 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can Protective Perturbation Safeguard Personal Data from Being Exploited by Stable Diffusion?
Nov 30, 2023
Stable Diffusion has established itself as a foundation model in generative AI artistic applications, receiving widespread research and application. Some recent fine-tuning methods have made it feasible for individuals to implant personalized concepts onto the basic Stable Diffusion model with minimal computational costs on small datasets. However, these innovations have also given rise to issues like facial privacy forgery and artistic copyright infringement. In recent studies, researchers have explored the addition of imperceptible adversarial perturbations to images to prevent potential unauthorized exploitation and infringements when personal data is used for fine-tuning Stable Diffusion. Although these studies have demonstrated the ability to protect images, it is essential to consider that these methods may not be entirely applicable in real-world scenarios. In this paper, we systematically evaluate the use of perturbations to protect images within a practical threat model. The results suggest that these approaches may not be sufficient to safeguard image privacy and copyright effectively. Furthermore, we introduce a purification method capable of removing protected perturbations while preserving the original image structure to the greatest extent possible. Experiments reveal that Stable Diffusion can effectively learn from purified images over all protective methods.
PCDP-SGD: Improving the Convergence of Differentially Private SGD via Projection in Advance
Dec 06, 2023The paradigm of Differentially Private SGD~(DP-SGD) can provide a theoretical guarantee for training data in both centralized and federated settings. However, the utility degradation caused by DP-SGD limits its wide application in high-stakes tasks, such as medical image diagnosis. In addition to the necessary perturbation, the convergence issue is attributed to the information loss on the gradient clipping. In this work, we propose a general framework PCDP-SGD, which aims to compress redundant gradient norms and preserve more crucial top gradient components via projection operation before gradient clipping. Additionally, we extend PCDP-SGD as a fundamental component in differential privacy federated learning~(DPFL) for mitigating the data heterogeneous challenge and achieving efficient communication. We prove that pre-projection enhances the convergence of DP-SGD by reducing the dependence of clipping error and bias to a fraction of the top gradient eigenspace, and in theory, limits cross-client variance to improve the convergence under heterogeneous federation. Experimental results demonstrate that PCDP-SGD achieves higher accuracy compared with state-of-the-art DP-SGD variants in computer vision tasks. Moreover, PCDP-SGD outperforms current federated learning frameworks when DP is guaranteed on local training sets.
AttriHuman-3D: Editable 3D Human Avatar Generation with Attribute Decomposition and Indexing
Dec 06, 2023Editable 3D-aware generation, which supports user-interacted editing, has witnessed rapid development recently. However, existing editable 3D GANs either fail to achieve high-accuracy local editing or suffer from huge computational costs. We propose AttriHuman-3D, an editable 3D human generation model, which address the aforementioned problems with attribute decomposition and indexing. The core idea of the proposed model is to generate all attributes (e.g. human body, hair, clothes and so on) in an overall attribute space with six feature planes, which are then decomposed and manipulated with different attribute indexes. To precisely extract features of different attributes from the generated feature planes, we propose a novel attribute indexing method as well as an orthogonal projection regularization to enhance the disentanglement. We also introduce a hyper-latent training strategy and an attribute-specific sampling strategy to avoid style entanglement and misleading punishment from the discriminator. Our method allows users to interactively edit selected attributes in the generated 3D human avatars while keeping others fixed. Both qualitative and quantitative experiments demonstrate that our model provides a strong disentanglement between different attributes, allows fine-grained image editing and generates high-quality 3D human avatars.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
Open-vocabulary object 6D pose estimation
Dec 01, 2023We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g. CAD or video sequence) is required at inference, (iii) the object is imaged from two different viewpoints of two different scenes, and (iv) the object was not observed during the training phase. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from two distinct scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 39 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. Project website: https://jcorsetti.github.io/oryon-website/.
Beyond First-Order Tweedie: Solving Inverse Problems using Latent Diffusion
Dec 01, 2023Sampling from the posterior distribution poses a major computational challenge in solving inverse problems using latent diffusion models. Common methods rely on Tweedie's first-order moments, which are known to induce a quality-limiting bias. Existing second-order approximations are impractical due to prohibitive computational costs, making standard reverse diffusion processes intractable for posterior sampling. This paper introduces Second-order Tweedie sampler from Surrogate Loss (STSL), a novel sampler that offers efficiency comparable to first-order Tweedie with a tractable reverse process using second-order approximation. Our theoretical results reveal that the second-order approximation is lower bounded by our surrogate loss that only requires $O(1)$ compute using the trace of the Hessian, and by the lower bound we derive a new drift term to make the reverse process tractable. Our method surpasses SoTA solvers PSLD and P2L, achieving 4X and 8X reduction in neural function evaluations, respectively, while notably enhancing sampling quality on FFHQ, ImageNet, and COCO benchmarks. In addition, we show STSL extends to text-guided image editing and addresses residual distortions present from corrupted images in leading text-guided image editing methods. To our best knowledge, this is the first work to offer an efficient second-order approximation in solving inverse problems using latent diffusion and editing real-world images with corruptions.
Tracking Object Positions in Reinforcement Learning: A Metric for Keypoint Detection (extended version)
Dec 01, 2023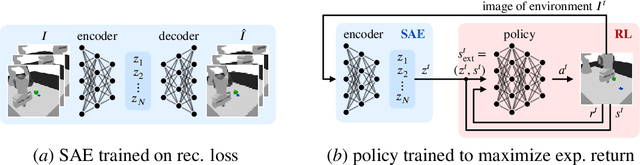

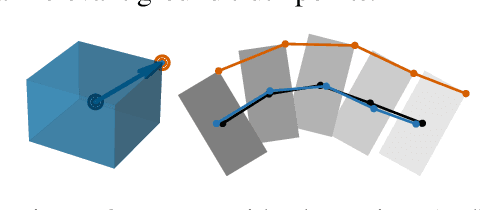

Reinforcement learning (RL) for robot control typically requires a detailed representation of the environment state, including information about task-relevant objects not directly measurable. Keypoint detectors, such as spatial autoencoders (SAEs), are a common approach to extracting a low-dimensional representation from high-dimensional image data. SAEs aim at spatial features such as object positions, which are often useful representations in robotic RL. However, whether an SAE is actually able to track objects in the scene and thus yields a spatial state representation well suited for RL tasks has rarely been examined due to a lack of established metrics. In this paper, we propose to assess the performance of an SAE instance by measuring how well keypoints track ground truth objects in images. We present a computationally lightweight metric and use it to evaluate common baseline SAE architectures on image data from a simulated robot task. We find that common SAEs differ substantially in their spatial extraction capability. Furthermore, we validate that SAEs that perform well in our metric achieve superior performance when used in downstream RL. Thus, our metric is an effective and lightweight indicator of RL performance before executing expensive RL training. Building on these insights, we identify three key modifications of SAE architectures to improve tracking performance. We make our code available at anonymous.4open.science/r/sae-rl.
Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Dec 01, 2023We pursue the goal of developing robots that can interact zero-shot with generic unseen objects via a diverse repertoire of manipulation skills and show how passive human videos can serve as a rich source of data for learning such generalist robots. Unlike typical robot learning approaches which directly learn how a robot should act from interaction data, we adopt a factorized approach that can leverage large-scale human videos to learn how a human would accomplish a desired task (a human plan), followed by translating this plan to the robots embodiment. Specifically, we learn a human plan predictor that, given a current image of a scene and a goal image, predicts the future hand and object configurations. We combine this with a translation module that learns a plan-conditioned robot manipulation policy, and allows following humans plans for generic manipulation tasks in a zero-shot manner with no deployment-time training. Importantly, while the plan predictor can leverage large-scale human videos for learning, the translation module only requires a small amount of in-domain data, and can generalize to tasks not seen during training. We show that our learned system can perform over 16 manipulation skills that generalize to 40 objects, encompassing 100 real-world tasks for table-top manipulation and diverse in-the-wild manipulation. https://homangab.github.io/hopman/
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Dec 01, 2023Text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models has shown great promise but still suffers from inconsistent 3D geometric structures (Janus problems) and severe artifacts. The aforementioned problems mainly stem from 2D diffusion models lacking 3D awareness during the lifting. In this work, we present GeoDream, a novel method that incorporates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. Specifically, we first utilize a multi-view diffusion model to generate posed images and then construct cost volume from the predicted image, which serves as native 3D geometric priors, ensuring spatial consistency in 3D space. Subsequently, we further propose to harness 3D geometric priors to unlock the great potential of 3D awareness in 2D diffusion priors via a disentangled design. Notably, disentangling 2D and 3D priors allows us to refine 3D geometric priors further. We justify that the refined 3D geometric priors aid in the 3D-aware capability of 2D diffusion priors, which in turn provides superior guidance for the refinement of 3D geometric priors. Our numerical and visual comparisons demonstrate that GeoDream generates more 3D consistent textured meshes with high-resolution realistic renderings (i.e., 1024 $\times$ 1024) and adheres more closely to semantic coherence.
Explaining CLIP's performance disparities on data from blind/low vision users
Dec 01, 2023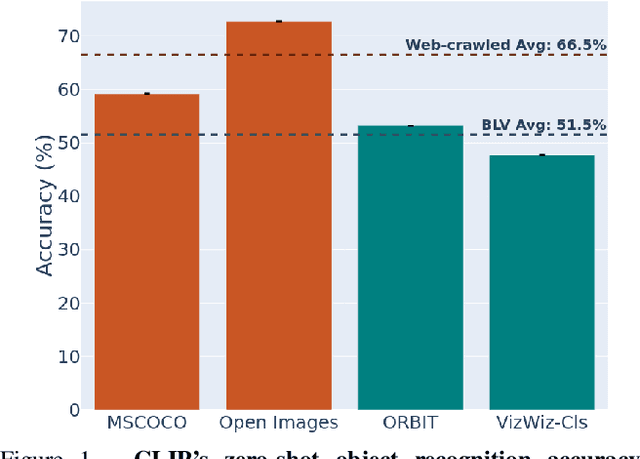
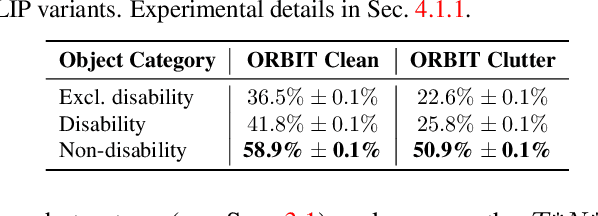
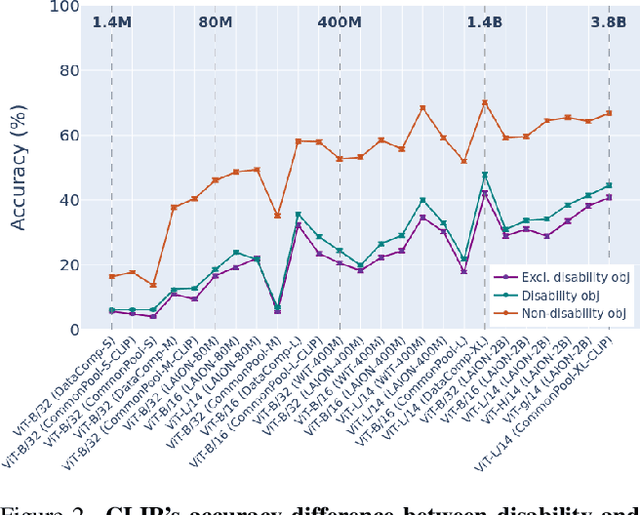
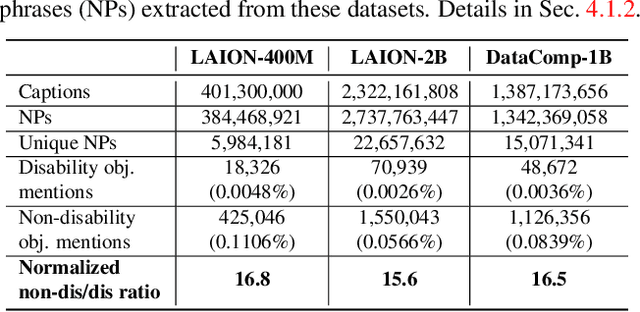
Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.