sources, analytic and visualization tools, with inference methods and graphical user interfaces to help users by highlighting causal connections among such time-series.
Complex-valued universal linear transformations and image encryption using spatially incoherent diffractive networks
Oct 05, 2023As an optical processor, a Diffractive Deep Neural Network (D2NN) utilizes engineered diffractive surfaces designed through machine learning to perform all-optical information processing, completing its tasks at the speed of light propagation through thin optical layers. With sufficient degrees-of-freedom, D2NNs can perform arbitrary complex-valued linear transformations using spatially coherent light. Similarly, D2NNs can also perform arbitrary linear intensity transformations with spatially incoherent illumination; however, under spatially incoherent light, these transformations are non-negative, acting on diffraction-limited optical intensity patterns at the input field-of-view (FOV). Here, we expand the use of spatially incoherent D2NNs to complex-valued information processing for executing arbitrary complex-valued linear transformations using spatially incoherent light. Through simulations, we show that as the number of optimized diffractive features increases beyond a threshold dictated by the multiplication of the input and output space-bandwidth products, a spatially incoherent diffractive visual processor can approximate any complex-valued linear transformation and be used for all-optical image encryption using incoherent illumination. The findings are important for the all-optical processing of information under natural light using various forms of diffractive surface-based optical processors.