 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Decision-based Black-box Attacks on Face Forgery Detection
Oct 18, 2023
Face forgery generation technologies generate vivid faces, which have raised public concerns about security and privacy. Many intelligent systems, such as electronic payment and identity verification, rely on face forgery detection. Although face forgery detection has successfully distinguished fake faces, recent studies have demonstrated that face forgery detectors are very vulnerable to adversarial examples. Meanwhile, existing attacks rely on network architectures or training datasets instead of the predicted labels, which leads to a gap in attacking deployed applications. To narrow this gap, we first explore the decision-based attacks on face forgery detection. However, applying existing decision-based attacks directly suffers from perturbation initialization failure and low image quality. First, we propose cross-task perturbation to handle initialization failures by utilizing the high correlation of face features on different tasks. Then, inspired by using frequency cues by face forgery detection, we propose the frequency decision-based attack. We add perturbations in the frequency domain and then constrain the visual quality in the spatial domain. Finally, extensive experiments demonstrate that our method achieves state-of-the-art attack performance on FaceForensics++, CelebDF, and industrial APIs, with high query efficiency and guaranteed image quality. Further, the fake faces by our method can pass face forgery detection and face recognition, which exposes the security problems of face forgery detectors.
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Sep 12, 2023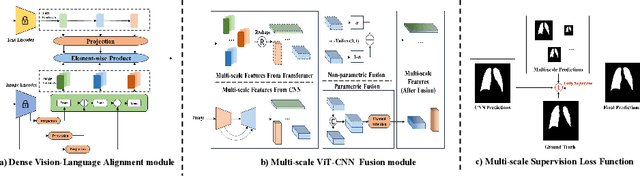
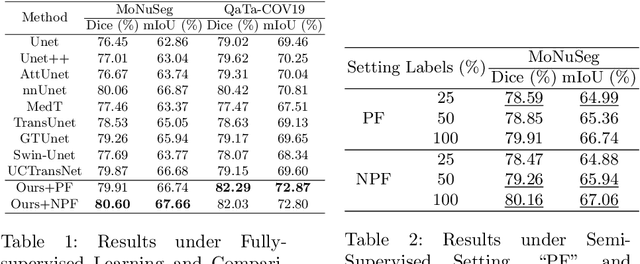
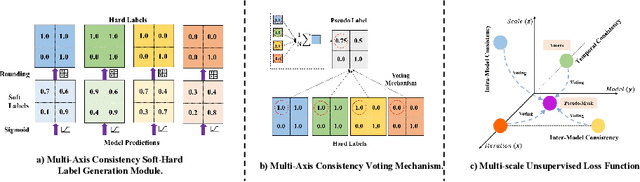
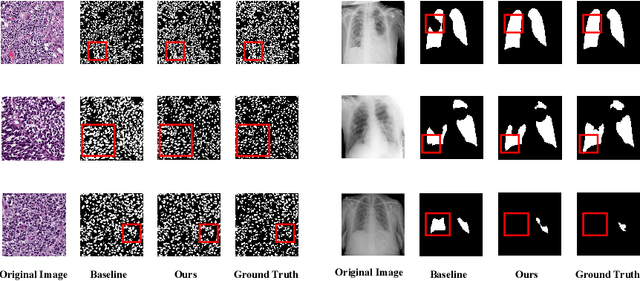
In this paper, we introduce a novel semi-supervised learning framework tailored for medical image segmentation. Central to our approach is the innovative Multi-scale Text-aware ViT-CNN Fusion scheme. This scheme adeptly combines the strengths of both ViTs and CNNs, capitalizing on the unique advantages of both architectures as well as the complementary information in vision-language modalities. Further enriching our framework, we propose the Multi-Axis Consistency framework for generating robust pseudo labels, thereby enhancing the semi-supervised learning process. Our extensive experiments on several widely-used datasets unequivocally demonstrate the efficacy of our approach.
Gene-induced Multimodal Pre-training for Image-omic Classification
Sep 06, 2023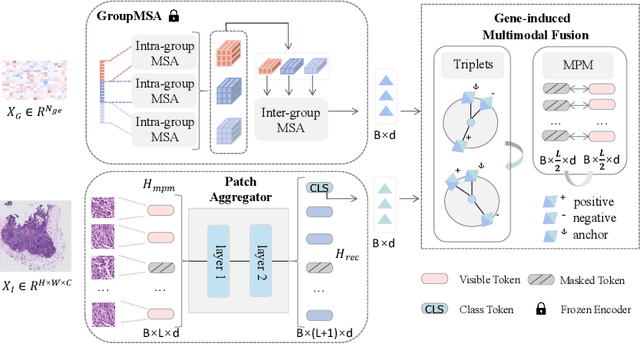
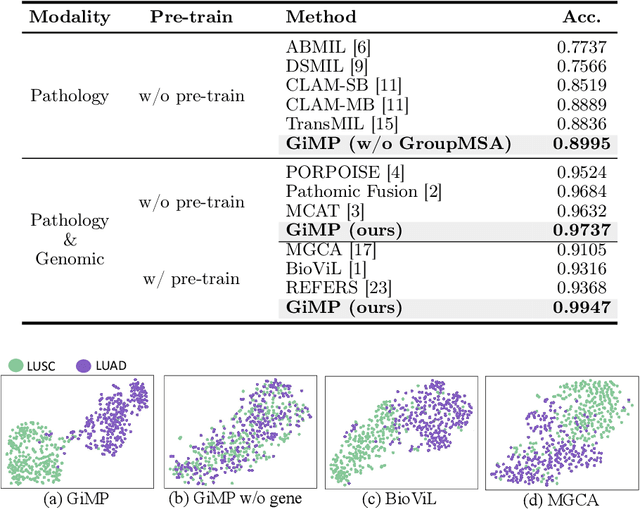
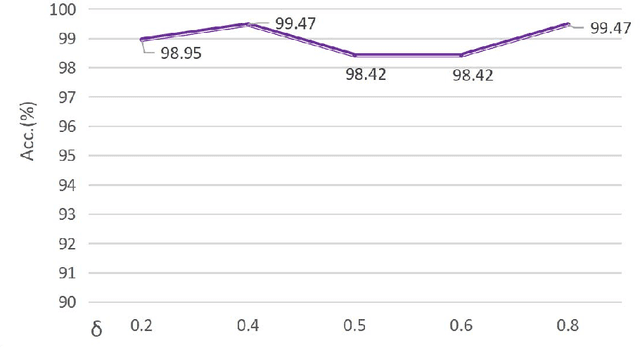
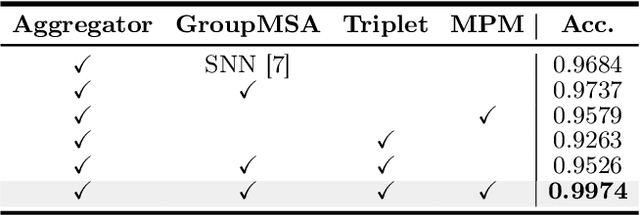
Histology analysis of the tumor micro-environment integrated with genomic assays is the gold standard for most cancers in modern medicine. This paper proposes a Gene-induced Multimodal Pre-training (GiMP) framework, which jointly incorporates genomics and Whole Slide Images (WSIs) for classification tasks. Our work aims at dealing with the main challenges of multi-modality image-omic classification w.r.t. (1) the patient-level feature extraction difficulties from gigapixel WSIs and tens of thousands of genes, and (2) effective fusion considering high-order relevance modeling. Concretely, we first propose a group multi-head self-attention gene encoder to capture global structured features in gene expression cohorts. We design a masked patch modeling paradigm (MPM) to capture the latent pathological characteristics of different tissues. The mask strategy is randomly masking a fixed-length contiguous subsequence of patch embeddings of a WSI. Finally, we combine the classification tokens of paired modalities and propose a triplet learning module to learn high-order relevance and discriminative patient-level information.After pre-training, a simple fine-tuning can be adopted to obtain the classification results. Experimental results on the TCGA dataset show the superiority of our network architectures and our pre-training framework, achieving 99.47% in accuracy for image-omic classification. The code is publicly available at https://github.com/huangwudiduan/GIMP.
LightSpeed: Light and Fast Neural Light Fields on Mobile Devices
Oct 25, 2023Real-time novel-view image synthesis on mobile devices is prohibitive due to the limited computational power and storage. Using volumetric rendering methods, such as NeRF and its derivatives, on mobile devices is not suitable due to the high computational cost of volumetric rendering. On the other hand, recent advances in neural light field representations have shown promising real-time view synthesis results on mobile devices. Neural light field methods learn a direct mapping from a ray representation to the pixel color. The current choice of ray representation is either stratified ray sampling or Pl\"{u}cker coordinates, overlooking the classic light slab (two-plane) representation, the preferred representation to interpolate between light field views. In this work, we find that using the light slab representation is an efficient representation for learning a neural light field. More importantly, it is a lower-dimensional ray representation enabling us to learn the 4D ray space using feature grids which are significantly faster to train and render. Although mostly designed for frontal views, we show that the light-slab representation can be further extended to non-frontal scenes using a divide-and-conquer strategy. Our method offers superior rendering quality compared to previous light field methods and achieves a significantly improved trade-off between rendering quality and speed.
* Project Page: http://lightspeed-r2l.github.io/website/
Metrically Scaled Monocular Depth Estimation through Sparse Priors for Underwater Robots
Oct 25, 2023In this work, we address the problem of real-time dense depth estimation from monocular images for mobile underwater vehicles. We formulate a deep learning model that fuses sparse depth measurements from triangulated features to improve the depth predictions and solve the problem of scale ambiguity. To allow prior inputs of arbitrary sparsity, we apply a dense parameterization method. Our model extends recent state-of-the-art approaches to monocular image based depth estimation, using an efficient encoder-decoder backbone and modern lightweight transformer optimization stage to encode global context. The network is trained in a supervised fashion on the forward-looking underwater dataset, FLSea. Evaluation results on this dataset demonstrate significant improvement in depth prediction accuracy by the fusion of the sparse feature priors. In addition, without any retraining, our method achieves similar depth prediction accuracy on a downward looking dataset we collected with a diver operated camera rig, conducting a survey of a coral reef. The method achieves real-time performance, running at 160 FPS on a laptop GPU and 7 FPS on a single CPU core and is suitable for direct deployment on embedded systems. The implementation of this work is made publicly available at https://github.com/ebnerluca/uw_depth.
An Early Evaluation of GPT-4V(ision)
Oct 25, 2023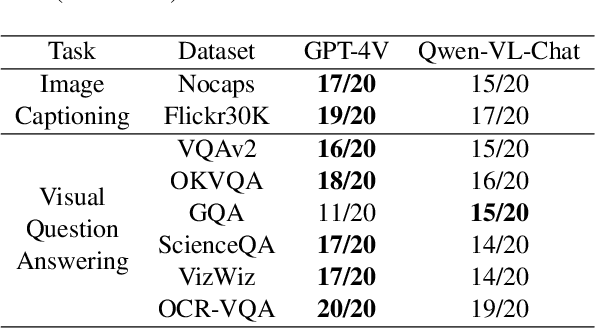

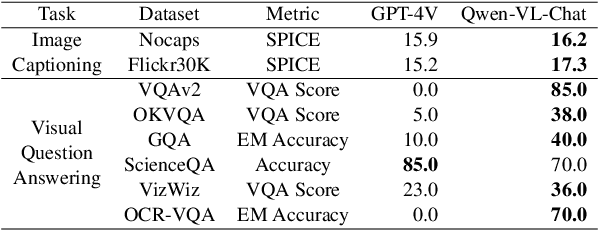

In this paper, we evaluate different abilities of GPT-4V including visual understanding, language understanding, visual puzzle solving, and understanding of other modalities such as depth, thermal, video, and audio. To estimate GPT-4V's performance, we manually construct 656 test instances and carefully evaluate the results of GPT-4V. The highlights of our findings are as follows: (1) GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images; (2) GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age; (3) GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks; (4) Few-shot prompting can improve GPT-4V's performance on both visual understanding and language understanding; (5) GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles; (6) GPT-4V shows non-trivial performance on the tasks of similar modalities to image, such as video and thermal. Our experimental results reveal the ability and limitations of GPT-4V and we hope our paper can provide some insights into the application and research of GPT-4V.
Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization
Aug 28, 2023
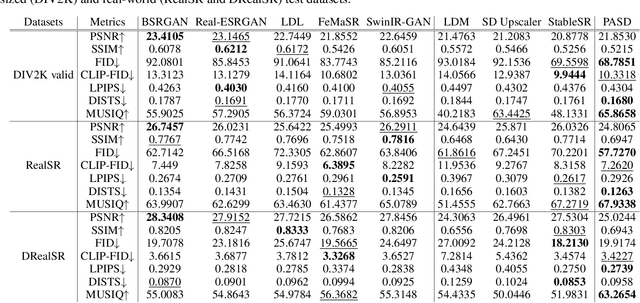
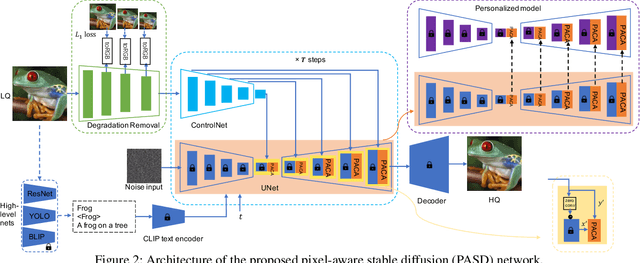
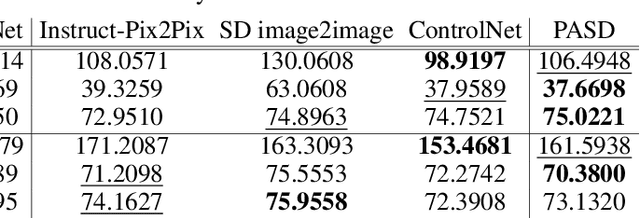
Realistic image super-resolution (Real-ISR) aims to reproduce perceptually realistic image details from a low-quality input. The commonly used adversarial training based Real-ISR methods often introduce unnatural visual artifacts and fail to generate realistic textures for natural scene images. The recently developed generative stable diffusion models provide a potential solution to Real-ISR with pre-learned strong image priors. However, the existing methods along this line either fail to keep faithful pixel-wise image structures or resort to extra skipped connections to reproduce details, which requires additional training in image space and limits their extension to other related tasks in latent space such as image stylization. In this work, we propose a pixel-aware stable diffusion (PASD) network to achieve robust Real-ISR as well as personalized stylization. In specific, a pixel-aware cross attention module is introduced to enable diffusion models perceiving image local structures in pixel-wise level, while a degradation removal module is used to extract degradation insensitive features to guide the diffusion process together with image high level information. By simply replacing the base diffusion model with a personalized one, our method can generate diverse stylized images without the need to collect pairwise training data. PASD can be easily integrated into existing diffusion models such as Stable Diffusion. Experiments on Real-ISR and personalized stylization demonstrate the effectiveness of our proposed approach. The source code and models can be found at \url{https://github.com/yangxy/PASD}.
Symmetrical Linguistic Feature Distillation with CLIP for Scene Text Recognition
Oct 10, 2023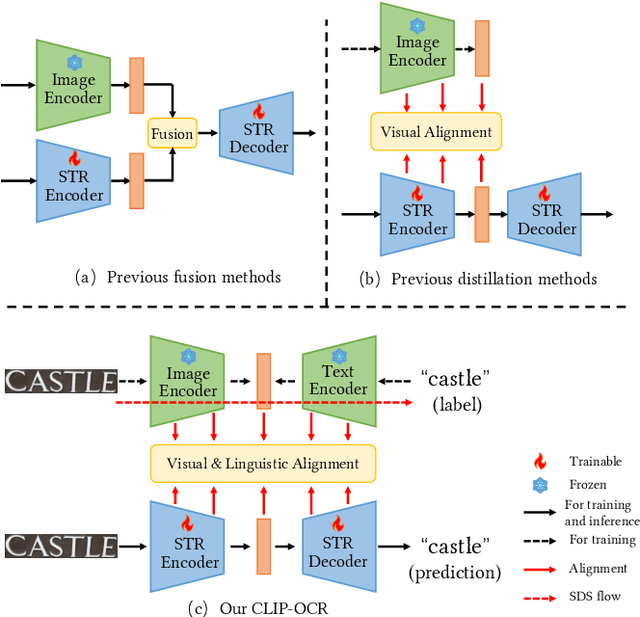
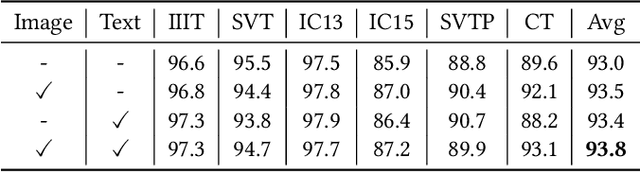

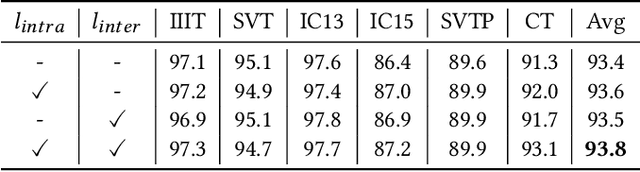
In this paper, we explore the potential of the Contrastive Language-Image Pretraining (CLIP) model in scene text recognition (STR), and establish a novel Symmetrical Linguistic Feature Distillation framework (named CLIP-OCR) to leverage both visual and linguistic knowledge in CLIP. Different from previous CLIP-based methods mainly considering feature generalization on visual encoding, we propose a symmetrical distillation strategy (SDS) that further captures the linguistic knowledge in the CLIP text encoder. By cascading the CLIP image encoder with the reversed CLIP text encoder, a symmetrical structure is built with an image-to-text feature flow that covers not only visual but also linguistic information for distillation.Benefiting from the natural alignment in CLIP, such guidance flow provides a progressive optimization objective from vision to language, which can supervise the STR feature forwarding process layer-by-layer.Besides, a new Linguistic Consistency Loss (LCL) is proposed to enhance the linguistic capability by considering second-order statistics during the optimization. Overall, CLIP-OCR is the first to design a smooth transition between image and text for the STR task.Extensive experiments demonstrate the effectiveness of CLIP-OCR with 93.8% average accuracy on six popular STR benchmarks.Code will be available at https://github.com/wzx99/CLIPOCR.
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Oct 19, 2023This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Oct 13, 2023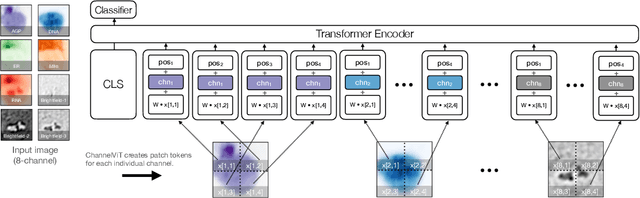
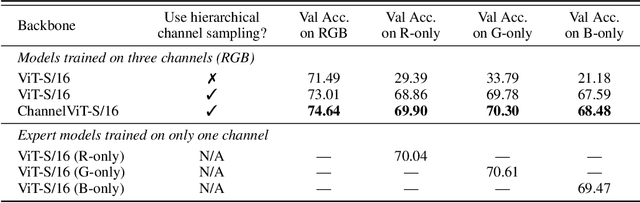
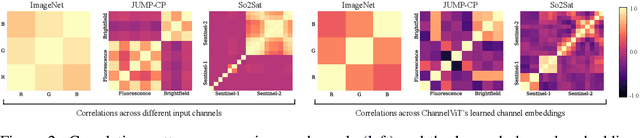
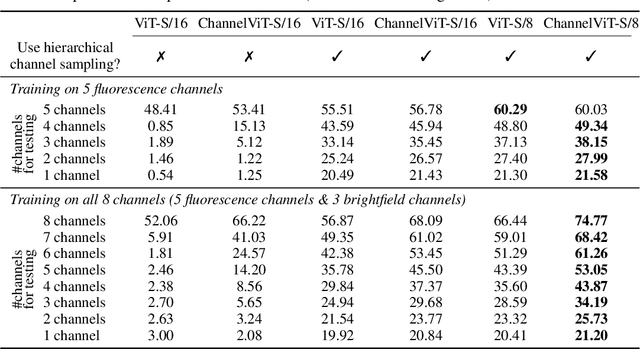
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.