 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
Apr 11, 2024
While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model's ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
WaveMo: Learning Wavefront Modulations to See Through Scattering
Apr 11, 2024Imaging through scattering media is a fundamental and pervasive challenge in fields ranging from medical diagnostics to astronomy. A promising strategy to overcome this challenge is wavefront modulation, which induces measurement diversity during image acquisition. Despite its importance, designing optimal wavefront modulations to image through scattering remains under-explored. This paper introduces a novel learning-based framework to address the gap. Our approach jointly optimizes wavefront modulations and a computationally lightweight feedforward "proxy" reconstruction network. This network is trained to recover scenes obscured by scattering, using measurements that are modified by these modulations. The learned modulations produced by our framework generalize effectively to unseen scattering scenarios and exhibit remarkable versatility. During deployment, the learned modulations can be decoupled from the proxy network to augment other more computationally expensive restoration algorithms. Through extensive experiments, we demonstrate our approach significantly advances the state of the art in imaging through scattering media. Our project webpage is at https://wavemo-2024.github.io/.
Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Apr 11, 2024Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
Clean-image Backdoor Attacks
Mar 26, 2024To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024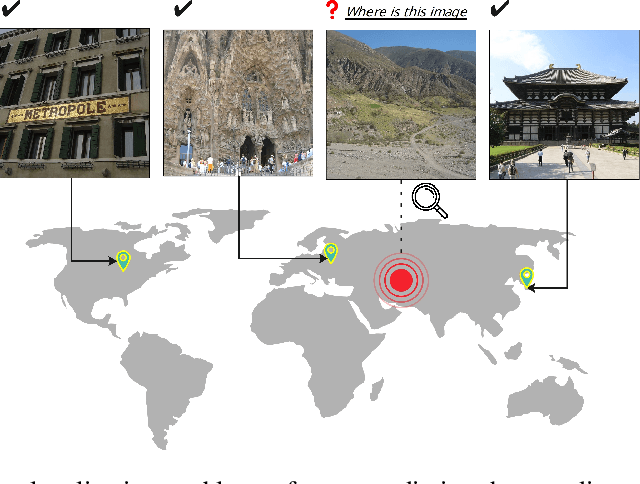
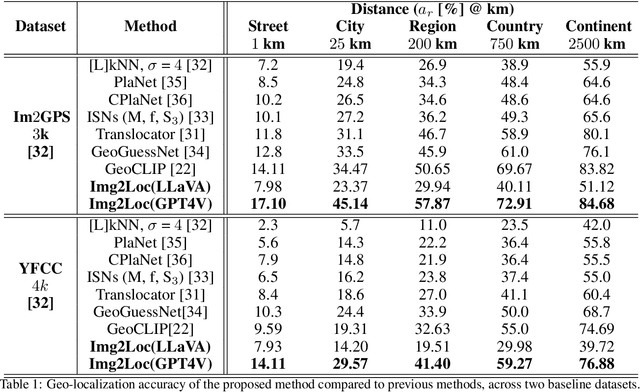
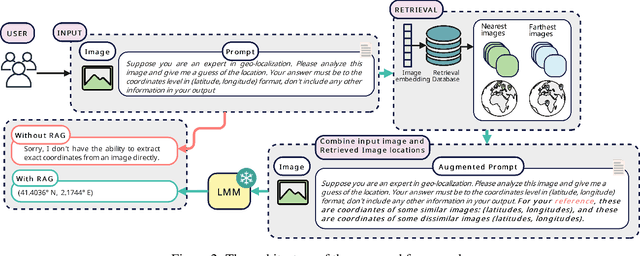
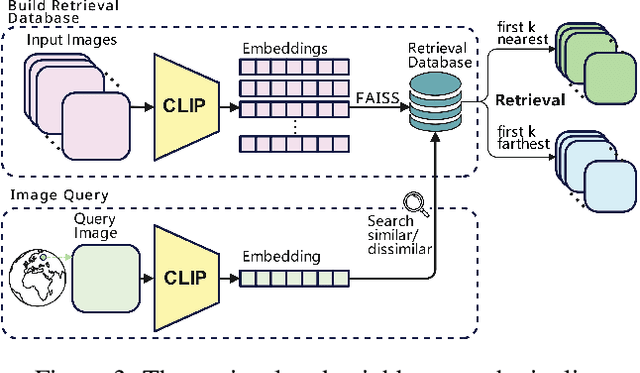
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.
A Mutual Inclusion Mechanism for Precise Boundary Segmentation in Medical Images
Apr 12, 2024In medical imaging, accurate image segmentation is crucial for quantifying diseases, assessing prognosis, and evaluating treatment outcomes. However, existing methods lack an in-depth integration of global and local features, failing to pay special attention to abnormal regions and boundary details in medical images. To this end, we present a novel deep learning-based approach, MIPC-Net, for precise boundary segmentation in medical images. Our approach, inspired by radiologists' working patterns, features two distinct modules: (i) \textbf{Mutual Inclusion of Position and Channel Attention (MIPC) module}: To enhance the precision of boundary segmentation in medical images, we introduce the MIPC module, which enhances the focus on channel information when extracting position features and vice versa; (ii) \textbf{GL-MIPC-Residue}: To improve the restoration of medical images, we propose the GL-MIPC-Residue, a global residual connection that enhances the integration of the encoder and decoder by filtering out invalid information and restoring the most effective information lost during the feature extraction process. We evaluate the performance of the proposed model using metrics such as Dice coefficient (DSC) and Hausdorff Distance (HD) on three publicly accessible datasets: Synapse, ISIC2018-Task, and Segpc. Our ablation study shows that each module contributes to improving the quality of segmentation results. Furthermore, with the assistance of both modules, our approach outperforms state-of-the-art methods across all metrics on the benchmark datasets, notably achieving a 2.23mm reduction in HD on the Synapse dataset, strongly evidencing our model's enhanced capability for precise image boundary segmentation. Codes will be available at https://github.com/SUN-1024/MIPC-Net.
DreamScape: 3D Scene Creation via Gaussian Splatting joint Correlation Modeling
Apr 14, 2024Recent progress in text-to-3D creation has been propelled by integrating the potent prior of Diffusion Models from text-to-image generation into the 3D domain. Nevertheless, generating 3D scenes characterized by multiple instances and intricate arrangements remains challenging. In this study, we present DreamScape, a method for creating highly consistent 3D scenes solely from textual descriptions, leveraging the strong 3D representation capabilities of Gaussian Splatting and the complex arrangement abilities of large language models (LLMs). Our approach involves a 3D Gaussian Guide ($3{DG^2}$) for scene representation, consisting of semantic primitives (objects) and their spatial transformations and relationships derived directly from text prompts using LLMs. This compositional representation allows for local-to-global optimization of the entire scene. A progressive scale control is tailored during local object generation, ensuring that objects of different sizes and densities adapt to the scene, which addresses training instability issue arising from simple blending in the subsequent global optimization stage. To mitigate potential biases of LLM priors, we model collision relationships between objects at the global level, enhancing physical correctness and overall realism. Additionally, to generate pervasive objects like rain and snow distributed extensively across the scene, we introduce a sparse initialization and densification strategy. Experiments demonstrate that DreamScape offers high usability and controllability, enabling the generation of high-fidelity 3D scenes from only text prompts and achieving state-of-the-art performance compared to other methods.
In My Perspective, In My Hands: Accurate Egocentric 2D Hand Pose and Action Recognition
Apr 14, 2024Action recognition is essential for egocentric video understanding, allowing automatic and continuous monitoring of Activities of Daily Living (ADLs) without user effort. Existing literature focuses on 3D hand pose input, which requires computationally intensive depth estimation networks or wearing an uncomfortable depth sensor. In contrast, there has been insufficient research in understanding 2D hand pose for egocentric action recognition, despite the availability of user-friendly smart glasses in the market capable of capturing a single RGB image. Our study aims to fill this research gap by exploring the field of 2D hand pose estimation for egocentric action recognition, making two contributions. Firstly, we introduce two novel approaches for 2D hand pose estimation, namely EffHandNet for single-hand estimation and EffHandEgoNet, tailored for an egocentric perspective, capturing interactions between hands and objects. Both methods outperform state-of-the-art models on H2O and FPHA public benchmarks. Secondly, we present a robust action recognition architecture from 2D hand and object poses. This method incorporates EffHandEgoNet, and a transformer-based action recognition method. Evaluated on H2O and FPHA datasets, our architecture has a faster inference time and achieves an accuracy of 91.32% and 94.43%, respectively, surpassing state of the art, including 3D-based methods. Our work demonstrates that using 2D skeletal data is a robust approach for egocentric action understanding. Extensive evaluation and ablation studies show the impact of the hand pose estimation approach, and how each input affects the overall performance.
Two-Phase Multi-Dose-Level PET Image Reconstruction with Dose Level Awareness
Apr 10, 2024To obtain high-quality positron emission tomography (PET) while minimizing radiation exposure, a range of methods have been designed to reconstruct standard-dose PET (SPET) from corresponding low-dose PET (LPET) images. However, most current methods merely learn the mapping between single-dose-level LPET and SPET images, but omit the dose disparity of LPET images in clinical scenarios. In this paper, to reconstruct high-quality SPET images from multi-dose-level LPET images, we design a novel two-phase multi-dose-level PET reconstruction algorithm with dose level awareness, containing a pre-training phase and a SPET prediction phase. Specifically, the pre-training phase is devised to explore both fine-grained discriminative features and effective semantic representation. The SPET prediction phase adopts a coarse prediction network utilizing pre-learned dose level prior to generate preliminary result, and a refinement network to precisely preserve the details. Experiments on MICCAI 2022 Ultra-low Dose PET Imaging Challenge Dataset have demonstrated the superiority of our method.