 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemper-Then-Tilt: Principled Unlearning for Generative Models through Tempering and Classifier Guidance
Feb 10, 2026We study machine unlearning in large generative models by framing the task as density ratio estimation to a target distribution rather than supervised fine-tuning. While classifier guidance is a standard approach for approximating this ratio and can succeed in general, we show it can fail to faithfully unlearn with finite samples when the forget set represents a sharp, concentrated data distribution. To address this, we introduce Temper-Then-Tilt Unlearning (T3-Unlearning), which freezes the base model and applies a two-step inference procedure: (i) tempering the base distribution to flatten high-confidence spikes, and (ii) tilting the tempered distribution using a lightweight classifier trained to distinguish retain from forget samples. Our theoretical analysis provides finite-sample guarantees linking the surrogate classifier's risk to unlearning error, proving that tempering is necessary to successfully unlearn for concentrated distributions. Empirical evaluations on the TOFU benchmark show that T3-Unlearning improves forget quality and generative utility over existing baselines, while training only a fraction of the parameters with a minimal runtime.
EntRGi: Entropy Aware Reward Guidance for Diffusion Language Models
Feb 04, 2026Reward guidance has been applied to great success in the test-time adaptation of continuous diffusion models; it updates each denoising step using the gradients from a downstream reward model. We study reward guidance for discrete diffusion language models, where one cannot differentiate through the natural outputs of the model because they are discrete tokens. Existing approaches either replace these discrete tokens with continuous relaxations, or employ techniques like the straight-through estimator. In this work, we show the downsides of both these methods. The former degrades gradient feedback because the reward model has never been trained with continuous inputs. The latter involves incorrect optimization because the gradient evaluated at discrete tokens is used to update continuous logits. Our key innovation is to go beyond this tradeoff by introducing a novel mechanism called EntRGi: Entropy aware Reward Guidance that dynamically regulates the gradients from the reward model. By modulating the continuous relaxation using the model's confidence, our approach substantially improves reward guidance while providing reliable inputs to the reward model. We empirically validate our approach on a 7B-parameter diffusion language model across 3 diverse reward models and 3 multi-skill benchmarks, showing consistent improvements over state-of-the-art methods.
Test-Time Anchoring for Discrete Diffusion Posterior Sampling
Oct 02, 2025We study the problem of posterior sampling using pretrained discrete diffusion foundation models, aiming to recover images from noisy measurements without retraining task-specific models. While diffusion models have achieved remarkable success in generative modeling, most advances rely on continuous Gaussian diffusion. In contrast, discrete diffusion offers a unified framework for jointly modeling categorical data such as text and images. Beyond unification, discrete diffusion provides faster inference, finer control, and principled training-free Bayesian inference, making it particularly well-suited for posterior sampling. However, existing approaches to discrete diffusion posterior sampling face severe challenges: derivative-free guidance yields sparse signals, continuous relaxations limit applicability, and split Gibbs samplers suffer from the curse of dimensionality. To overcome these limitations, we introduce Anchored Posterior Sampling (APS) for masked diffusion foundation models, built on two key innovations -- quantized expectation for gradient-like guidance in discrete embedding space, and anchored remasking for adaptive decoding. Our approach achieves state-of-the-art performance among discrete diffusion samplers across linear and nonlinear inverse problems on the standard benchmarks. We further demonstrate the benefits of our approach in training-free stylization and text-guided editing.
Efficient Approximate Posterior Sampling with Annealed Langevin Monte Carlo
Aug 11, 2025We study the problem of posterior sampling in the context of score based generative models. We have a trained score network for a prior $p(x)$, a measurement model $p(y|x)$, and are tasked with sampling from the posterior $p(x|y)$. Prior work has shown this to be intractable in KL (in the worst case) under well-accepted computational hardness assumptions. Despite this, popular algorithms for tasks such as image super-resolution, stylization, and reconstruction enjoy empirical success. Rather than establishing distributional assumptions or restricted settings under which exact posterior sampling is tractable, we view this as a more general "tilting" problem of biasing a distribution towards a measurement. Under minimal assumptions, we show that one can tractably sample from a distribution that is simultaneously close to the posterior of a noised prior in KL divergence and the true posterior in Fisher divergence. Intuitively, this combination ensures that the resulting sample is consistent with both the measurement and the prior. To the best of our knowledge these are the first formal results for (approximate) posterior sampling in polynomial time.
Machine Unlearning under Overparameterization
May 28, 2025Machine unlearning algorithms aim to remove the influence of specific training samples, ideally recovering the model that would have resulted from training on the remaining data alone. We study unlearning in the overparameterized setting, where many models interpolate the data, and defining the unlearning solution as any loss minimizer over the retained set$\unicode{x2013}$as in prior work in the underparameterized setting$\unicode{x2013}$is inadequate, since the original model may already interpolate the retained data and satisfy this condition. In this regime, loss gradients vanish, rendering prior methods based on gradient perturbations ineffective, motivating both new unlearning definitions and algorithms. For this setting, we define the unlearning solution as the minimum-complexity interpolator over the retained data and propose a new algorithmic framework that only requires access to model gradients on the retained set at the original solution. We minimize a regularized objective over perturbations constrained to be orthogonal to these model gradients, a first-order relaxation of the interpolation condition. For different model classes, we provide exact and approximate unlearning guarantees, and we demonstrate that an implementation of our framework outperforms existing baselines across various unlearning experiments.
Anchored Diffusion Language Model
May 24, 2025



Diffusion Language Models (DLMs) promise parallel generation and bidirectional context, yet they underperform autoregressive (AR) models in both likelihood modeling and generated text quality. We identify that this performance gap arises when important tokens (e.g., key words or low-frequency words that anchor a sentence) are masked early in the forward process, limiting contextual information for accurate reconstruction. To address this, we introduce the Anchored Diffusion Language Model (ADLM), a novel two-stage framework that first predicts distributions over important tokens via an anchor network, and then predicts the likelihoods of missing tokens conditioned on the anchored predictions. ADLM significantly improves test perplexity on LM1B and OpenWebText, achieving up to 25.4% gains over prior DLMs, and narrows the gap with strong AR baselines. It also achieves state-of-the-art performance in zero-shot generalization across seven benchmarks and surpasses AR models in MAUVE score, which marks the first time a DLM generates better human-like text than an AR model. Theoretically, we derive an Anchored Negative Evidence Lower Bound (ANELBO) objective and show that anchoring improves sample complexity and likelihood modeling. Beyond diffusion, anchoring boosts performance in AR models and enhances reasoning in math and logic tasks, outperforming existing chain-of-thought approaches
Asymptotically-Optimal Gaussian Bandits with Side Observations
May 15, 2025We study the problem of Gaussian bandits with general side information, as first introduced by Wu, Szepesvari, and Gyorgy. In this setting, the play of an arm reveals information about other arms, according to an arbitrary a priori known side information matrix: each element of this matrix encodes the fidelity of the information that the ``row'' arm reveals about the ``column'' arm. In the case of Gaussian noise, this model subsumes standard bandits, full-feedback, and graph-structured feedback as special cases. In this work, we first construct an LP-based asymptotic instance-dependent lower bound on the regret. The LP optimizes the cost (regret) required to reliably estimate the suboptimality gap of each arm. This LP lower bound motivates our main contribution: the first known asymptotically optimal algorithm for this general setting.
Meta-Learning Adaptable Foundation Models
Oct 29, 2024


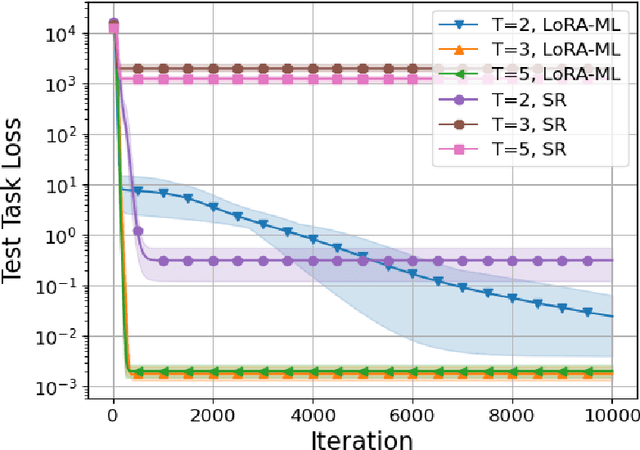
The power of foundation models (FMs) lies in their capacity to learn highly expressive representations that can be adapted to a broad spectrum of tasks. However, these pretrained models require multiple stages of fine-tuning to become effective for downstream applications. Conventionally, the model is first retrained on the aggregate of a diverse set of tasks of interest and then adapted to specific low-resource downstream tasks by utilizing a parameter-efficient fine-tuning (PEFT) scheme. While this two-phase procedure seems reasonable, the independence of the retraining and fine-tuning phases causes a major issue, as there is no guarantee the retrained model will achieve good performance post-fine-tuning. To explicitly address this issue, we introduce a meta-learning framework infused with PEFT in this intermediate retraining stage to learn a model that can be easily adapted to unseen tasks. For our theoretical results, we focus on linear models using low-rank adaptations. In this setting, we demonstrate the suboptimality of standard retraining for finding an adaptable set of parameters. Further, we prove that our method recovers the optimally adaptable parameters. We then apply these theoretical insights to retraining the RoBERTa model to predict the continuation of conversations between different personas within the ConvAI2 dataset. Empirically, we observe significant performance benefits using our proposed meta-learning scheme during retraining relative to the conventional approach.
Constrained Posterior Sampling: Time Series Generation with Hard Constraints
Oct 16, 2024



Generating realistic time series samples is crucial for stress-testing models and protecting user privacy by using synthetic data. In engineering and safety-critical applications, these samples must meet certain hard constraints that are domain-specific or naturally imposed by physics or nature. Consider, for example, generating electricity demand patterns with constraints on peak demand times. This can be used to stress-test the functioning of power grids during adverse weather conditions. Existing approaches for generating constrained time series are either not scalable or degrade sample quality. To address these challenges, we introduce Constrained Posterior Sampling (CPS), a diffusion-based sampling algorithm that aims to project the posterior mean estimate into the constraint set after each denoising update. Notably, CPS scales to a large number of constraints (~100) without requiring additional training. We provide theoretical justifications highlighting the impact of our projection step on sampling. Empirically, CPS outperforms state-of-the-art methods in sample quality and similarity to real time series by around 10% and 42%, respectively, on real-world stocks, traffic, and air quality datasets.
Semantic Image Inversion and Editing using Rectified Stochastic Differential Equations
Oct 14, 2024



Generative models transform random noise into images; their inversion aims to transform images back to structured noise for recovery and editing. This paper addresses two key tasks: (i) inversion and (ii) editing of a real image using stochastic equivalents of rectified flow models (such as Flux). Although Diffusion Models (DMs) have recently dominated the field of generative modeling for images, their inversion presents faithfulness and editability challenges due to nonlinearities in drift and diffusion. Existing state-of-the-art DM inversion approaches rely on training of additional parameters or test-time optimization of latent variables; both are expensive in practice. Rectified Flows (RFs) offer a promising alternative to diffusion models, yet their inversion has been underexplored. We propose RF inversion using dynamic optimal control derived via a linear quadratic regulator. We prove that the resulting vector field is equivalent to a rectified stochastic differential equation. Additionally, we extend our framework to design a stochastic sampler for Flux. Our inversion method allows for state-of-the-art performance in zero-shot inversion and editing, outperforming prior works in stroke-to-image synthesis and semantic image editing, with large-scale human evaluations confirming user preference.