 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Singular points detection with semantic segmentation networks
Nov 04, 2019

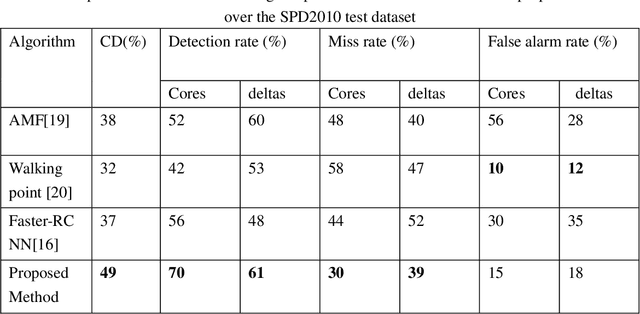

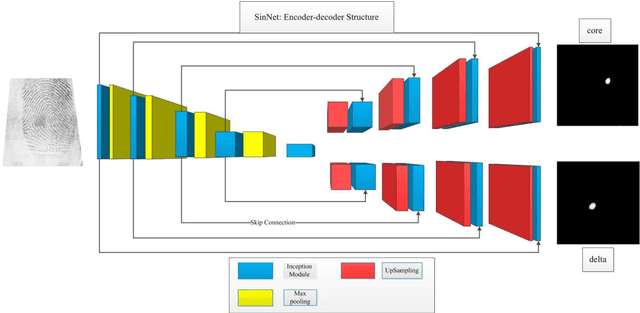
Singular points detection is one of the most classical and important problem in the field of fingerprint recognition. However, current detection rates of singular points are still unsatisfactory, especially for low-quality fingerprints. Compared with traditional image processing-based detection methods, methods based on deep learning only need the original fingerprint image but not the fingerprint orientation field. In this paper, different from other detection methods based on deep learning, we treat singular points detection as a semantic segmentation problem and just use few data for training. Furthermore, we propose a new convolutional neural network called SinNet to extract the singular regions of interest and then use a blob detection method called SimpleBlobDetector to locate the singular points. The experiments are carried out on the test dataset from SPD2010, and the proposed method has much better performance than the other advanced methods in most aspects. Compared with the state-of-art algorithms in SPD2010, our method achieves an increase of 11% in the percentage of correctly detected fingerprints and an increase of more than 18% in the core detection rate.
Color Image Enhancement Using the lrgb Coordinates in the Context of Support Fuzzification
Feb 16, 2015

Image enhancement is an important stage in the image-processing domain. The most known image enhancement method is the histogram equalization. This method is an automated one, and realizes a simultaneous modification for brightness and contrast in the case of monochrome images and for brightness, contrast, saturation and hue in the case of color images. Simple and efficient methods can be obtained if affine transforms within logarithmic models are used. A very important thing in the affine transform determination for color images is the coordinate system that is used for color space representation. Thus, the using of the RGB coordinates leads to a simultaneous modification of luminosity and saturation. In this paper using the lrgb perceptual coordinates one can define affine transforms, which allow a separated modification of luminosity l and saturation s (saturation being calculated with the component rgb in the chromatic plane). Better results can be obtained if partitions are defined on the image support and then the pixels are separately processed in each window belonging to the defined partition. Classical partitions frequently lead to the appearance of some discontinuities at the boundaries between these windows. In order to avoid all these drawbacks the classical partitions may be replaced by fuzzy partitions. Their elements will be fuzzy windows and in each of them there will be defined an affine transform induced by parameters using the fuzzy mean, fuzzy variance and fuzzy saturation computed for the pixels that belong to the analyzed window. The final image is obtained by summing up in a weight way the images of every fuzzy window.
Learning Physical Graph Representations from Visual Scenes
Jun 22, 2020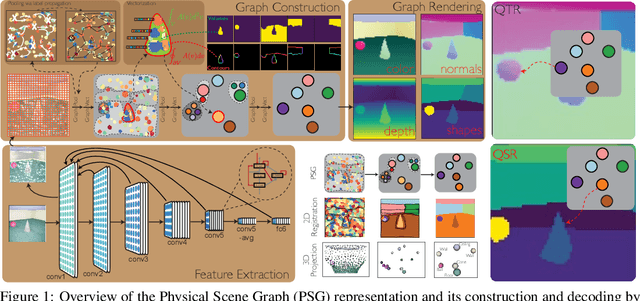
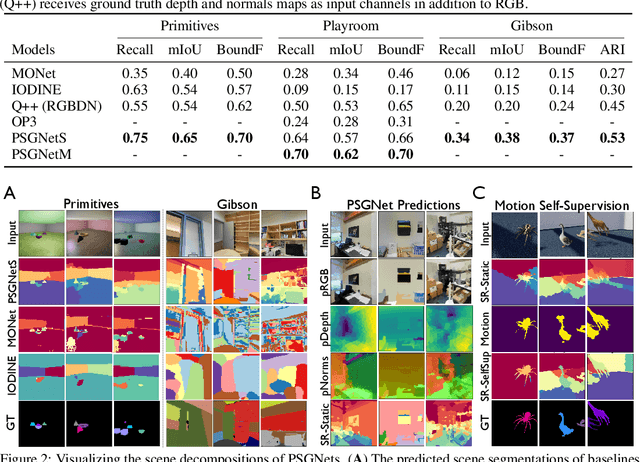
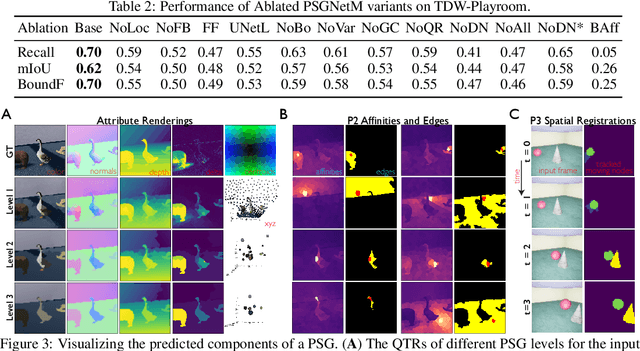

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
From Speech Chain to Multimodal Chain: Leveraging Cross-modal Data Augmentation for Semi-supervised Learning
Jun 03, 2019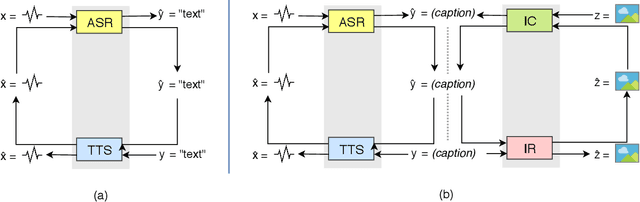
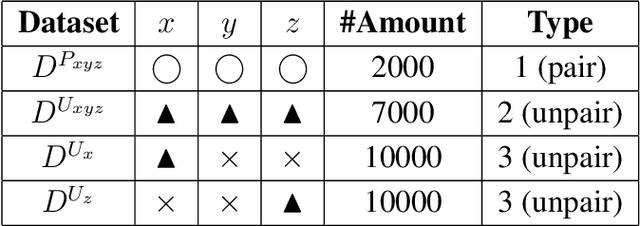
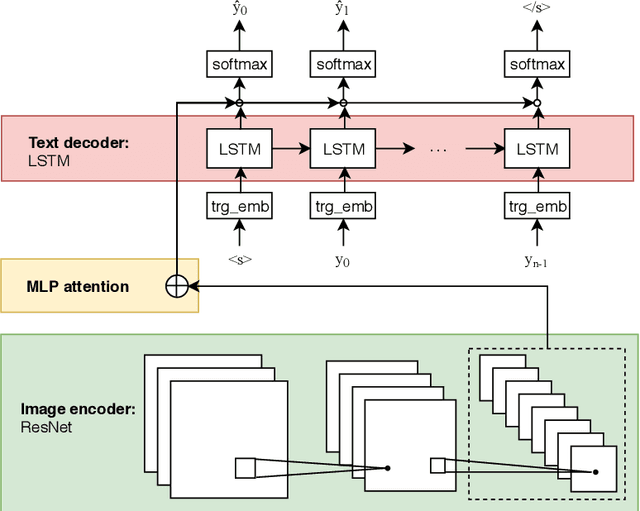
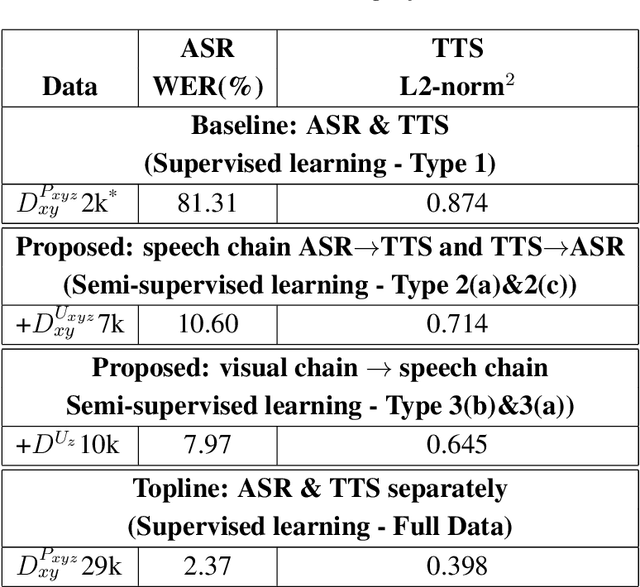
The most common way for humans to communicate is by speech. But perhaps a language system cannot know what it is communicating without a connection to the real world by image perception. In fact, humans perceive these multiple sources of information together to build a general concept. However, constructing a machine that can alleviate these modalities together in a supervised learning fashion is difficult, because a parallel dataset is required among speech, image, and text modalities altogether that is often unavailable. A machine speech chain based on sequence-to-sequence deep learning was previously proposed to achieve semi-supervised learning that enabled automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to teach each other when they receive unpaired data. In this research, we take a further step by expanding the speech chain into a multimodal chain and design a closely knit chain architecture that connects ASR, TTS, image captioning (IC), and image retrieval (IR) models into a single framework. ASR, TTS, IC, and IR components can be trained in a semi-supervised fashion by assisting each other given incomplete datasets and leveraging cross-modal data augmentation within the chain.
Data Uncertainty Learning in Face Recognition
Mar 25, 2020
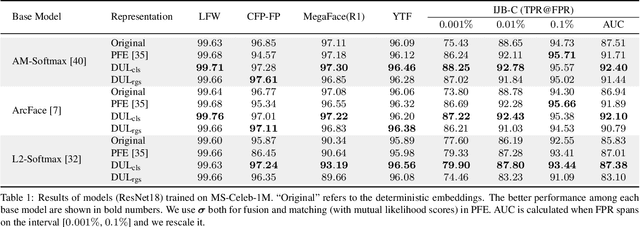
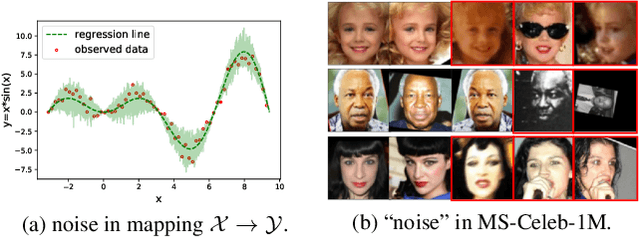
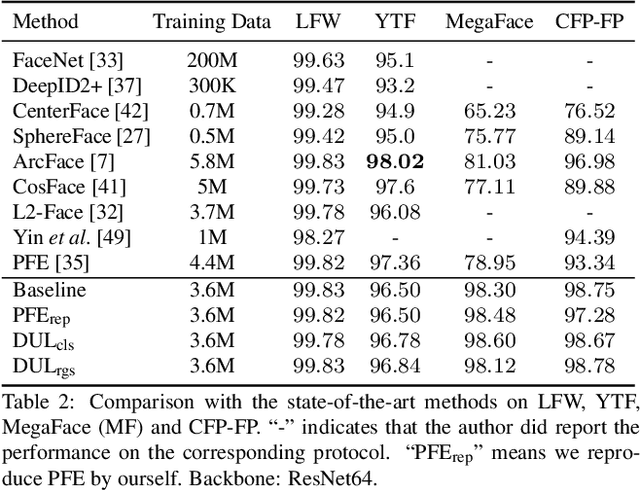
Modeling data uncertainty is important for noisy images, but seldom explored for face recognition. The pioneer work, PFE, considers uncertainty by modeling each face image embedding as a Gaussian distribution. It is quite effective. However, it uses fixed feature (mean of the Gaussian) from an existing model. It only estimates the variance and relies on an ad-hoc and costly metric. Thus, it is not easy to use. It is unclear how uncertainty affects feature learning. This work applies data uncertainty learning to face recognition, such that the feature (mean) and uncertainty (variance) are learnt simultaneously, for the first time. Two learning methods are proposed. They are easy to use and outperform existing deterministic methods as well as PFE on challenging unconstrained scenarios. We also provide insightful analysis on how incorporating uncertainty estimation helps reducing the adverse effects of noisy samples and affects the feature learning.
ResNeSt: Split-Attention Networks
Apr 19, 2020
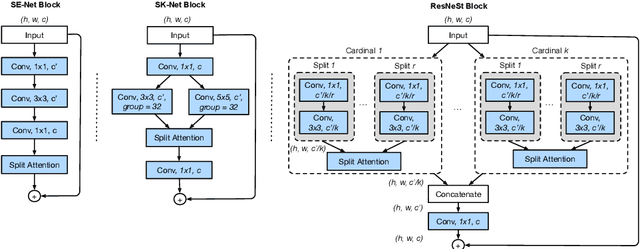
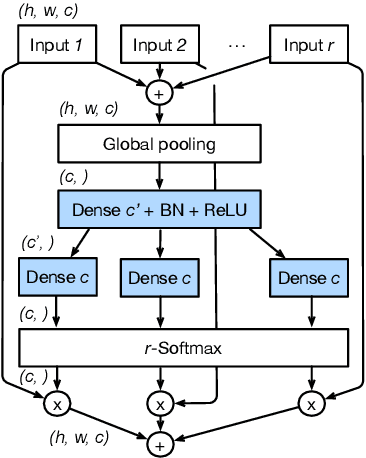
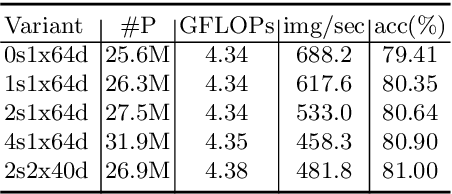
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
SCATTER: Selective Context Attentional Scene Text Recognizer
Mar 25, 2020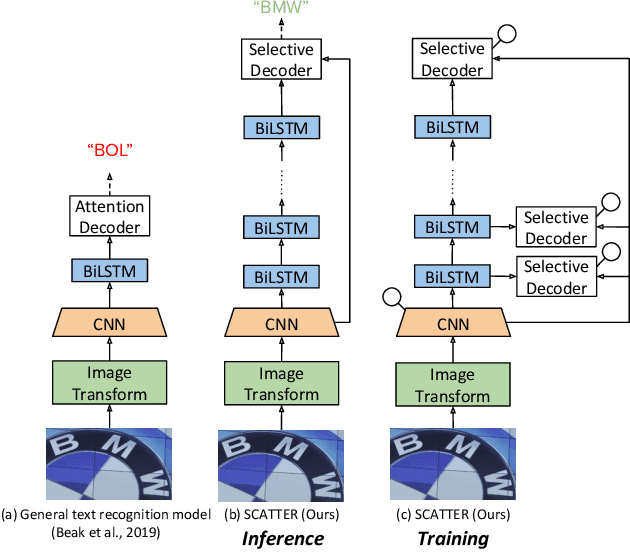
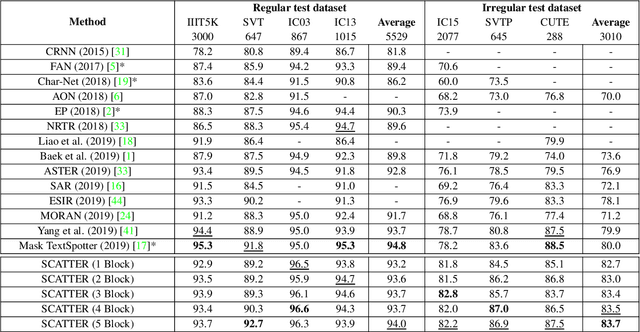
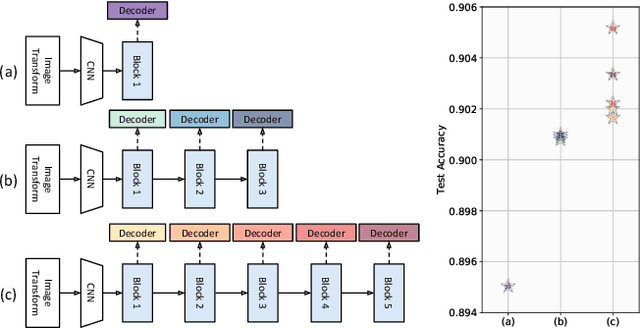
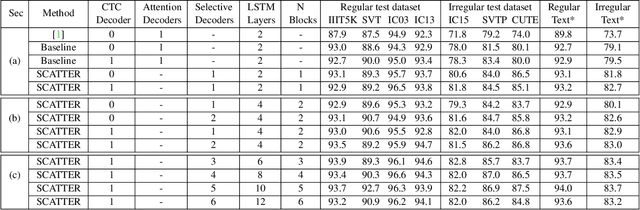
Scene Text Recognition (STR), the task of recognizing text against complex image backgrounds, is an active area of research. Current state-of-the-art (SOTA) methods still struggle to recognize text written in arbitrary shapes. In this paper, we introduce a novel architecture for STR, named Selective Context ATtentional Text Recognizer (SCATTER). SCATTER utilizes a stacked block architecture with intermediate supervision during training, that paves the way to successfully train a deep BiLSTM encoder, thus improving the encoding of contextual dependencies. Decoding is done using a two-step 1D attention mechanism. The first attention step re-weights visual features from a CNN backbone together with contextual features computed by a BiLSTM layer. The second attention step, similar to previous papers, treats the features as a sequence and attends to the intra-sequence relationships. Experiments show that the proposed approach surpasses SOTA performance on irregular text recognition benchmarks by 3.7\% on average.
Zeroth-order Optimization on Riemannian Manifolds
Mar 25, 2020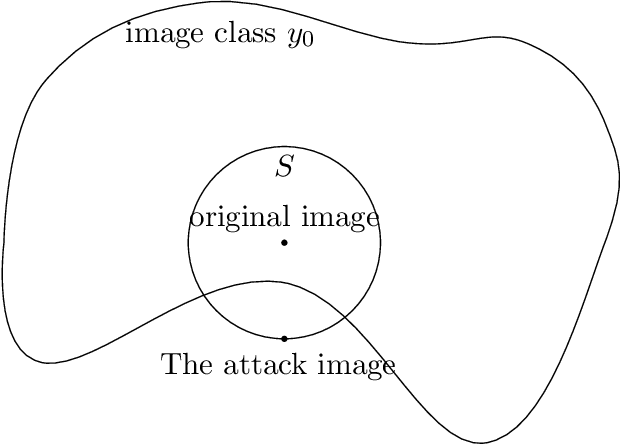
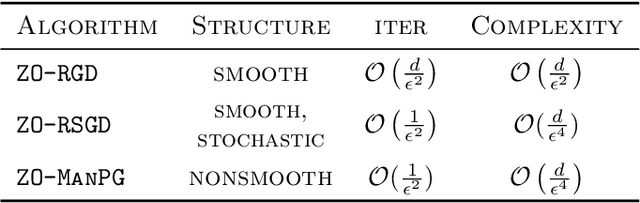

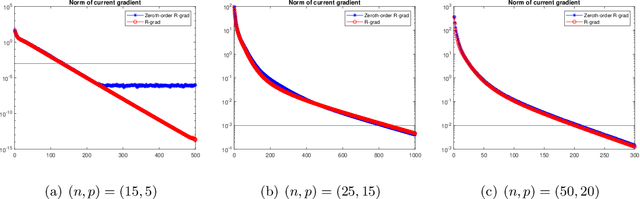
We propose and analyze zeroth-order algorithms for optimization over Riemannian manifolds, where we observe only potentially noisy evaluations of the objective function. Our approach is based on estimating the Riemannian gradient from the objective function evaluations. We consider three settings for the objective function: (i) deterministic and smooth, (ii) stochastic and smooth, and (iii) composition of smooth and non-smooth parts. For each of the setting, we characterize the oracle complexity of our algorithm to obtain appropriately defined notions of $\epsilon$-stationary points. Notably, our complexities are independent of the ambient dimension of the Euclidean space in which the manifold is embedded in, and only depend on the intrinsic dimension of the manifold. As a proof of concept, we demonstrate the applicability of our method to the problem of black-box attacks to deep neural networks, by providing simulation and real-world image data based experimental results.
On a new formulation of nonlocal image filters involving the relative rearrangement
Jun 27, 2014Nonlocal filters are simple and powerful techniques for image denoising. In this paper we study the reformulation of a broad class of nonlocal filters in terms of two functional rearrangements: the decreasing and the relative rearrangements. Independently of the dimension of the image, we reformulate these filters as integral operators defined in a one-dimensional space corresponding to the level sets measures. We prove the equivalency between the original and the rearranged versions of the filters and propose a discretization in terms of constant-wise interpolators, which we prove to be convergent to the solution of the continuous setting. For some particular cases, this new formulation allows us to perform a detailed analysis of the filtering properties. Among others, we prove that the filtered image is a contrast change of the original image, and that the filtering procedure behaves asymptotically as a shock filter combined with a border diffusive term, responsible for the staircaising effect and the loss of contrast.
Automatic Image Segmentation by Dynamic Region Merging
Dec 06, 2010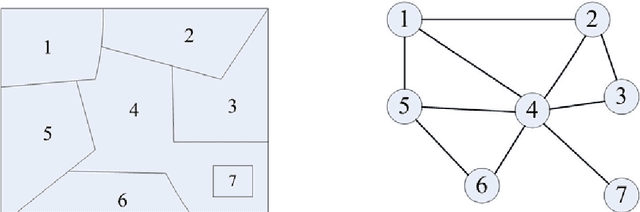

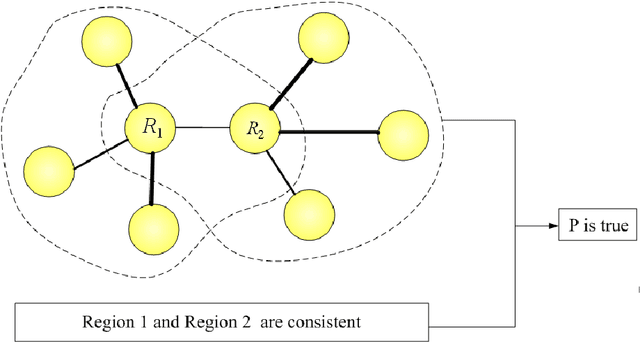

This paper addresses the automatic image segmentation problem in a region merging style. With an initially over-segmented image, in which the many regions (or super-pixels) with homogeneous color are detected, image segmentation is performed by iteratively merging the regions according to a statistical test. There are two essential issues in a region merging algorithm: order of merging and the stopping criterion. In the proposed algorithm, these two issues are solved by a novel predicate, which is defined by the sequential probability ratio test (SPRT) and the maximum likelihood criterion. Starting from an over-segmented image, neighboring regions are progressively merged if there is an evidence for merging according to this predicate. We show that the merging order follows the principle of dynamic programming. This formulates image segmentation as an inference problem, where the final segmentation is established based on the observed image. We also prove that the produced segmentation satisfies certain global properties. In addition, a faster algorithm is developed to accelerate the region merging process, which maintains a nearest neighbor graph in each iteration. Experiments on real natural images are conducted to demonstrate the performance of the proposed dynamic region merging algorithm.