 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiSA: Lifelong Safety Adaptation via Conservative Policy Induction
May 14, 2026As AI agents move from chat interfaces to systems that read private data, call tools, and execute multi-step workflows, guardrails become a last line of defense against concrete deployment harms. In these settings, guardrail failures are no longer merely answer-quality errors: they can leak secrets, authorize unsafe actions, or block legitimate work. The hardest failures are often contextual: whether an action is acceptable depends on local privacy norms, organizational policies, and user expectations that resist pre-deployment specification. This creates a practical gap: guardrails must adapt to their own operating environments, yet deployment feedback is typically limited to sparse, noisy user-reported failures, and repeated fine-tuning is often impractical. To address this gap, we propose LiSA (Lifelong Safety Adaptation), a conservative policy induction framework that improves a fixed base guardrail through structured memory. LiSA converts occasional failures into reusable policy abstractions so that sparse reports can generalize beyond individual cases, adds conflict-aware local rules to prevent overgeneralization in mixed-label contexts, and applies evidence-aware confidence gating via a posterior lower bound, so that memory reuse scales with accumulated evidence rather than empirical accuracy alone. Across PrivacyLens+, ConFaide+, and AgentHarm, LiSA consistently outperforms strong memory-based baselines under sparse feedback, remains robust under noisy user feedback even at 20% label-flip rates, and pushes the latency--performance frontier beyond backbone model scaling. Ultimately, LiSA offers a practical path to secure AI agents against the unpredictable long tail of real-world edge risks.
ReflectCAP: Detailed Image Captioning with Reflective Memory
Apr 14, 2026Detailed image captioning demands both factual grounding and fine-grained coverage, yet existing methods have struggled to achieve them simultaneously. We address this tension with Reflective Note-Guided Captioning (ReflectCAP), where a multi-agent pipeline analyzes what the target large vision-language model (LVLM) consistently hallucinates and what it systematically overlooks, distilling these patterns into reusable guidelines called Structured Reflection Notes. At inference time, these notes steer the captioning model along both axes -- what to avoid and what to attend to -- yielding detailed captions that jointly improve factuality and coverage. Applying this method to 8 LVLMs spanning the GPT-4.1 family, Qwen series, and InternVL variants, ReflectCAP reaches the Pareto frontier of the trade-off between factuality and coverage, and delivers substantial gains on CapArena-Auto, where generated captions are judged head-to-head against strong reference models. Moreover, ReflectCAP offers a more favorable trade-off between caption quality and compute cost than model scaling or existing multi-agent pipelines, which incur 21--36\% greater overhead. This makes high-quality detailed captioning viable under real-world cost and latency constraints.
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Mar 25, 2026Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can reduce response length while degrading performance. We trace this degradation to the suppression of epistemic verbalization - the model's expression of uncertainty during reasoning. Through controlled experiments varying conditioning context richness and task coverage, we show that conditioning the teacher on rich information suppresses uncertainty expression, enabling rapid in-domain optimization with limited task coverage but harming OOD performance, where unseen problems benefit from expressing uncertainty and adjusting accordingly. Across Qwen3-8B, DeepSeek-Distill-Qwen-7B, and Olmo3-7B-Instruct, we observe performance drops of up to 40%. Our findings highlight that exposing appropriate levels of uncertainty is crucial for robust reasoning and underscore the importance of optimizing reasoning behavior beyond merely reinforcing correct answer traces.
Understanding Reasoning in LLMs through Strategic Information Allocation under Uncertainty
Mar 16, 2026LLMs often exhibit Aha moments during reasoning, such as apparent self-correction following tokens like "Wait," yet their underlying mechanisms remain unclear. We introduce an information-theoretic framework that decomposes reasoning into procedural information and epistemic verbalization - the explicit externalization of uncertainty that supports downstream control actions. We show that purely procedural reasoning can become informationally stagnant, whereas epistemic verbalization enables continued information acquisition and is critical for achieving information sufficiency. Empirical results demonstrate that strong reasoning performance is driven by uncertainty externalization rather than specific surface tokens. Our framework unifies prior findings on Aha moments and post-training experiments, and offers insights for future reasoning model design.
Beyond Normalization: Rethinking the Partition Function as a Difficulty Scheduler for RLVR
Feb 13, 2026Reward-maximizing RL methods enhance the reasoning performance of LLMs, but often reduce the diversity among outputs. Recent works address this issue by adopting GFlowNets, training LLMs to match a target distribution while jointly learning its partition function. In contrast to prior works that treat this partition function solely as a normalizer, we reinterpret it as a per-prompt expected-reward (i.e., online accuracy) signal, leveraging this unused information to improve sample efficiency. Specifically, we first establish a theoretical relationship between the partition function and per-prompt accuracy estimates. Building on this key insight, we propose Partition Function-Guided RL (PACED-RL), a post-training framework that leverages accuracy estimates to prioritize informative question prompts during training, and further improves sample efficiency through an accuracy estimate error-prioritized replay. Crucially, both components reuse information already produced during GFlowNet training, effectively amortizing the compute overhead into the existing optimization process. Extensive experiments across diverse benchmarks demonstrate strong performance improvements over GRPO and prior GFlowNet approaches, highlighting PACED-RL as a promising direction for a more sample efficient distribution-matching training for LLMs.
CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal Attribution
Feb 08, 2026AI agents equipped with tool-calling capabilities are susceptible to Indirect Prompt Injection (IPI) attacks. In this attack scenario, malicious commands hidden within untrusted content trick the agent into performing unauthorized actions. Existing defenses can reduce attack success but often suffer from the over-defense dilemma: they deploy expensive, always-on sanitization regardless of actual threat, thereby degrading utility and latency even in benign scenarios. We revisit IPI through a causal ablation perspective: a successful injection manifests as a dominance shift where the user request no longer provides decisive support for the agent's privileged action, while a particular untrusted segment, such as a retrieved document or tool output, provides disproportionate attributable influence. Based on this signature, we propose CausalArmor, a selective defense framework that (i) computes lightweight, leave-one-out ablation-based attributions at privileged decision points, and (ii) triggers targeted sanitization only when an untrusted segment dominates the user intent. Additionally, CausalArmor employs retroactive Chain-of-Thought masking to prevent the agent from acting on ``poisoned'' reasoning traces. We present a theoretical analysis showing that sanitization based on attribution margins conditionally yields an exponentially small upper bound on the probability of selecting malicious actions. Experiments on AgentDojo and DoomArena demonstrate that CausalArmor matches the security of aggressive defenses while improving explainability and preserving utility and latency of AI agents.
Benign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
May 21, 2025Recent advances in LLM agents have largely built on reasoning backbones like ReAct, which interleave thought and action in complex environments. However, ReAct often produces ungrounded or incoherent reasoning steps, leading to misalignment between the agent's actual state and goal. Our analysis finds that this stems from ReAct's inability to maintain consistent internal beliefs and goal alignment, causing compounding errors and hallucinations. To address this, we introduce ReflAct, a novel backbone that shifts reasoning from merely planning next actions to continuously reflecting on the agent's state relative to its goal. By explicitly grounding decisions in states and enforcing ongoing goal alignment, ReflAct dramatically improves strategic reliability. This design delivers substantial empirical gains: ReflAct surpasses ReAct by 27.7% on average, achieving a 93.3% success rate in ALFWorld. Notably, ReflAct even outperforms ReAct with added enhancement modules (e.g., Reflexion, WKM), showing that strengthening the core reasoning backbone is key to reliable agent performance.
Drift: Decoding-time Personalized Alignments with Implicit User Preferences
Feb 21, 2025



Personalized alignments for individual users have been a long-standing goal in large language models (LLMs). We introduce Drift, a novel framework that personalizes LLMs at decoding time with implicit user preferences. Traditional Reinforcement Learning from Human Feedback (RLHF) requires thousands of annotated examples and expensive gradient updates. In contrast, Drift personalizes LLMs in a training-free manner, using only a few dozen examples to steer a frozen model through efficient preference modeling. Our approach models user preferences as a composition of predefined, interpretable attributes and aligns them at decoding time to enable personalized generation. Experiments on both a synthetic persona dataset (Perspective) and a real human-annotated dataset (PRISM) demonstrate that Drift significantly outperforms RLHF baselines while using only 50-100 examples. Our results and analysis show that Drift is both computationally efficient and interpretable.
Doubly-Universal Adversarial Perturbations: Deceiving Vision-Language Models Across Both Images and Text with a Single Perturbation
Dec 11, 2024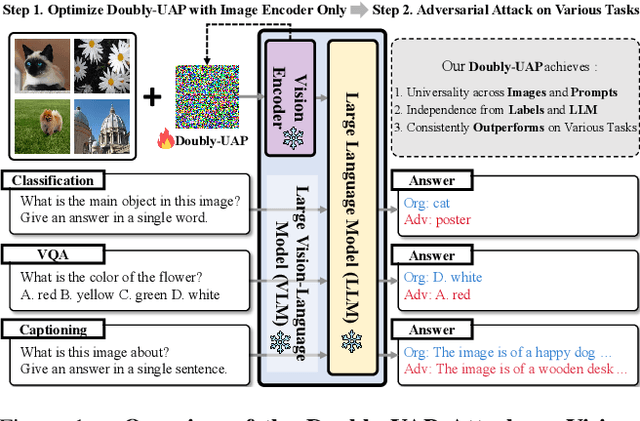
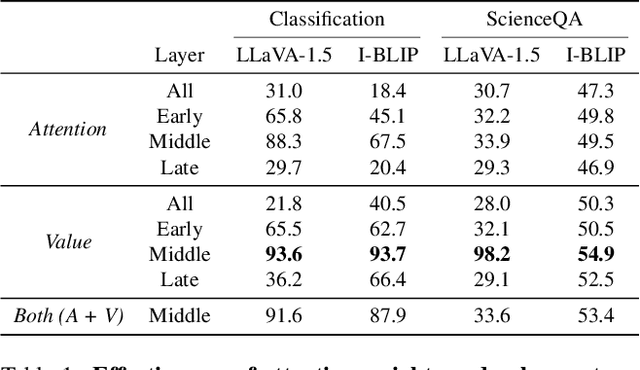
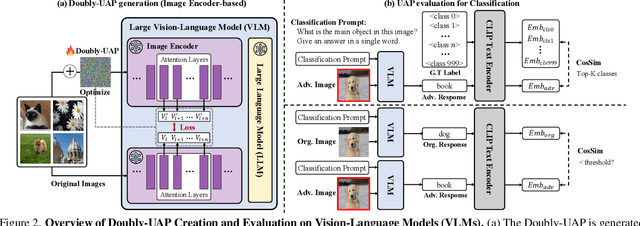

Large Vision-Language Models (VLMs) have demonstrated remarkable performance across multimodal tasks by integrating vision encoders with large language models (LLMs). However, these models remain vulnerable to adversarial attacks. Among such attacks, Universal Adversarial Perturbations (UAPs) are especially powerful, as a single optimized perturbation can mislead the model across various input images. In this work, we introduce a novel UAP specifically designed for VLMs: the Doubly-Universal Adversarial Perturbation (Doubly-UAP), capable of universally deceiving VLMs across both image and text inputs. To successfully disrupt the vision encoder's fundamental process, we analyze the core components of the attention mechanism. After identifying value vectors in the middle-to-late layers as the most vulnerable, we optimize Doubly-UAP in a label-free manner with a frozen model. Despite being developed as a black-box to the LLM, Doubly-UAP achieves high attack success rates on VLMs, consistently outperforming baseline methods across vision-language tasks. Extensive ablation studies and analyses further demonstrate the robustness of Doubly-UAP and provide insights into how it influences internal attention mechanisms.