 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Recognition of Oil Leakage Area Based on Logical Semantic Discrimination
Nov 17, 2023
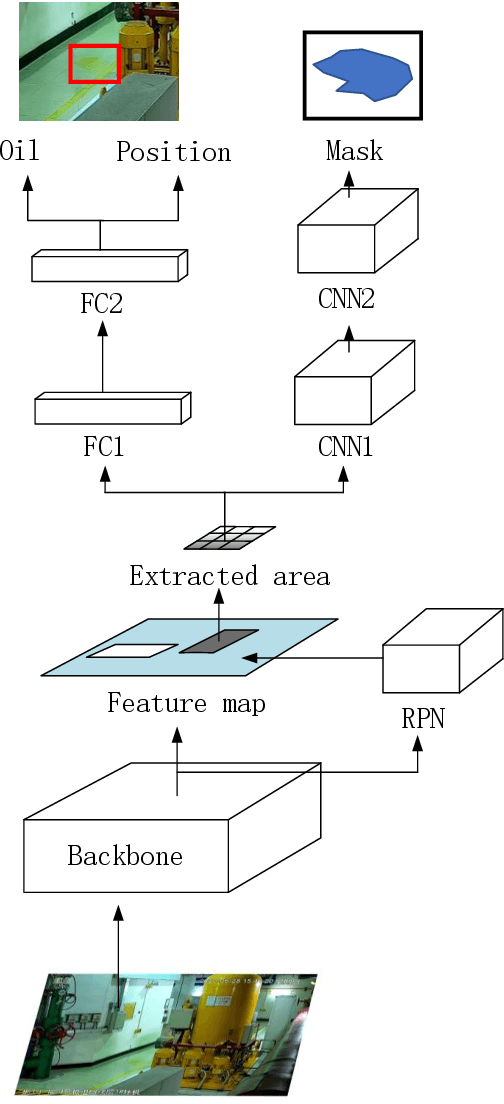


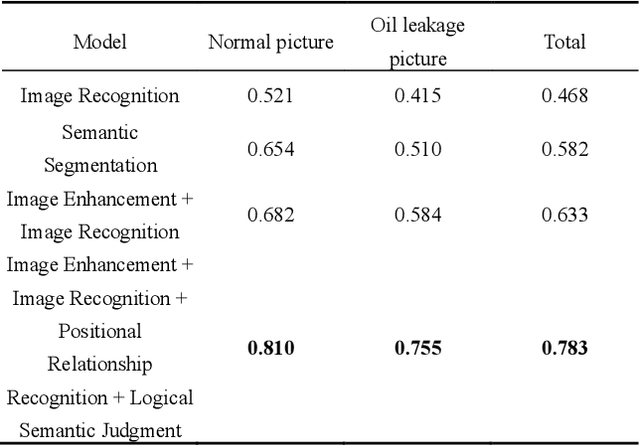
Implementing precise detection of oil leaks in peak load equipment through image analysis can significantly enhance inspection quality and ensure the system's safety and reliability. However, challenges such as varying shapes of oil-stained regions, background noise, and fluctuating lighting conditions complicate the detection process. To address this, the integration of logical rule-based discrimination into image recognition has been proposed. This approach involves recognizing the spatial relationships among objects to semantically segment images of oil spills using a Mask RCNN network. The process begins with histogram equalization to enhance the original image, followed by the use of Mask RCNN to identify the preliminary positions and outlines of oil tanks, the ground, and areas of potential oil contamination. Subsequent to this identification, the spatial relationships between these objects are analyzed. Logical rules are then applied to ascertain whether the suspected areas are indeed oil spills. This method's effectiveness has been confirmed by testing on images captured from peak power equipment in the field. The results indicate that this approach can adeptly tackle the challenges in identifying oil-contaminated areas, showing a substantial improvement in accuracy compared to existing methods.
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
Scout-Net: Prospective Personalized Estimation of CT Organ Doses from Scout Views
Dec 23, 2023Purpose: Estimation of patient-specific organ doses is required for more comprehensive dose metrics, such as effective dose. Currently, available methods are performed retrospectively using the CT images themselves, which can only be done after the scan. To optimize CT acquisitions before scanning, rapid prediction of patient-specific organ dose is needed prospectively, using available scout images. We, therefore, devise an end-to-end, fully-automated deep learning solution to perform real-time, patient-specific, organ-level dosimetric estimation of CT scans. Approach: We propose the Scout-Net model for CT dose prediction at six different organs as well as for the overall patient body, leveraging the routinely obtained frontal and lateral scout images of patients, before their CT scans. To obtain reference values of the organ doses, we used Monte Carlo simulation and 3D segmentation methods on the corresponding CT images of the patients. Results: We validate our proposed Scout-Net model against real patient CT data and demonstrate the effectiveness in estimating organ doses in real-time (only 27 ms on average per scan). Additionally, we demonstrate the efficiency (real-time execution), sufficiency (reasonable error rates), and robustness (consistent across varying patient sizes) of the Scout-Net model. Conclusions: An effective, efficient, and robust Scout-Net model, once incorporated into the CT acquisition plan, could potentially guide the automatic exposure control for balanced image quality and radiation dose.
LETA: Learning Transferable Attribution for Generic Vision Explainer
Dec 23, 2023Explainable machine learning significantly improves the transparency of deep neural networks~(DNN). However, existing work is constrained to explaining the behavior of individual model predictions, and lacks the ability to transfer the explanation across various models and tasks. This limitation results in explaining various tasks being time- and resource-consuming. To address this problem, we develop a pre-trained, DNN-based, generic explainer on large-scale image datasets, and leverage its transferability to explain various vision models for downstream tasks. In particular, the pre-training of generic explainer focuses on LEarning Transferable Attribution (LETA). The transferable attribution takes advantage of the versatile output of the target backbone encoders to comprehensively encode the essential attribution for explaining various downstream tasks. LETA guides the pre-training of the generic explainer towards the transferable attribution, and introduces a rule-based adaptation of the transferable attribution for explaining downstream tasks, without the need for additional training on downstream data. Theoretical analysis demonstrates that the pre-training of LETA enables minimizing the explanation error bound aligned with the conditional $\mathcal{V}$-information on downstream tasks. Empirical studies involve explaining three different architectures of vision models across three diverse downstream datasets. The experiment results indicate LETA is effective in explaining these tasks without the need for additional training on the data of downstream tasks.
Rusty Detection Using Image Processing For Maintenance Of Stations
Nov 16, 2023This study addresses the challenge of accurately seg-menting rusted areas on painted construction surfaces. A method leveraging digital image processing is explored to calculate the percentage of rust present on painted coatings. The proposed segmentation approach is based on the HSV color model. To equalize luminosity and mitigate the influence of illumination, a fundamental model of single-scale Retinex is applied specifically to the saturation component. Subsequently, the image undergoes further processing, involv-ing manual color filtering. This step is crucial for refining the identification of rusted regions. To enhance precision and filter out noise, the pixel areas selected through color filtering are subjected to the DBScan algorithm. This multi-step process aims to achieve a robust segmentation of rusted areas on painted construction surfaces, providing a valuable contribution to the field of corrosion detection and analysis.
VILA: On Pre-training for Visual Language Models
Dec 14, 2023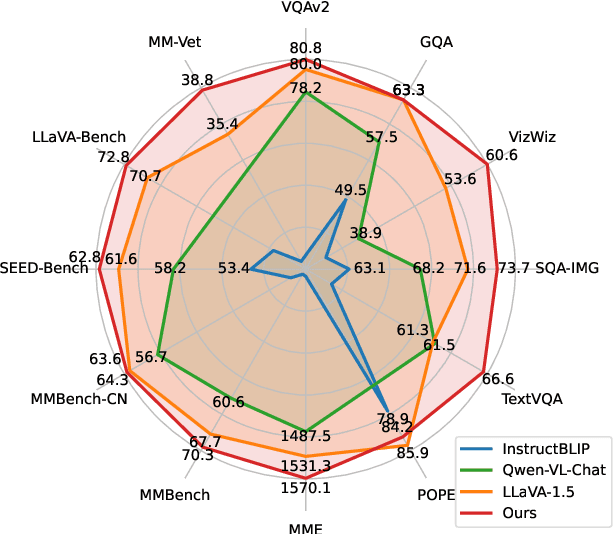
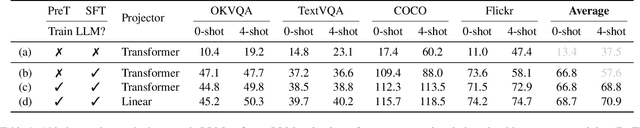
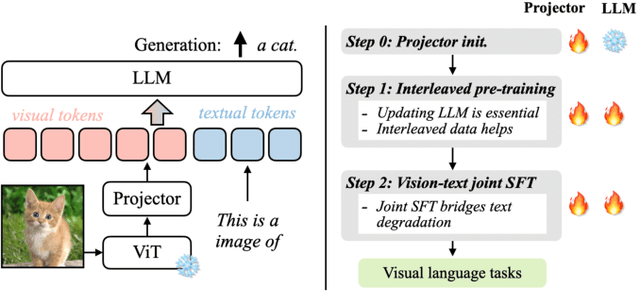

Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
Exploring the Naturalness of AI-Generated Images
Dec 14, 2023The proliferation of Artificial Intelligence-Generated Images (AGIs) has greatly expanded the Image Naturalness Assessment (INA) problem. Different from early definitions that mainly focus on tone-mapped images with limited distortions (e.g., exposure, contrast, and color reproduction), INA on AI-generated images is especially challenging as it has more diverse contents and could be affected by factors from multiple perspectives, including low-level technical distortions and high-level rationality distortions. In this paper, we take the first step to benchmark and assess the visual naturalness of AI-generated images. First, we construct the AI-Generated Image Naturalness (AGIN) database by conducting a large-scale subjective study to collect human opinions on the overall naturalness as well as perceptions from technical and rationality perspectives. AGIN verifies that naturalness is universally and disparately affected by both technical and rationality distortions. Second, we propose the Joint Objective Image Naturalness evaluaTor (JOINT), to automatically learn the naturalness of AGIs that aligns human ratings. Specifically, JOINT imitates human reasoning in naturalness evaluation by jointly learning both technical and rationality perspectives. Experimental results show our proposed JOINT significantly surpasses baselines for providing more subjectively consistent results on naturalness assessment. Our database and code will be released in https://github.com/zijianchen98/AGIN.
Pola4All: survey of polarimetric applications and an open-source toolkit to analyze polarization
Dec 22, 2023Polarization information of the light can provide rich cues for computer vision and scene understanding tasks, such as the type of material, pose, and shape of the objects. With the advent of new and cheap polarimetric sensors, this imaging modality is becoming accessible to a wider public for solving problems such as pose estimation, 3D reconstruction, underwater navigation, and depth estimation. However, we observe several limitations regarding the usage of this sensorial modality, as well as a lack of standards and publicly available tools to analyze polarization images. Furthermore, although polarization camera manufacturers usually provide acquisition tools to interface with their cameras, they rarely include processing algorithms that make use of the polarization information. In this paper, we review recent advances in applications that involve polarization imaging, including a comprehensive survey of recent advances on polarization for vision and robotics perception tasks. We also introduce a complete software toolkit that provides common standards to communicate with and process information from most of the existing micro-grid polarization cameras on the market. The toolkit also implements several image processing algorithms for this modality, and it is publicly available on GitHub: https://github.com/vibot-lab/Pola4all_JEI_2023.
Inclusive normalization of face images to passport format
Dec 22, 2023Face recognition has been used more and more in real world applications in recent years. However, when the skin color bias is coupled with intra-personal variations like harsh illumination, the face recognition task is more likely to fail, even during human inspection. Face normalization methods try to deal with such challenges by removing intra-personal variations from an input image while keeping the identity the same. However, most face normalization methods can only remove one or two variations and ignore dataset biases such as skin color bias. The outputs of many face normalization methods are also not realistic to human observers. In this work, a style based face normalization model (StyleFNM) is proposed to remove most intra-personal variations including large changes in pose, bad or harsh illumination, low resolution, blur, facial expressions, and accessories like sunglasses among others. The dataset bias is also dealt with in this paper by controlling a pretrained GAN to generate a balanced dataset of passport-like images. The experimental results show that StyleFNM can generate more realistic outputs and can improve significantly the accuracy and fairness of face recognition systems.
An Interpretable Deep Learning Approach for Skin Cancer Categorization
Dec 17, 2023Skin cancer is a serious worldwide health issue, precise and early detection is essential for better patient outcomes and effective treatment. In this research, we use modern deep learning methods and explainable artificial intelligence (XAI) approaches to address the problem of skin cancer detection. To categorize skin lesions, we employ four cutting-edge pre-trained models: XceptionNet, EfficientNetV2S, InceptionResNetV2, and EfficientNetV2M. Image augmentation approaches are used to reduce class imbalance and improve the generalization capabilities of our models. Our models decision-making process can be clarified because of the implementation of explainable artificial intelligence (XAI). In the medical field, interpretability is essential to establish credibility and make it easier to implement AI driven diagnostic technologies into clinical workflows. We determined the XceptionNet architecture to be the best performing model, achieving an accuracy of 88.72%. Our study shows how deep learning and explainable artificial intelligence (XAI) can improve skin cancer diagnosis, laying the groundwork for future developments in medical image analysis. These technologies ability to allow for early and accurate detection could enhance patient care, lower healthcare costs, and raise the survival rates for those with skin cancer. Source Code: https://github.com/Faysal-MD/An-Interpretable-Deep-Learning?Approach-for-Skin-Cancer-Categorization-IEEE2023