 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing
Oct 09, 2023

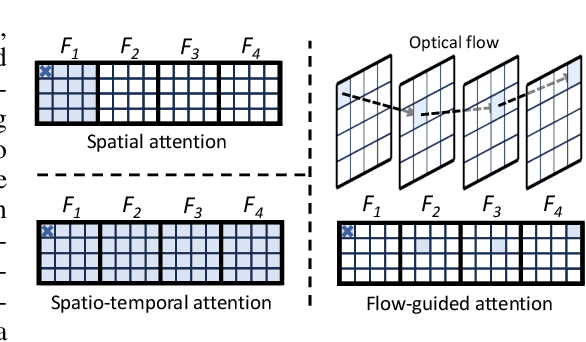


Text-to-video editing aims to edit the visual appearance of a source video conditional on textual prompts. A major challenge in this task is to ensure that all frames in the edited video are visually consistent. Most recent works apply advanced text-to-image diffusion models to this task by inflating 2D spatial attention in the U-Net into spatio-temporal attention. Although temporal context can be added through spatio-temporal attention, it may introduce some irrelevant information for each patch and therefore cause inconsistency in the edited video. In this paper, for the first time, we introduce optical flow into the attention module in the diffusion model's U-Net to address the inconsistency issue for text-to-video editing. Our method, FLATTEN, enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency in the edited videos. Additionally, our method is training-free and can be seamlessly integrated into any diffusion-based text-to-video editing methods and improve their visual consistency. Experiment results on existing text-to-video editing benchmarks show that our proposed method achieves the new state-of-the-art performance. In particular, our method excels in maintaining the visual consistency in the edited videos.
Latent Diffusion Model for DNA Sequence Generation
Oct 09, 2023The harnessing of machine learning, especially deep generative models, has opened up promising avenues in the field of synthetic DNA sequence generation. Whilst Generative Adversarial Networks (GANs) have gained traction for this application, they often face issues such as limited sample diversity and mode collapse. On the other hand, Diffusion Models are a promising new class of generative models that are not burdened with these problems, enabling them to reach the state-of-the-art in domains such as image generation. In light of this, we propose a novel latent diffusion model, DiscDiff, tailored for discrete DNA sequence generation. By simply embedding discrete DNA sequences into a continuous latent space using an autoencoder, we are able to leverage the powerful generative abilities of continuous diffusion models for the generation of discrete data. Additionally, we introduce Fr\'echet Reconstruction Distance (FReD) as a new metric to measure the sample quality of DNA sequence generations. Our DiscDiff model demonstrates an ability to generate synthetic DNA sequences that align closely with real DNA in terms of Motif Distribution, Latent Embedding Distribution (FReD), and Chromatin Profiles. Additionally, we contribute a comprehensive cross-species dataset of 150K unique promoter-gene sequences from 15 species, enriching resources for future generative modelling in genomics. We will make our code public upon publication.
Transformer Fusion with Optimal Transport
Oct 09, 2023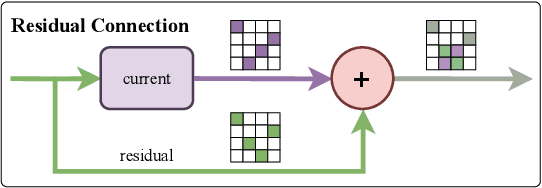
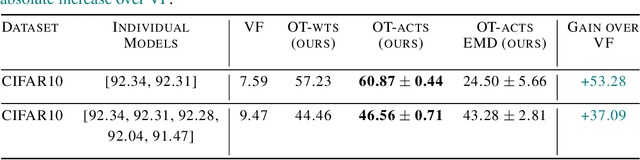
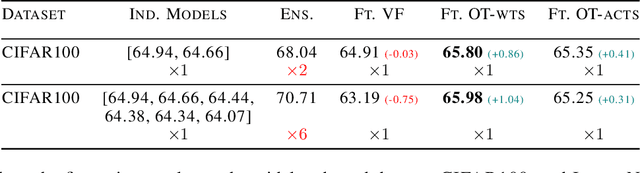
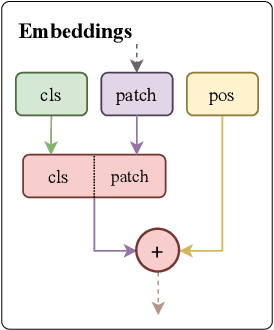
Fusion is a technique for merging multiple independently-trained neural networks in order to combine their capabilities. Past attempts have been restricted to the case of fully-connected, convolutional, and residual networks. In this paper, we present a systematic approach for fusing two or more transformer-based networks exploiting Optimal Transport to (soft-)align the various architectural components. We flesh out an abstraction for layer alignment, that can generalize to arbitrary architectures -- in principle -- and we apply this to the key ingredients of Transformers such as multi-head self-attention, layer-normalization, and residual connections, and we discuss how to handle them via various ablation studies. Furthermore, our method allows the fusion of models of different sizes (heterogeneous fusion), providing a new and efficient way for compression of Transformers. The proposed approach is evaluated on both image classification tasks via Vision Transformer and natural language modeling tasks using BERT. Our approach consistently outperforms vanilla fusion, and, after a surprisingly short finetuning, also outperforms the individual converged parent models. In our analysis, we uncover intriguing insights about the significant role of soft alignment in the case of Transformers. Our results showcase the potential of fusing multiple Transformers, thus compounding their expertise, in the budding paradigm of model fusion and recombination.
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
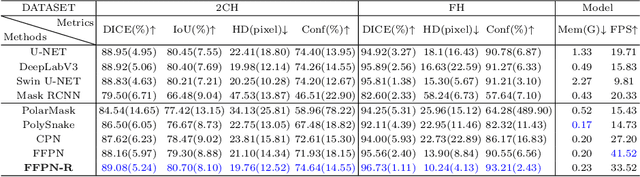
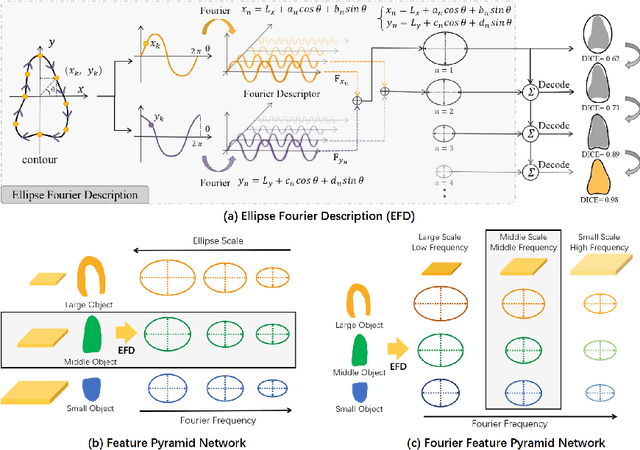
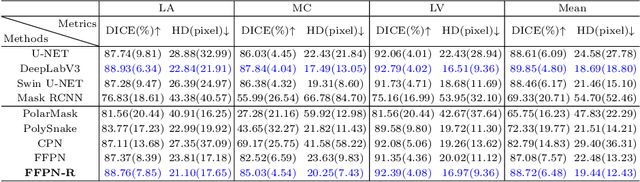
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
Compositional Servoing by Recombining Demonstrations
Oct 06, 2023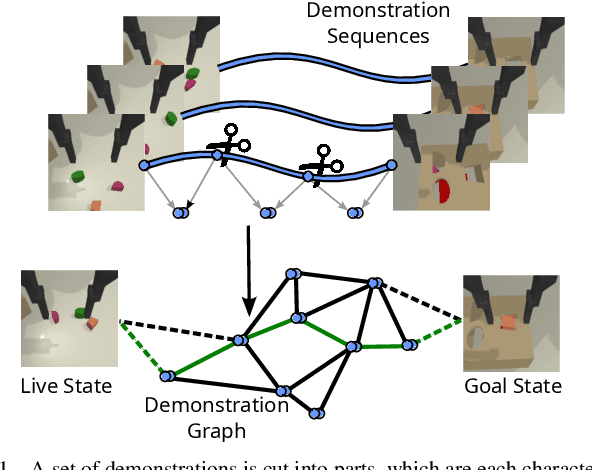
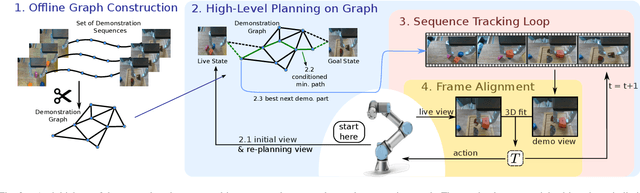
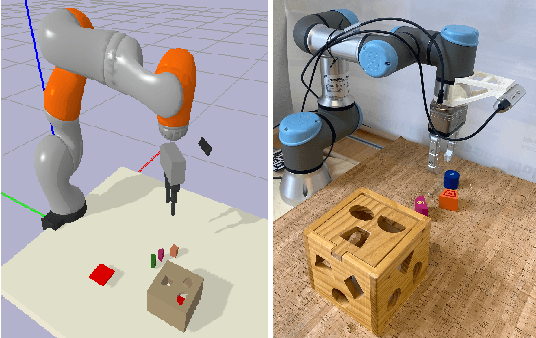
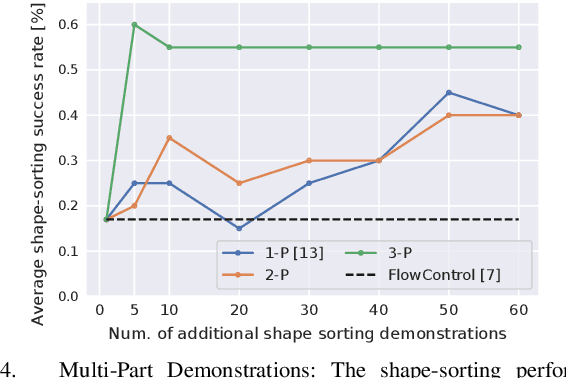
Learning-based manipulation policies from image inputs often show weak task transfer capabilities. In contrast, visual servoing methods allow efficient task transfer in high-precision scenarios while requiring only a few demonstrations. In this work, we present a framework that formulates the visual servoing task as graph traversal. Our method not only extends the robustness of visual servoing, but also enables multitask capability based on a few task-specific demonstrations. We construct demonstration graphs by splitting existing demonstrations and recombining them. In order to traverse the demonstration graph in the inference case, we utilize a similarity function that helps select the best demonstration for a specific task. This enables us to compute the shortest path through the graph. Ultimately, we show that recombining demonstrations leads to higher task-respective success. We present extensive simulation and real-world experimental results that demonstrate the efficacy of our approach.
Envisioning Narrative Intelligence: A Creative Visual Storytelling Anthology
Oct 06, 2023In this paper, we collect an anthology of 100 visual stories from authors who participated in our systematic creative process of improvised story-building based on image sequences. Following close reading and thematic analysis of our anthology, we present five themes that characterize the variations found in this creative visual storytelling process: (1) Narrating What is in Vision vs. Envisioning; (2) Dynamically Characterizing Entities/Objects; (3) Sensing Experiential Information About the Scenery; (4) Modulating the Mood; (5) Encoding Narrative Biases. In understanding the varied ways that people derive stories from images, we offer considerations for collecting story-driven training data to inform automatic story generation. In correspondence with each theme, we envision narrative intelligence criteria for computational visual storytelling as: creative, reliable, expressive, grounded, and responsible. From these criteria, we discuss how to foreground creative expression, account for biases, and operate in the bounds of visual storyworlds.
* 21 pages, 11 figures
Improving Equivariance in State-of-the-Art Supervised Depth and Normal Predictors
Sep 28, 2023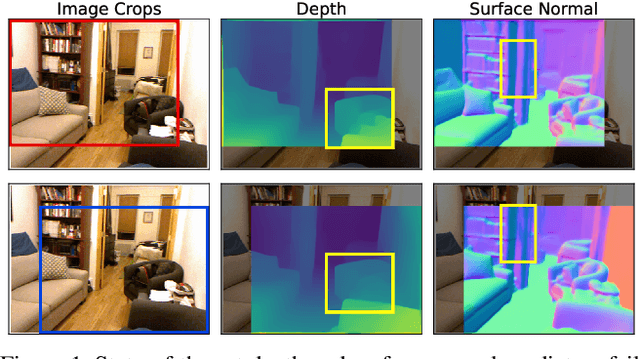


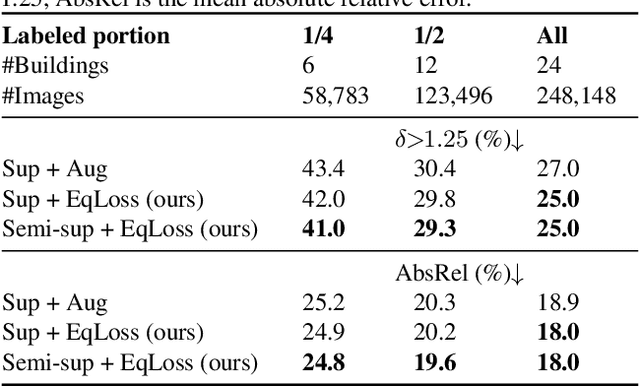
Dense depth and surface normal predictors should possess the equivariant property to cropping-and-resizing -- cropping the input image should result in cropping the same output image. However, we find that state-of-the-art depth and normal predictors, despite having strong performances, surprisingly do not respect equivariance. The problem exists even when crop-and-resize data augmentation is employed during training. To remedy this, we propose an equivariant regularization technique, consisting of an averaging procedure and a self-consistency loss, to explicitly promote cropping-and-resizing equivariance in depth and normal networks. Our approach can be applied to both CNN and Transformer architectures, does not incur extra cost during testing, and notably improves the supervised and semi-supervised learning performance of dense predictors on Taskonomy tasks. Finally, finetuning with our loss on unlabeled images improves not only equivariance but also accuracy of state-of-the-art depth and normal predictors when evaluated on NYU-v2. GitHub link: https://github.com/mikuhatsune/equivariance
One For All: Video Conversation is Feasible Without Video Instruction Tuning
Sep 27, 2023The recent progress in Large Language Models (LLM) has spurred various advancements in image-language conversation agents, while how to build a proficient video-based dialogue system is still under exploration. Considering the extensive scale of LLM and visual backbone, minimal GPU memory is left for facilitating effective temporal modeling, which is crucial for comprehending and providing feedback on videos. To this end, we propose Branching Temporal Adapter (BT-Adapter), a novel method for extending image-language pretrained models into the video domain. Specifically, BT-Adapter serves as a plug-and-use temporal modeling branch alongside the pretrained visual encoder, which is tuned while keeping the backbone frozen. Just pretrained once, BT-Adapter can be seamlessly integrated into all image conversation models using this version of CLIP, enabling video conversations without the need for video instructions. Besides, we develop a unique asymmetric token masking strategy inside the branch with tailor-made training tasks for BT-Adapter, facilitating faster convergence and better results. Thanks to BT-Adapter, we are able to empower existing multimodal dialogue models with strong video understanding capabilities without incurring excessive GPU costs. Without bells and whistles, BT-Adapter achieves (1) state-of-the-art zero-shot results on various video tasks using thousands of fewer GPU hours. (2) better performance than current video chatbots without any video instruction tuning. (3) state-of-the-art results of video chatting using video instruction tuning, outperforming previous SOTAs by a large margin.
Style Transfer and Self-Supervised Learning Powered Myocardium Infarction Super-Resolution Segmentation
Sep 27, 2023
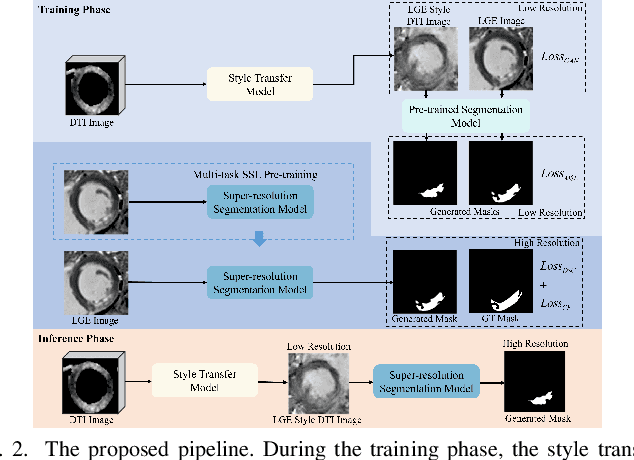
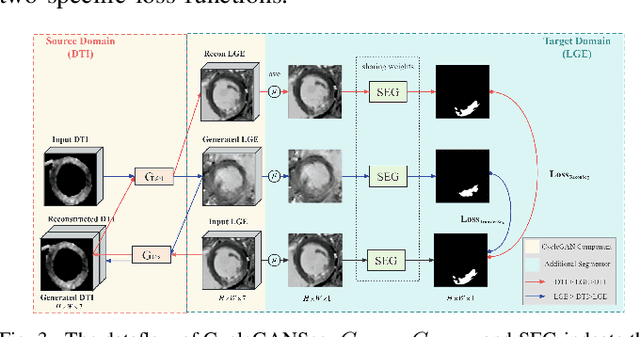
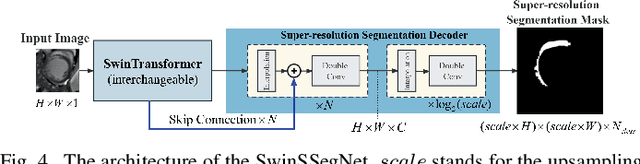
This study proposes a pipeline that incorporates a novel style transfer model and a simultaneous super-resolution and segmentation model. The proposed pipeline aims to enhance diffusion tensor imaging (DTI) images by translating them into the late gadolinium enhancement (LGE) domain, which offers a larger amount of data with high-resolution and distinct highlighting of myocardium infarction (MI) areas. Subsequently, the segmentation task is performed on the LGE style image. An end-to-end super-resolution segmentation model is introduced to generate high-resolution mask from low-resolution LGE style DTI image. Further, to enhance the performance of the model, a multi-task self-supervised learning strategy is employed to pre-train the super-resolution segmentation model, allowing it to acquire more representative knowledge and improve its segmentation performance after fine-tuning. https: github.com/wlc2424762917/Med_Img
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023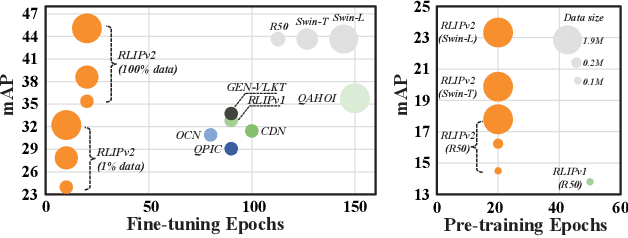
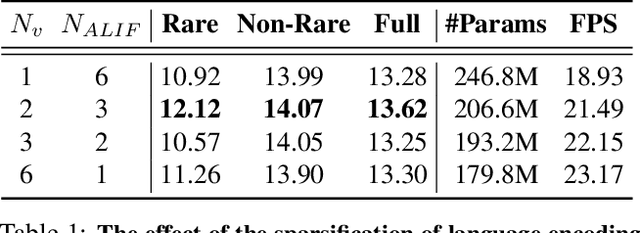
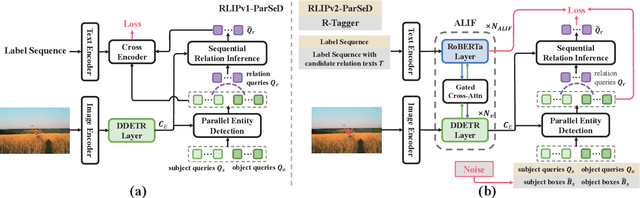
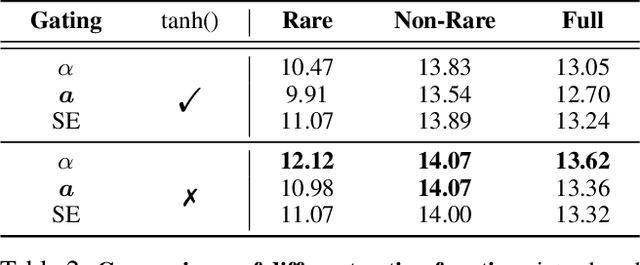
Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.