 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Information Storage and Transfer in Multi-modal Large Language Models
Jun 06, 2024Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.
Challenges for Responsible AI Design and Workflow Integration in Healthcare: A Case Study of Automatic Feeding Tube Qualification in Radiology
May 08, 2024



Nasogastric tubes (NGTs) are feeding tubes that are inserted through the nose into the stomach to deliver nutrition or medication. If not placed correctly, they can cause serious harm, even death to patients. Recent AI developments demonstrate the feasibility of robustly detecting NGT placement from Chest X-ray images to reduce risks of sub-optimally or critically placed NGTs being missed or delayed in their detection, but gaps remain in clinical practice integration. In this study, we present a human-centered approach to the problem and describe insights derived following contextual inquiry and in-depth interviews with 15 clinical stakeholders. The interviews helped understand challenges in existing workflows, and how best to align technical capabilities with user needs and expectations. We discovered the trade-offs and complexities that need consideration when choosing suitable workflow stages, target users, and design configurations for different AI proposals. We explored how to balance AI benefits and risks for healthcare staff and patients within broader organizational and medical-legal constraints. We also identified data issues related to edge cases and data biases that affect model training and evaluation; how data documentation practices influence data preparation and labelling; and how to measure relevant AI outcomes reliably in future evaluations. We discuss how our work informs design and development of AI applications that are clinically useful, ethical, and acceptable in real-world healthcare services.
Explaining CLIP's performance disparities on data from blind/low vision users
Dec 01, 2023



Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.
ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition
Apr 09, 2021
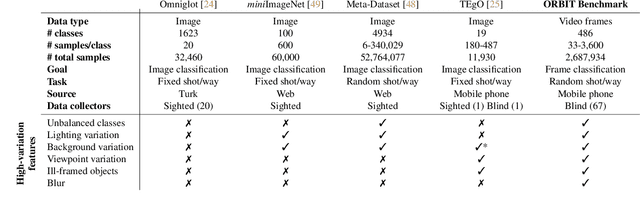
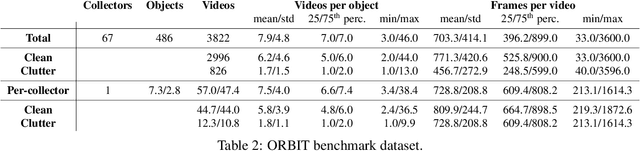
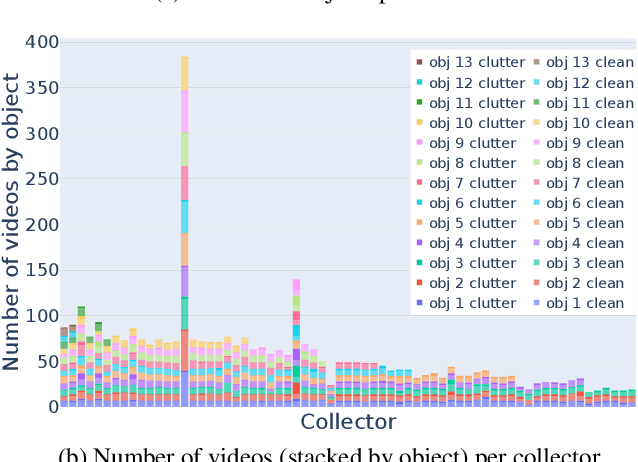
Object recognition has made great advances in the last decade, but predominately still relies on many high-quality training examples per object category. In contrast, learning new objects from only a few examples could enable many impactful applications from robotics to user personalization. Most few-shot learning research, however, has been driven by benchmark datasets that lack the high variation that these applications will face when deployed in the real-world. To close this gap, we present the ORBIT dataset and benchmark, grounded in a real-world application of teachable object recognizers for people who are blind/low vision. The dataset contains 3,822 videos of 486 objects recorded by people who are blind/low-vision on their mobile phones, and the benchmark reflects a realistic, highly challenging recognition problem, providing a rich playground to drive research in robustness to few-shot, high-variation conditions. We set the first state-of-the-art on the benchmark and show that there is massive scope for further innovation, holding the potential to impact a broad range of real-world vision applications including tools for the blind/low-vision community. The dataset is available at https://bit.ly/2OyElCj and the code to run the benchmark at https://bit.ly/39YgiUW.