 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-dimensional transfer learning in medical image segmentation with deep learning
Jul 29, 2023
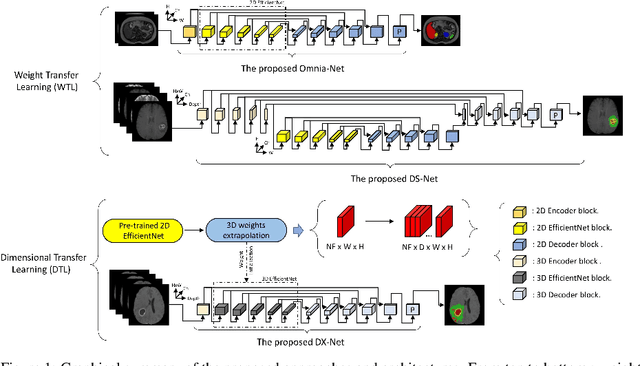

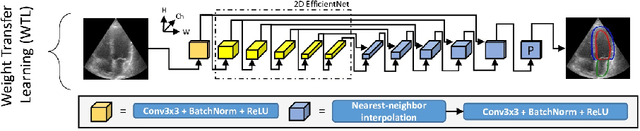
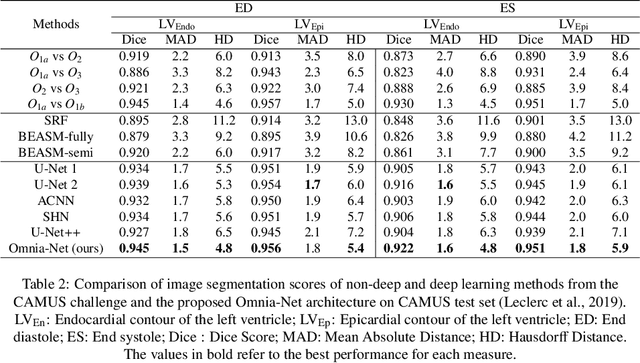
Over the last decade, convolutional neural networks have emerged and advanced the state-of-the-art in various image analysis and computer vision applications. The performance of 2D image classification networks is constantly improving and being trained on databases made of millions of natural images. However, progress in medical image analysis has been hindered by limited annotated data and acquisition constraints. These limitations are even more pronounced given the volumetry of medical imaging data. In this paper, we introduce an efficient way to transfer the efficiency of a 2D classification network trained on natural images to 2D, 3D uni- and multi-modal medical image segmentation applications. In this direction, we designed novel architectures based on two key principles: weight transfer by embedding a 2D pre-trained encoder into a higher dimensional U-Net, and dimensional transfer by expanding a 2D segmentation network into a higher dimension one. The proposed networks were tested on benchmarks comprising different modalities: MR, CT, and ultrasound images. Our 2D network ranked first on the CAMUS challenge dedicated to echo-cardiographic data segmentation and surpassed the state-of-the-art. Regarding 2D/3D MR and CT abdominal images from the CHAOS challenge, our approach largely outperformed the other 2D-based methods described in the challenge paper on Dice, RAVD, ASSD, and MSSD scores and ranked third on the online evaluation platform. Our 3D network applied to the BraTS 2022 competition also achieved promising results, reaching an average Dice score of 91.69% (91.22%) for the whole tumor, 83.23% (84.77%) for the tumor core, and 81.75% (83.88%) for enhanced tumor using the approach based on weight (dimensional) transfer. Experimental and qualitative results illustrate the effectiveness of our methods for multi-dimensional medical image segmentation.
* 30 pages, 12 figures, 6 tables, Accepted for publication in the Journal of Medical Image Analysis
CNN-based automatic segmentation of Lumen & Media boundaries in IVUS images using closed polygonal chains
Sep 29, 2023We propose an automatic segmentation method for lumen and media with irregular contours in IntraVascular ultra-sound (IVUS) images. In contrast to most approaches that broadly label each pixel as either lumen, media, or background, we propose to approximate the lumen and media contours by closed polygonal chains. The chain vertices are placed at fixed angles obtained by dividing the entire 360\degree~angular space into equally spaced angles, and we predict their radius using an adaptive-subband-decomposition CNN. We consider two loss functions during training. The first is a novel loss function using the Jaccard Measure (JM) to quantify the similarities between the predicted lumen and media segments and the corresponding ground-truth image segments. The second loss function is the traditional Mean Squared Error. The proposed architecture significantly reduces computational costs by replacing the popular auto-encoder structure with a simple CNN as the encoder and the decoder is reduced to simply joining the consecutive predicted points. We evaluated our network on the publicly available IVUS-Challenge-2011 dataset using two performance metrics, namely JM and Hausdorff Distance (HD). The evaluation results show that our proposed network mostly outperforms the state-of-the-art lumen and media segmentation methods.
IFAST: Weakly Supervised Interpretable Face Anti-spoofing from Single-shot Binocular NIR Images
Sep 29, 2023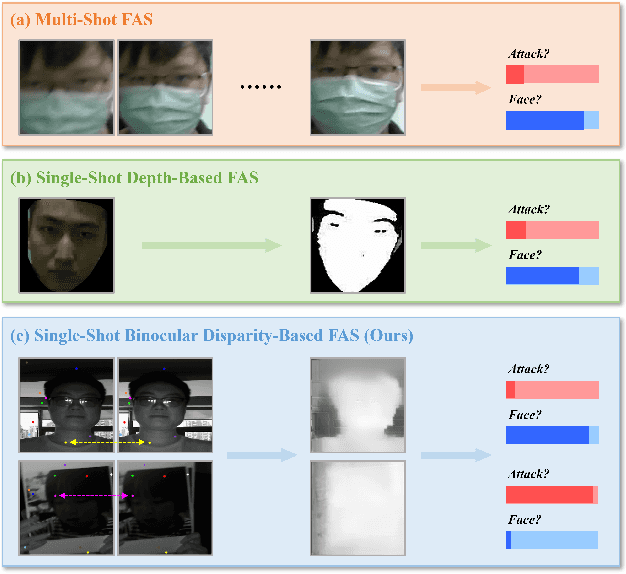



Single-shot face anti-spoofing (FAS) is a key technique for securing face recognition systems, and it requires only static images as input. However, single-shot FAS remains a challenging and under-explored problem due to two main reasons: 1) on the data side, learning FAS from RGB images is largely context-dependent, and single-shot images without additional annotations contain limited semantic information. 2) on the model side, existing single-shot FAS models are infeasible to provide proper evidence for their decisions, and FAS methods based on depth estimation require expensive per-pixel annotations. To address these issues, a large binocular NIR image dataset (BNI-FAS) is constructed and published, which contains more than 300,000 real face and plane attack images, and an Interpretable FAS Transformer (IFAST) is proposed that requires only weak supervision to produce interpretable predictions. Our IFAST can produce pixel-wise disparity maps by the proposed disparity estimation Transformer with Dynamic Matching Attention (DMA) block. Besides, a well-designed confidence map generator is adopted to cooperate with the proposed dual-teacher distillation module to obtain the final discriminant results. The comprehensive experiments show that our IFAST can achieve state-of-the-art results on BNI-FAS, proving the effectiveness of the single-shot FAS based on binocular NIR images.
Fewshot learning on global multimodal embeddings for earth observation tasks
Sep 29, 2023In this work we pretrain a CLIP/ViT based model using three different modalities of satellite imagery across five AOIs covering over ~10\% of the earth total landmass, namely Sentinel 2 RGB optical imagery, Sentinel 1 SAR amplitude and Sentinel 1 SAR interferometric coherence. This model uses $\sim 250$ M parameters. Then, we use the embeddings produced for each modality with a classical machine learning method to attempt different downstream tasks for earth observation related to vegetation, built up surface, croplands and permanent water. We consistently show how we reduce the need for labeled data by 99\%, so that with ~200-500 randomly selected labeled examples (around 4K-10K km$^2$) we reach performance levels analogous to those achieved with the full labeled datasets (about 150K image chips or 3M km$^2$ in each AOI) on all modalities, AOIs and downstream tasks. This leads us to think that the model has captured significant earth features useful in a wide variety of scenarios. To enhance our model's usability in practice, its architecture allows inference in contexts with missing modalities and even missing channels within each modality. Additionally, we visually show that this embedding space, obtained with no labels, is sensible to the different earth features represented by the labelled datasets we selected.
SAM3D: Segment Anything Model in Volumetric Medical Images
Sep 07, 2023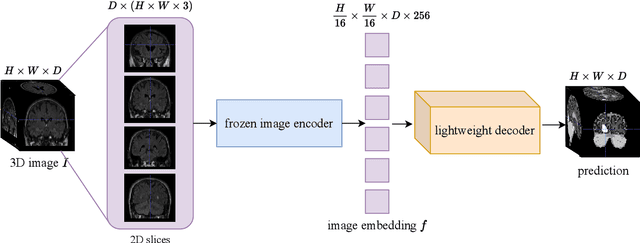
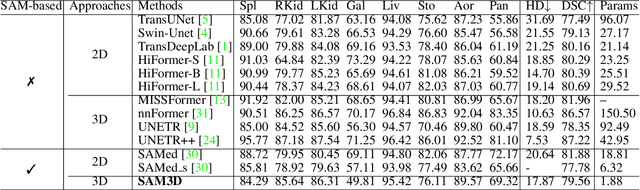
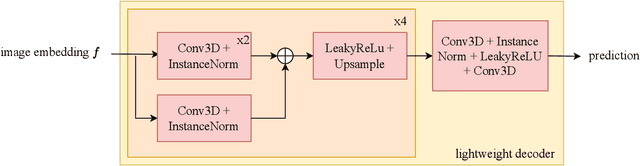
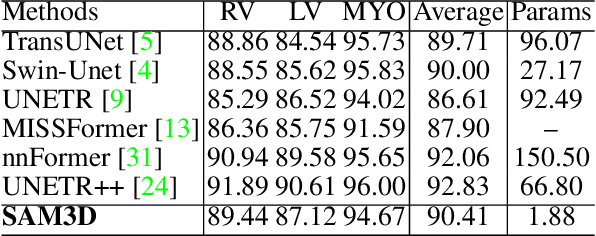
Image segmentation is a critical task in medical image analysis, providing valuable information that helps to make an accurate diagnosis. In recent years, deep learning-based automatic image segmentation methods have achieved outstanding results in medical images. In this paper, inspired by the Segment Anything Model (SAM), a foundation model that has received much attention for its impressive accuracy and powerful generalization ability in 2D still image segmentation, we propose a SAM3D that targets at 3D volumetric medical images and utilizes the pre-trained features from the SAM encoder to capture meaningful representations of input images. Different from other existing SAM-based volumetric segmentation methods that perform the segmentation by dividing the volume into a set of 2D slices, our model takes the whole 3D volume image as input and processes it simply and effectively that avoids training a significant number of parameters. Extensive experiments are conducted on multiple medical image datasets to demonstrate that our network attains competitive results compared with other state-of-the-art methods in 3D medical segmentation tasks while being significantly efficient in terms of parameters.
EqGAN: Feature Equalization Fusion for Few-shot Image Generation
Jul 27, 2023Due to the absence of fine structure and texture information, existing fusion-based few-shot image generation methods suffer from unsatisfactory generation quality and diversity. To address this problem, we propose a novel feature Equalization fusion Generative Adversarial Network (EqGAN) for few-shot image generation. Unlike existing fusion strategies that rely on either deep features or local representations, we design two separate branches to fuse structures and textures by disentangling encoded features into shallow and deep contents. To refine image contents at all feature levels, we equalize the fused structure and texture semantics at different scales and supplement the decoder with richer information by skip connections. Since the fused structures and textures may be inconsistent with each other, we devise a consistent equalization loss between the equalized features and the intermediate output of the decoder to further align the semantics. Comprehensive experiments on three public datasets demonstrate that, EqGAN not only significantly improves generation performance with FID score (by up to 32.7%) and LPIPS score (by up to 4.19%), but also outperforms the state-of-the-arts in terms of accuracy (by up to 1.97%) for downstream classification tasks.
Light Field Diffusion for Single-View Novel View Synthesis
Sep 20, 2023Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
NineRec: A Benchmark Dataset Suite for Evaluating Transferable Recommendation
Sep 20, 2023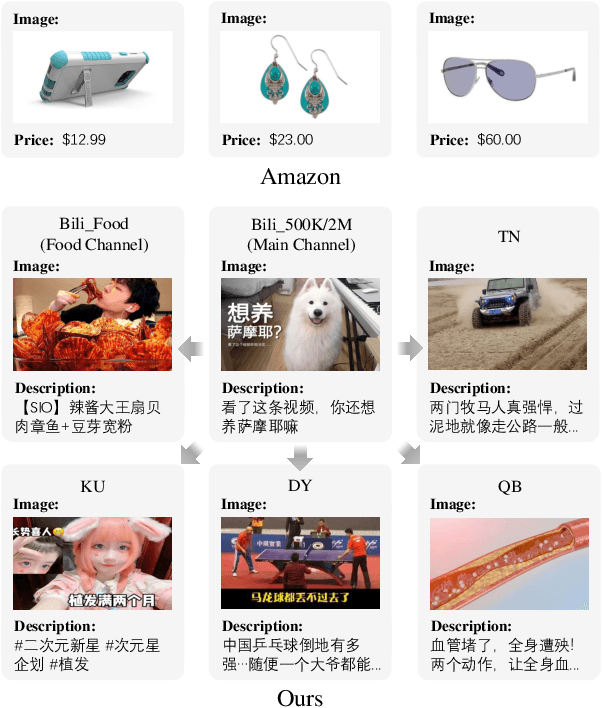
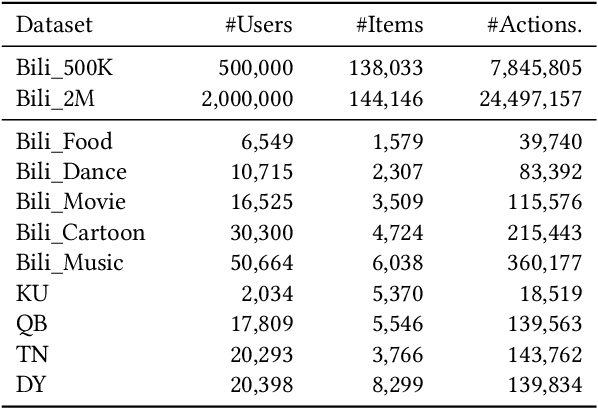
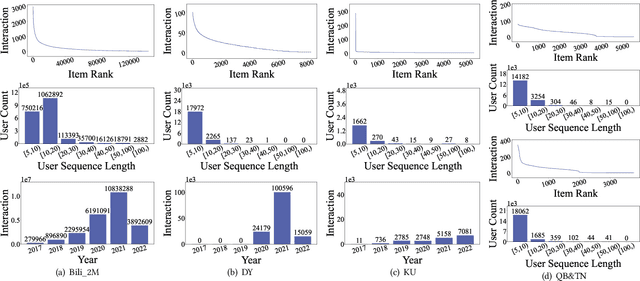
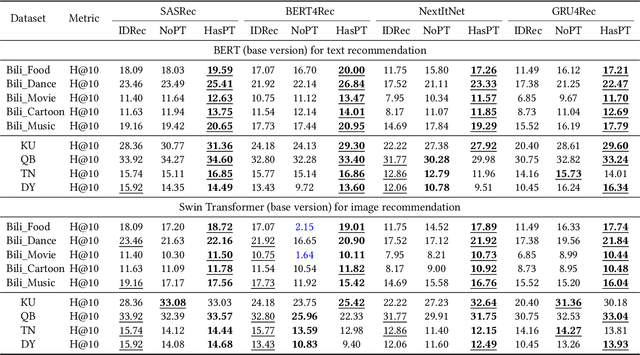
Learning a recommender system model from an item's raw modality features (such as image, text, audio, etc.), called MoRec, has attracted growing interest recently. One key advantage of MoRec is that it can easily benefit from advances in other fields, such as natural language processing (NLP) and computer vision (CV). Moreover, it naturally supports transfer learning across different systems through modality features, known as transferable recommender systems, or TransRec. However, so far, TransRec has made little progress, compared to groundbreaking foundation models in the fields of NLP and CV. The lack of large-scale, high-quality recommendation datasets poses a major obstacle. To this end, we introduce NineRec, a TransRec dataset suite that includes a large-scale source domain recommendation dataset and nine diverse target domain recommendation datasets. Each item in NineRec is represented by a text description and a high-resolution cover image. With NineRec, we can implement TransRec models in an end-to-end training manner instead of using pre-extracted invariant features. We conduct a benchmark study and empirical analysis of TransRec using NineRec, and our findings provide several valuable insights. To support further research, we make our code, datasets, benchmarks, and leaderboards publicly available at https://github.com/westlake-repl/NineRec.
Source-free Active Domain Adaptation for Diabetic Retinopathy Grading Based on Ultra-wide-field Fundus Image
Sep 19, 2023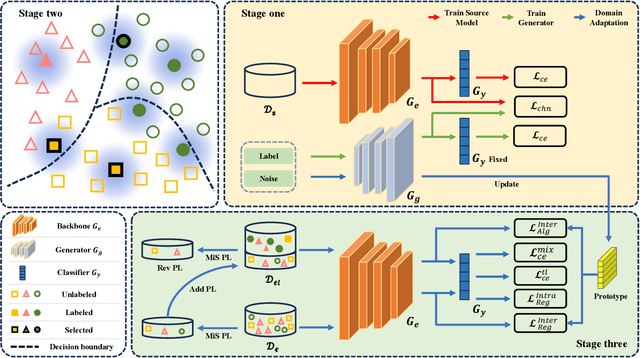
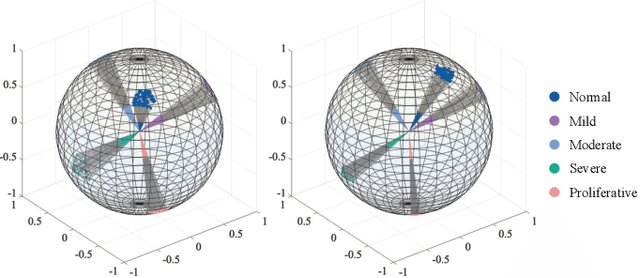
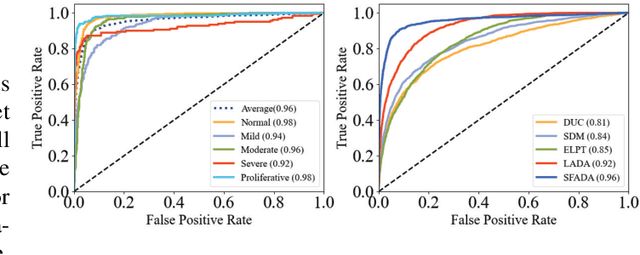
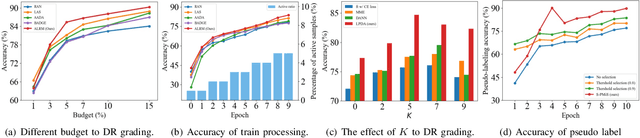
Domain adaptation (DA) has been widely applied in the diabetic retinopathy (DR) grading of unannotated ultra-wide-field (UWF) fundus images, which can transfer annotated knowledge from labeled color fundus images. However, suffering from huge domain gaps and complex real-world scenarios, the DR grading performance of most mainstream DA is far from that of clinical diagnosis. To tackle this, we propose a novel source-free active domain adaptation (SFADA) in this paper. Specifically, we focus on DR grading problem itself and propose to generate features of color fundus images with continuously evolving relationships of DRs, actively select a few valuable UWF fundus images for labeling with local representation matching, and adapt model on UWF fundus images with DR lesion prototypes. Notably, the SFADA also takes data privacy and computational efficiency into consideration. Extensive experimental results demonstrate that our proposed SFADA achieves state-of-the-art DR grading performance, increasing accuracy by 20.9% and quadratic weighted kappa by 18.63% compared with baseline and reaching 85.36% and 92.38% respectively. These investigations show that the potential of our approach for real clinical practice is promising.
Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs
Oct 01, 2023Multi-modal Large Language Models (MLLMs) have shown remarkable capabilities in many vision-language tasks. Nevertheless, most MLLMs still lack the Referential Comprehension (RC) ability to identify a specific object or area in images, limiting their application in fine-grained perception tasks. This paper proposes a novel method to enhance the RC capability for MLLMs. Our model represents the referring object in the image using the coordinates of its bounding box and converts the coordinates into texts in a specific format. This allows the model to treat the coordinates as natural language. Moreover, we construct the instruction tuning dataset with various designed RC tasks at a low cost by unleashing the potential of annotations in existing datasets. To further boost the RC ability of the model, we propose a self-consistent bootstrapping method that extends dense object annotations of a dataset into high-quality referring-expression-bounding-box pairs. The model is trained end-to-end with a parameter-efficient tuning framework that allows both modalities to benefit from multi-modal instruction tuning. This framework requires fewer trainable parameters and less training data. Experimental results on conventional vision-language and RC tasks demonstrate the superior performance of our method. For instance, our model exhibits a 12.0% absolute accuracy improvement over Instruct-BLIP on VSR and surpasses Kosmos-2 by 24.7% on RefCOCO_val under zero-shot settings. We also attain the top position on the leaderboard of MMBench. The models, datasets, and codes are publicly available at https://github.com/SY-Xuan/Pink