 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Disentangled Identifiers for Action-Customized Text-to-Image Generation
Nov 30, 2023
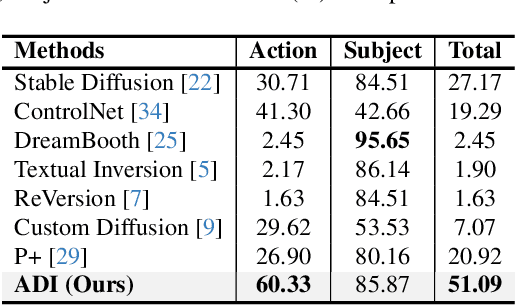

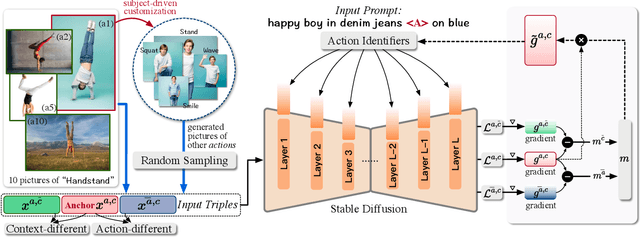

This study focuses on a novel task in text-to-image (T2I) generation, namely action customization. The objective of this task is to learn the co-existing action from limited data and generalize it to unseen humans or even animals. Experimental results show that existing subject-driven customization methods fail to learn the representative characteristics of actions and struggle in decoupling actions from context features, including appearance. To overcome the preference for low-level features and the entanglement of high-level features, we propose an inversion-based method Action-Disentangled Identifier (ADI) to learn action-specific identifiers from the exemplar images. ADI first expands the semantic conditioning space by introducing layer-wise identifier tokens, thereby increasing the representational richness while distributing the inversion across different features. Then, to block the inversion of action-agnostic features, ADI extracts the gradient invariance from the constructed sample triples and masks the updates of irrelevant channels. To comprehensively evaluate the task, we present an ActionBench that includes a variety of actions, each accompanied by meticulously selected samples. Both quantitative and qualitative results show that our ADI outperforms existing baselines in action-customized T2I generation. Our project page is at https://adi-t2i.github.io/ADI.
Harnessing Diffusion Models for Visual Perception with Meta Prompts
Dec 22, 2023The issue of generative pretraining for vision models has persisted as a long-standing conundrum. At present, the text-to-image (T2I) diffusion model demonstrates remarkable proficiency in generating high-definition images matching textual inputs, a feat made possible through its pre-training on large-scale image-text pairs. This leads to a natural inquiry: can diffusion models be utilized to tackle visual perception tasks? In this paper, we propose a simple yet effective scheme to harness a diffusion model for visual perception tasks. Our key insight is to introduce learnable embeddings (meta prompts) to the pre-trained diffusion models to extract proper features for perception. The effect of meta prompts are two-fold. First, as a direct replacement of the text embeddings in the T2I models, it can activate task-relevant features during feature extraction. Second, it will be used to re-arrange the extracted features to ensures that the model focuses on the most pertinent features for the task on hand. Additionally, we design a recurrent refinement training strategy that fully leverages the property of diffusion models, thereby yielding stronger visual features. Extensive experiments across various benchmarks validate the effectiveness of our approach. Our approach achieves new performance records in depth estimation tasks on NYU depth V2 and KITTI, and in semantic segmentation task on CityScapes. Concurrently, the proposed method attains results comparable to the current state-of-the-art in semantic segmentation on ADE20K and pose estimation on COCO datasets, further exemplifying its robustness and versatility.
Towards Flexible, Scalable, and Adaptive Multi-Modal Conditioned Face Synthesis
Dec 26, 2023Recent progress in multi-modal conditioned face synthesis has enabled the creation of visually striking and accurately aligned facial images. Yet, current methods still face issues with scalability, limited flexibility, and a one-size-fits-all approach to control strength, not accounting for the differing levels of conditional entropy, a measure of unpredictability in data given some condition, across modalities. To address these challenges, we introduce a novel uni-modal training approach with modal surrogates, coupled with an entropy-aware modal-adaptive modulation, to support flexible, scalable, and scalable multi-modal conditioned face synthesis network. Our uni-modal training with modal surrogate that only leverage uni-modal data, use modal surrogate to decorate condition with modal-specific characteristic and serve as linker for inter-modal collaboration , fully learns each modality control in face synthesis process as well as inter-modal collaboration. The entropy-aware modal-adaptive modulation finely adjust diffusion noise according to modal-specific characteristics and given conditions, enabling well-informed step along denoising trajectory and ultimately leading to synthesis results of high fidelity and quality. Our framework improves multi-modal face synthesis under various conditions, surpassing current methods in image quality and fidelity, as demonstrated by our thorough experimental results.
SAME++: A Self-supervised Anatomical eMbeddings Enhanced medical image registration framework using stable sampling and regularized transformation
Nov 25, 2023Image registration is a fundamental medical image analysis task. Ideally, registration should focus on aligning semantically corresponding voxels, i.e., the same anatomical locations. However, existing methods often optimize similarity measures computed directly on intensities or on hand-crafted features, which lack anatomical semantic information. These similarity measures may lead to sub-optimal solutions where large deformations, complex anatomical differences, or cross-modality imagery exist. In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration building on top of a Self-supervised Anatomical eMbedding (SAM) algorithm, which is capable of computing dense anatomical correspondences between two images at the voxel level. We name our approach SAM-Enhanced registration (SAME++), which decomposes image registration into four steps: affine transformation, coarse deformation, deep non-parametric transformation, and instance optimization. Using SAM embeddings, we enhance these steps by finding more coherent correspondence and providing features with better semantic guidance. We extensively evaluated SAME++ using more than 50 labeled organs on three challenging inter-subject registration tasks of different body parts. As a complete registration framework, SAME++ markedly outperforms leading methods by $4.2\%$ - $8.2\%$ in terms of Dice score while being orders of magnitude faster than numerical optimization-based methods. Code is available at \url{https://github.com/alibaba-damo-academy/same}.
Breaking Temporal Consistency: Generating Video Universal Adversarial Perturbations Using Image Models
Nov 17, 2023As video analysis using deep learning models becomes more widespread, the vulnerability of such models to adversarial attacks is becoming a pressing concern. In particular, Universal Adversarial Perturbation (UAP) poses a significant threat, as a single perturbation can mislead deep learning models on entire datasets. We propose a novel video UAP using image data and image model. This enables us to take advantage of the rich image data and image model-based studies available for video applications. However, there is a challenge that image models are limited in their ability to analyze the temporal aspects of videos, which is crucial for a successful video attack. To address this challenge, we introduce the Breaking Temporal Consistency (BTC) method, which is the first attempt to incorporate temporal information into video attacks using image models. We aim to generate adversarial videos that have opposite patterns to the original. Specifically, BTC-UAP minimizes the feature similarity between neighboring frames in videos. Our approach is simple but effective at attacking unseen video models. Additionally, it is applicable to videos of varying lengths and invariant to temporal shifts. Our approach surpasses existing methods in terms of effectiveness on various datasets, including ImageNet, UCF-101, and Kinetics-400.
Q-Seg: Quantum Annealing-based Unsupervised Image Segmentation
Nov 21, 2023In this study, we present Q-Seg, a novel unsupervised image segmentation method based on quantum annealing, tailored for existing quantum hardware. We formulate the pixel-wise segmentation problem, which assimilates spectral and spatial information of the image, as a graph-cut optimization task. Our method efficiently leverages the interconnected qubit topology of the D-Wave Advantage device, offering superior scalability over existing quantum approaches and outperforming state-of-the-art classical methods. Our empirical evaluations on synthetic datasets reveal that Q-Seg offers better runtime performance against the classical optimizer Gurobi. Furthermore, we evaluate our method on segmentation of Earth Observation images, an area of application where the amount of labeled data is usually very limited. In this case, Q-Seg demonstrates near-optimal results in flood mapping detection with respect to classical supervised state-of-the-art machine learning methods. Also, Q-Seg provides enhanced segmentation for forest coverage compared to existing annotated masks. Thus, Q-Seg emerges as a viable alternative for real-world applications using available quantum hardware, particularly in scenarios where the lack of labeled data and computational runtime are critical.
Align Your Gaussians: Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models
Dec 21, 2023Text-guided diffusion models have revolutionized image and video generation and have also been successfully used for optimization-based 3D object synthesis. Here, we instead focus on the underexplored text-to-4D setting and synthesize dynamic, animated 3D objects using score distillation methods with an additional temporal dimension. Compared to previous work, we pursue a novel compositional generation-based approach, and combine text-to-image, text-to-video, and 3D-aware multiview diffusion models to provide feedback during 4D object optimization, thereby simultaneously enforcing temporal consistency, high-quality visual appearance and realistic geometry. Our method, called Align Your Gaussians (AYG), leverages dynamic 3D Gaussian Splatting with deformation fields as 4D representation. Crucial to AYG is a novel method to regularize the distribution of the moving 3D Gaussians and thereby stabilize the optimization and induce motion. We also propose a motion amplification mechanism as well as a new autoregressive synthesis scheme to generate and combine multiple 4D sequences for longer generation. These techniques allow us to synthesize vivid dynamic scenes, outperform previous work qualitatively and quantitatively and achieve state-of-the-art text-to-4D performance. Due to the Gaussian 4D representation, different 4D animations can be seamlessly combined, as we demonstrate. AYG opens up promising avenues for animation, simulation and digital content creation as well as synthetic data generation.
Zero-shot Building Attribute Extraction from Large-Scale Vision and Language Models
Dec 19, 2023Existing building recognition methods, exemplified by BRAILS, utilize supervised learning to extract information from satellite and street-view images for classification and segmentation. However, each task module requires human-annotated data, hindering the scalability and robustness to regional variations and annotation imbalances. In response, we propose a new zero-shot workflow for building attribute extraction that utilizes large-scale vision and language models to mitigate reliance on external annotations. The proposed workflow contains two key components: image-level captioning and segment-level captioning for the building images based on the vocabularies pertinent to structural and civil engineering. These two components generate descriptive captions by computing feature representations of the image and the vocabularies, and facilitating a semantic match between the visual and textual representations. Consequently, our framework offers a promising avenue to enhance AI-driven captioning for building attribute extraction in the structural and civil engineering domains, ultimately reducing reliance on human annotations while bolstering performance and adaptability.
SeeBel: Seeing is Believing
Dec 18, 2023Semantic Segmentation is a significant research field in Computer Vision. Despite being a widely studied subject area, many visualization tools do not exist that capture segmentation quality and dataset statistics such as a class imbalance in the same view. While the significance of discovering and introspecting the correlation between dataset statistics and AI model performance for dense prediction computer vision tasks such as semantic segmentation is well established in the computer vision literature, to the best of our knowledge, no visualization tools have been proposed to view and analyze the aforementioned tasks. Our project aims to bridge this gap by proposing three visualizations that enable users to compare dataset statistics and AI performance for segmenting all images, a single image in the dataset, explore the AI model's attention on image regions once trained and browse the quality of masks predicted by AI for any selected (by user) number of objects under the same tool. Our project tries to further increase the interpretability of the trained AI model for segmentation by visualizing its image attention weights. For visualization, we use Scatterplot and Heatmap to encode correlation and features, respectively. We further propose to conduct surveys on real users to study the efficacy of our visualization tool in computer vision and AI domain. The full system can be accessed at https://github.com/dipta007/SeeBel
Diffusion-EXR: Controllable Review Generation for Explainable Recommendation via Diffusion Models
Dec 24, 2023Denoising Diffusion Probabilistic Model (DDPM) has shown great competence in image and audio generation tasks. However, there exist few attempts to employ DDPM in the text generation, especially review generation under recommendation systems. Fueled by the predicted reviews explainability that justifies recommendations could assist users better understand the recommended items and increase the transparency of recommendation system, we propose a Diffusion Model-based Review Generation towards EXplainable Recommendation named Diffusion-EXR. Diffusion-EXR corrupts the sequence of review embeddings by incrementally introducing varied levels of Gaussian noise to the sequence of word embeddings and learns to reconstruct the original word representations in the reverse process. The nature of DDPM enables our lightweight Transformer backbone to perform excellently in the recommendation review generation task. Extensive experimental results have demonstrated that Diffusion-EXR can achieve state-of-the-art review generation for recommendation on two publicly available benchmark datasets.