 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Muon Outperforms Adam: A Curvature Perspective
Jun 03, 2026Muon improves training efficiency over Adam in large language-model training by about two times, but the local geometric source of this advantage remains unclear. Our work takes a first step toward demystifying Muon's superiority over Adam from a curvature perspective. First, we apply a second-order Taylor approximation to the training landscape and show that Muon achieves a larger one-step loss decrease than Adam at matched validation loss. The two optimizers have comparable first-order gains, but Muon consistently incurs a smaller second-order curvature penalty. Second, we decompose this curvature penalty into the squared update norm and Normalized Directional Sharpness (NDS). We find that Muon and Adam have comparable update norms, so Muon's smaller curvature penalty is driven by lower NDS, not update scale. Third, we study how training data and model structure shape Muon's NDS advantage. Using Zipf-Probabilistic Context-Free Grammar (PCFG) data with controlled imbalance, we show that data imbalance amplifies Muon's NDS advantage over Adam. A within-/cross-layer decomposition further shows that, in the middle and late stages of training, Muon's lower NDS is mainly sustained by smaller within-layer curvature. Beyond empirical evidence, we analyze stylized quadratic problems with heterogeneous curvature and gradient alignment toward high-curvature modes. We prove that Muon attains a smaller average NDS than GD by balancing update energy across curvature groups; when curvature heterogeneity is sufficiently strong, this also yields lower local quadratic loss after the same number of steps.
TPS-Drive: Task-Guided Representation Purification for VLM-based Autonomous Driving
May 26, 2026Vision-Language Models (VLMs) provide a promising foundation for autonomous driving planning, yet bridging semantic reasoning and precise 3D spatial forecasting remains a critical challenge. Existing representation strategies generally follow two paths: text-aligned methods flatten continuous spatial states into symbols, which compromises geometric structure and induces "spatial hallucinations"; dense visual methods preserve spatial topology but overwhelm standard tokenizers with redundant background textures, leading to "representation interference". To address these limitations, we introduce TPS-Drive, a novel framework centered on Task-Guided Representation Purification that empowers VLMs to Think in Purified Space. At its core, an Agent-Centric Tokenizer utilizes a task-guided vector quantization mechanism supervised by a frozen 3D detection head, which explicitly reallocates limited codebook capacity from pervasive static backgrounds to critical dynamic agents and effectively isolates spatial redundancy. Leveraging this purified spatial vocabulary, TPS-Drive employs a decoupled reasoning pipeline that sequentially performs scene understanding, future forecasting, and action generation. The framework is optimized via a progressive three-stage training paradigm, culminating in reward-driven refinement that surpasses pure imitation learning. Extensive experiments validate our approach: TPS-Drive achieves accurate agent spatial state forecasting and reduces collision rates in open-loop nuScenes evaluations, while establishing new safety records on the rigorous closed-loop NAVSIMv1 and NAVSIMv2 benchmarks.
ConFi-GS Confidence-Guided High-Frequency Injection for 3D Gaussian Splatting Super-Resolution
May 24, 2026Reconstructing high-quality 3D scenes from low-resolution multi-view images remains challenging for 3D Gaussian Splatting (3DGS), because insufficient high-frequency observations often lead to blurred textures, weak boundaries, and view-inconsistent details. Existing approaches either apply super-resolution guidance uniformly or localize enhancement regions based mainly on geometric sampling. However, they typically do not distinguish between two fundamentally different questions: where additional detail is needed, and whether the corresponding candidate high-frequency content is reliable enough to be internalized into a multi-view consistent 3D representation. In this paper, we propose a reliability-aware frequency modeling framework for low-resolution 3DGS reconstruction. The framework first estimates a geometry-guided detail-demand prior to locate regions that are likely under-detailed under low-resolution supervision. It then computes a frequency-aware reliability map to determine whether candidate high-frequency details are structurally supported, spectrally unresolved, and cross-view stable. Combining these signals yields a detail-injection map that guides where super-resolved details should be introduced during optimization. Based on this map, we design a unified optimization scheme comprising spatially selective supervision, coarse-to-fine frequency regularization, and reliability-aware Gaussian densification. This scheme controls where reliable details are injected, when high-frequency supervision is activated, and how unresolved yet reliable details are internalized into the Gaussian representation. Experiments on multiple benchmarks show improved fidelity and perceptual quality while suppressing unstable or view-inconsistent details.
Temporal Sampling Frequency Matters: A Capacity-Aware Study of End-to-End Driving Trajectory Prediction
May 11, 2026End to end (E2E) autonomous driving trajectory prediction is often trained with camera frames sampled at the highest available temporal frequency, assuming that denser sampling improves performance. We question this assumption by treating temporal sampling frequency as an explicit training set design variable. Starting from high frequency E2E driving datasets, we construct frequency sweep training sets by temporally subsampling camera frames along each trajectory. For each model dataset pair, we train and evaluate the same model under a fixed protocol, so the frequency response reflects how prediction performance changes with sampling frequency. We analyze this response from a capacity aware perspective. Sparse sampling may miss driving relevant cues, while dense sampling may add redundant visual content and off manifold noise. For finite capacity models, this can create a driving irrelevant capacity burden. We evaluate three smaller E2E models and a larger VLA style AutoVLA model on Waymo, nuScenes, and PAVE. Results show model and dataset dependent frequency responses. Smaller E2E models often show non monotonic or near plateau trends and achieve their best 3 second ADE at lower or intermediate frequencies. In contrast, AutoVLA achieves its best 3 second ADE and FDE at the highest evaluated frequency on all three datasets. Iteration matched controls suggest that the advantage of lower or intermediate frequencies for smaller models is not explained only by unequal training update counts. These findings show that temporal sampling frequency should be reported and tuned, rather than fixed to the highest available value.
Demystifying Manifold Constraints in LLM Pre-training
May 06, 2026The empirical success of large language model (LLM) pre-training relies heavily on heuristic stabilization techniques, such as explicit normalization layers and weight decay. While recent constrained optimization approaches that explicitly restrict weights may improve numerical stability and performance, the mechanism and motivation for adding constraints still remain elusive. This paper systematically demystifies the role of explicit manifold constraints in LLM pre-training. By introducing the Msign-Aligned Constrained Riemannian Optimizer (MACRO)-a provably convergent, single-loop optimization framework-our study disentangles weight regularization heuristics from interacting mechanisms like RMS normalization and decoupled weight decay. Theoretical analyses and comprehensive empirical evaluations reveal that manifold constraints independently bound forward activation scales and enforce stable rotational equilibrium, thereby subsuming the roles of these heuristic mechanisms. Evaluations on large-scale LLM architectures demonstrate that MACRO achieves highly competitive performance while rigorously preserving the theoretical guarantees of exact Riemannian optimization.
DTP-Attack: A decision-based black-box adversarial attack on trajectory prediction
Mar 27, 2026Trajectory prediction systems are critical for autonomous vehicle safety, yet remain vulnerable to adversarial attacks that can cause catastrophic traffic behavior misinterpretations. Existing attack methods require white-box access with gradient information and rely on rigid physical constraints, limiting real-world applicability. We propose DTP-Attack, a decision-based black-box adversarial attack framework tailored for trajectory prediction systems. Our method operates exclusively on binary decision outputs without requiring model internals or gradients, making it practical for real-world scenarios. DTP-Attack employs a novel boundary walking algorithm that navigates adversarial regions without fixed constraints, naturally maintaining trajectory realism through proximity preservation. Unlike existing approaches, our method supports both intention misclassification attacks and prediction accuracy degradation. Extensive evaluation on nuScenes and Apolloscape datasets across state-of-the-art models including Trajectron++ and Grip++ demonstrates superior performance. DTP-Attack achieves 41 - 81% attack success rates for intention misclassification attacks that manipulate perceived driving maneuvers with perturbations below 0.45 m, and increases prediction errors by 1.9 - 4.2 for accuracy degradation. Our method consistently outperforms existing black-box approaches while maintaining high controllability and reliability across diverse scenarios. These results reveal fundamental vulnerabilities in current trajectory prediction systems, highlighting urgent needs for robust defenses in safety-critical autonomous driving applications.
A Framework for Quantifying How Pre-Training and Context Benefit In-Context Learning
Oct 26, 2025



Pre-trained large language models have demonstrated a strong ability to learn from context, known as in-context learning (ICL). Despite a surge of recent applications that leverage such capabilities, it is by no means clear, at least theoretically, how the ICL capabilities arise, and in particular, what is the precise role played by key factors such as pre-training procedure as well as context construction. In this work, we propose a new framework to analyze the ICL performance, for a class of realistic settings, which includes network architectures, data encoding, data generation, and prompt construction process. As a first step, we construct a simple example with a one-layer transformer, and show an interesting result, namely when the pre-train data distribution is different from the query task distribution, a properly constructed context can shift the output distribution towards the query task distribution, in a quantifiable manner, leading to accurate prediction on the query topic. We then extend the findings in the previous step to a more general case, and derive the precise relationship between ICL performance, context length and the KL divergence between pre-train and query task distribution. Finally, we provide experiments to validate our theoretical results.
Federated Learning on Riemannian Manifolds: A Gradient-Free Projection-Based Approach
Jul 30, 2025Federated learning (FL) has emerged as a powerful paradigm for collaborative model training across distributed clients while preserving data privacy. However, existing FL algorithms predominantly focus on unconstrained optimization problems with exact gradient information, limiting its applicability in scenarios where only noisy function evaluations are accessible or where model parameters are constrained. To address these challenges, we propose a novel zeroth-order projection-based algorithm on Riemannian manifolds for FL. By leveraging the projection operator, we introduce a computationally efficient zeroth-order Riemannian gradient estimator. Unlike existing estimators, ours requires only a simple Euclidean random perturbation, eliminating the need to sample random vectors in the tangent space, thus reducing computational cost. Theoretically, we first prove the approximation properties of the estimator and then establish the sublinear convergence of the proposed algorithm, matching the rate of its first-order counterpart. Numerically, we first assess the efficiency of our estimator using kernel principal component analysis. Furthermore, we apply the proposed algorithm to two real-world scenarios: zeroth-order attacks on deep neural networks and low-rank neural network training to validate the theoretical findings.
Scalable Parameter and Memory Efficient Pretraining for LLM: Recent Algorithmic Advances and Benchmarking
May 28, 2025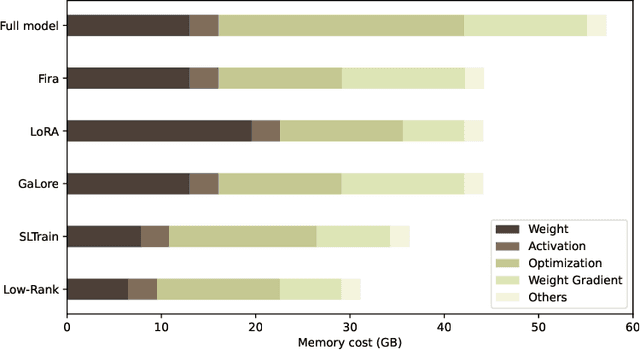



Fueled by their remarkable ability to tackle diverse tasks across multiple domains, large language models (LLMs) have grown at an unprecedented rate, with some recent models containing trillions of parameters. This growth is accompanied by substantial computational challenges, particularly regarding the memory and compute resources required for training and fine-tuning. Numerous approaches have been explored to address these issues, such as LoRA. While these methods are effective for fine-tuning, their application to pre-training is significantly more challenging due to the need to learn vast datasets. Motivated by this issue, we aim to address the following questions: Can parameter- or memory-efficient methods enhance pre-training efficiency while achieving performance comparable to full-model training? How can the performance gap be narrowed? To this end, the contributions of this work are the following. (1) We begin by conducting a comprehensive survey that summarizes state-of-the-art methods for efficient pre-training. (2) We perform a benchmark evaluation of several representative memory efficient pre-training approaches to comprehensively evaluate their performance across model sizes. We observe that with a proper choice of optimizer and hyperparameters, full-rank training delivers the best performance, as expected. We also notice that incorporating high-rank updates in low-rank approaches is the key to improving their performance. (3) Finally, we propose two practical techniques, namely weight refactorization and momentum reset, to enhance the performance of efficient pre-training methods. We observe that applying these techniques to the low-rank method (on a 1B model) can achieve a lower perplexity than popular memory efficient algorithms such as GaLore and Fira, while simultaneously using about 25% less memory.
Enhancing the Efficiency of Complex Systems Crystal Structure Prediction by Active Learning Guided Machine Learning Potential
May 13, 2025Understanding multicomponent complex material systems is essential for design of advanced materials for a wide range of technological applications. While state-of-the-art crystal structure prediction (CSP) methods effectively identify new structures and assess phase stability, they face fundamental limitations when applied to complex systems. This challenge stems from the combinatorial explosion of atomic configurations and the vast stoichiometric space, both of which contribute to computational demands that rapidly exceed practical feasibility. In this work, we propose a flexible and automated workflow to build a highly generalizable and data-efficient machine learning potential (MLP), effectively unlocking the full potential of CSP algorithms. The workflow is validated on both Mg-Ca-H ternary and Be-P-N-O quaternary systems, demonstrating substantial machine learning acceleration in high-throughput structural optimization and enabling the efficient identification of promising compounds. These results underscore the effectiveness of our approach in exploring complex material systems and accelerating the discovery of new multicomponent materials.