 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One Size Fits All: Can We Train One Denoiser for All Noise Levels?
Jun 23, 2020
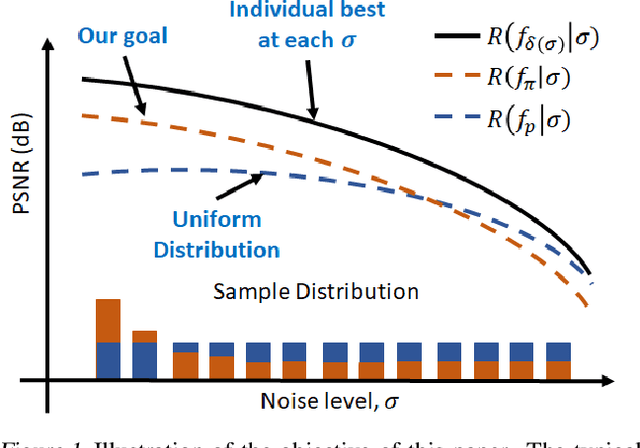
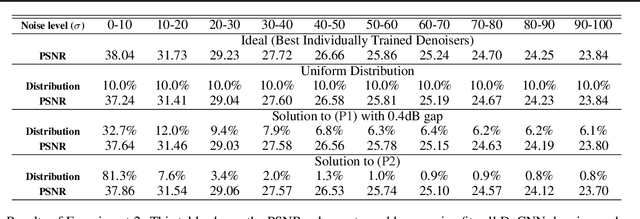
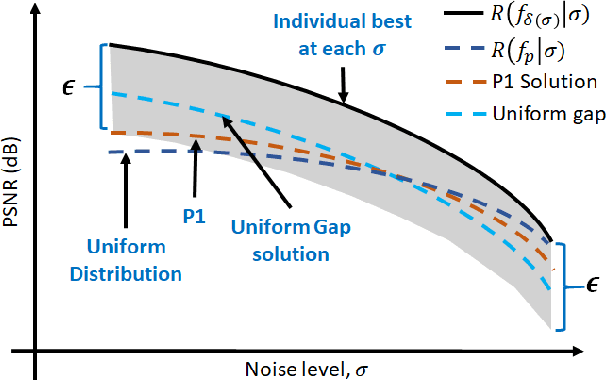
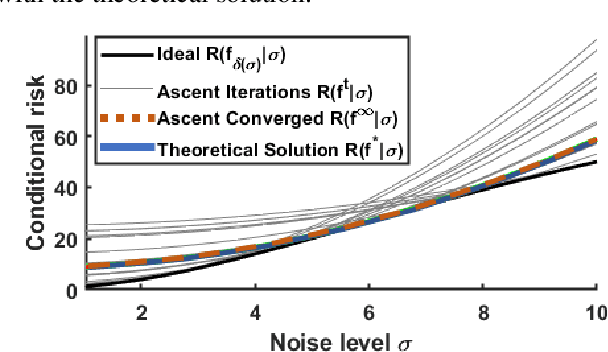
When training an estimator such as a neural network for tasks like image denoising, it is often preferred to train \emph{one} estimator and apply it to \emph{all} noise levels. The de facto training protocol to achieve this goal is to train the estimator with noisy samples whose noise levels are uniformly distributed across the range of interest. However, why should we allocate the samples uniformly? Can we have more training samples that are less noisy, and fewer samples that are more noisy? What is the optimal distribution? How do we obtain such a distribution? The goal of this paper is to address this training sample distribution problem from a minimax risk optimization perspective. We derive a dual ascent algorithm to determine the optimal sampling distribution of which the convergence is guaranteed as long as the set of admissible estimators is closed and convex. For estimators with non-convex admissible sets such as deep neural networks, our dual formulation converges to a solution of the convex relaxation. We discuss how the algorithm can be implemented in practice. We evaluate the algorithm on linear estimators and deep networks.
Calibrated neighborhood aware confidence measure for deep metric learning
Jun 08, 2020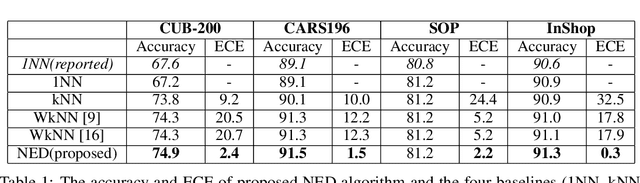
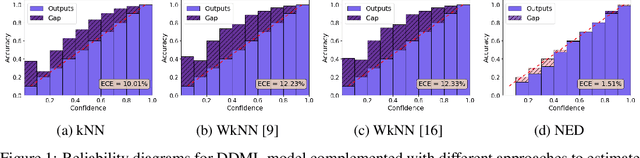
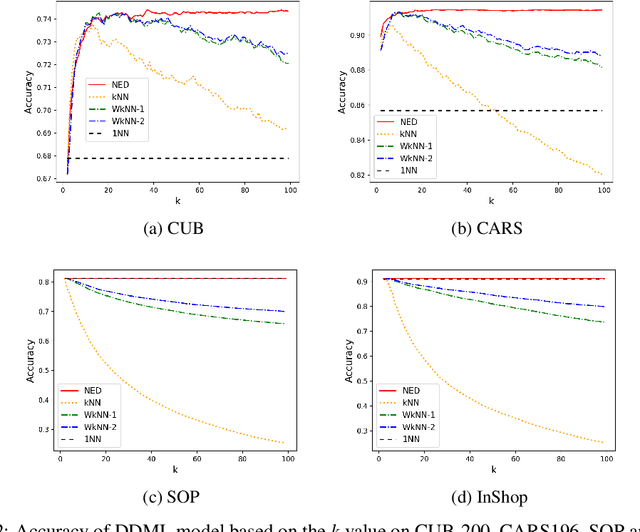
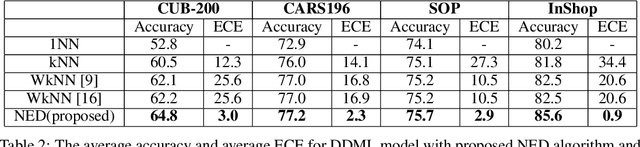
Deep metric learning has gained promising improvement in recent years following the success of deep learning. It has been successfully applied to problems in few-shot learning, image retrieval, and open-set classifications. However, measuring the confidence of a deep metric learning model and identifying unreliable predictions is still an open challenge. This paper focuses on defining a calibrated and interpretable confidence metric that closely reflects its classification accuracy. While performing similarity comparison directly in the latent space using the learned distance metric, our approach approximates the distribution of data points for each class using a Gaussian kernel smoothing function. The post-processing calibration algorithm with proposed confidence metric on the held-out validation dataset improves generalization and robustness of state-of-the-art deep metric learning models while provides an interpretable estimation of the confidence. Extensive tests on four popular benchmark datasets (Caltech-UCSD Birds, Stanford Online Product, Stanford Car-196, and In-shop Clothes Retrieval) show consistent improvements even at the presence of distribution shifts in test data related to additional noise or adversarial examples.
BreastScreening: On the Use of Multi-Modality in Medical Imaging Diagnosis
Apr 07, 2020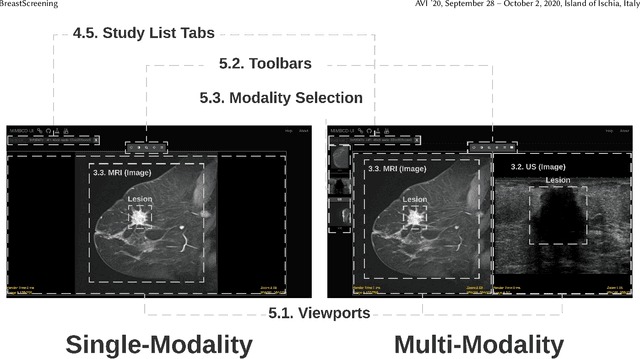
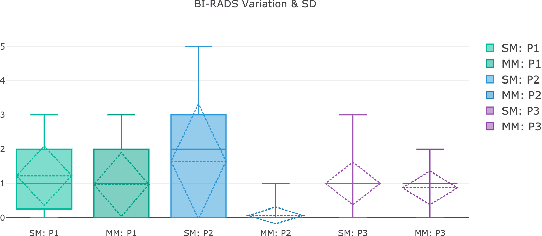
This paper describes the field research, design and comparative deployment of a multimodal medical imaging user interface for breast screening. The main contributions described here are threefold: 1) The design of an advanced visual interface for multimodal diagnosis of breast cancer (BreastScreening); 2) Insights from the field comparison of single vs multimodality screening of breast cancer diagnosis with 31 clinicians and 566 images, and 3) The visualization of the two main types of breast lesions in the following image modalities: (i) MammoGraphy (MG) in both Craniocaudal (CC) and Mediolateral oblique (MLO) views; (ii) UltraSound (US); and (iii) Magnetic Resonance Imaging (MRI). We summarize our work with recommendations from the radiologists for guiding the future design of medical imaging interfaces.
Benefits of temporal information for appearance-based gaze estimation
May 24, 2020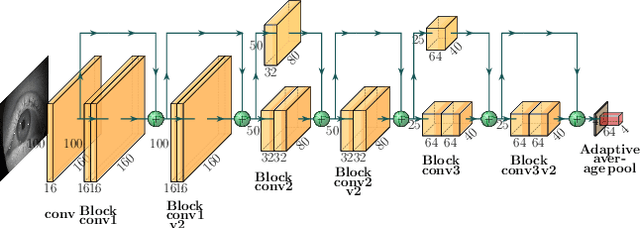
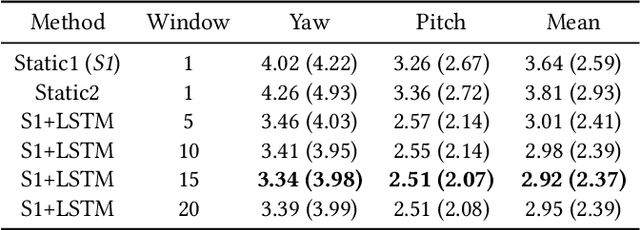
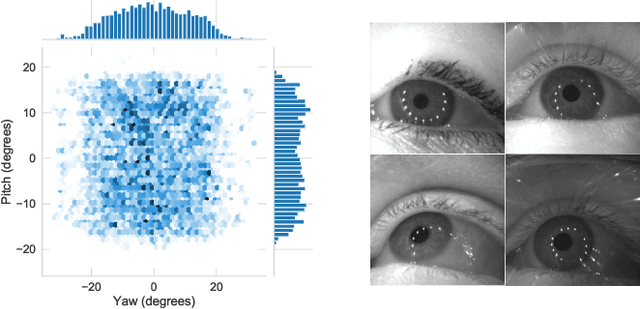
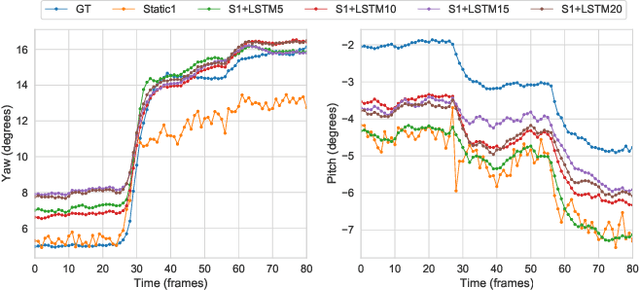
State-of-the-art appearance-based gaze estimation methods, usually based on deep learning techniques, mainly rely on static features. However, temporal trace of eye gaze contains useful information for estimating a given gaze point. For example, approaches leveraging sequential eye gaze information when applied to remote or low-resolution image scenarios with off-the-shelf cameras are showing promising results. The magnitude of contribution from temporal gaze trace is yet unclear for higher resolution/frame rate imaging systems, in which more detailed information about an eye is captured. In this paper, we investigate whether temporal sequences of eye images, captured using a high-resolution, high-frame rate head-mounted virtual reality system, can be leveraged to enhance the accuracy of an end-to-end appearance-based deep-learning model for gaze estimation. Performance is compared against a static-only version of the model. Results demonstrate statistically-significant benefits of temporal information, particularly for the vertical component of gaze.
Learning Guided Convolutional Network for Depth Completion
Aug 03, 2019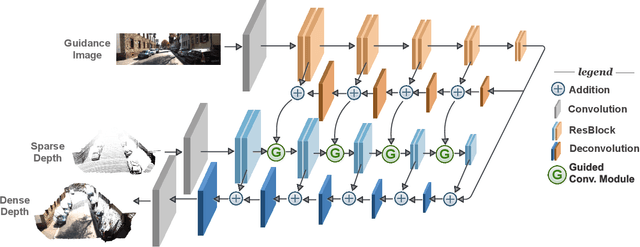
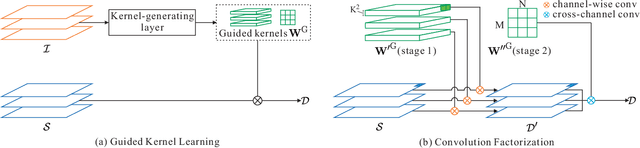


Dense depth perception is critical for autonomous driving and other robotics applications. However, modern LiDAR sensors only provide sparse depth measurement. It is thus necessary to complete the sparse LiDAR data, where a synchronized guidance RGB image is often used to facilitate this completion. Many neural networks have been designed for this task. However, they often na\"{\i}vely fuse the LiDAR data and RGB image information by performing feature concatenation or element-wise addition. Inspired by the guided image filtering, we design a novel guided network to predict kernel weights from the guidance image. These predicted kernels are then applied to extract the depth image features. In this way, our network generates content-dependent and spatially-variant kernels for multi-modal feature fusion. Dynamically generated spatially-variant kernels could lead to prohibitive GPU memory consumption and computation overhead. We further design a convolution factorization to reduce computation and memory consumption. The GPU memory reduction makes it possible for feature fusion to work in multi-stage scheme. We conduct comprehensive experiments to verify our method on real-world outdoor, indoor and synthetic datasets. Our method produces strong results. It outperforms state-of-the-art methods on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. It also presents strong generalization capability under different 3D point densities, various lighting and weather conditions as well as cross-dataset evaluations. The code will be released for reproduction.
Probabilistic Semantic Mapping for Urban Autonomous Driving Applications
Jun 08, 2020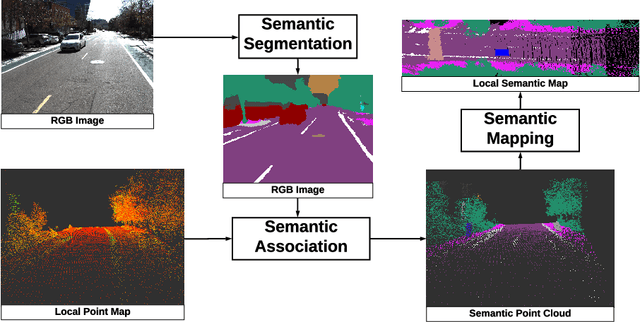
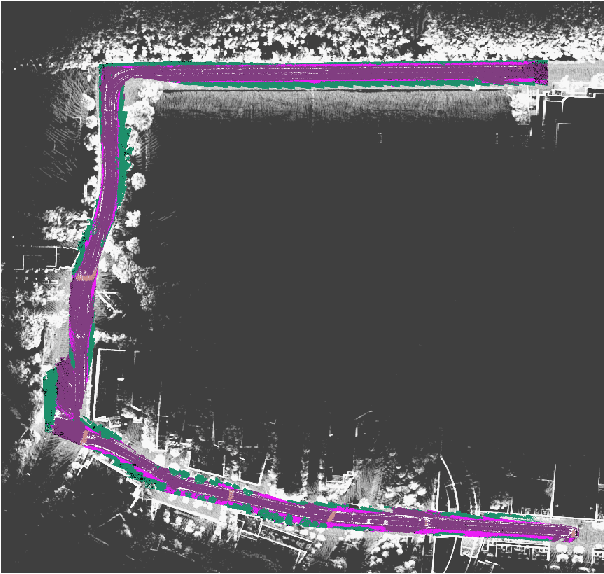

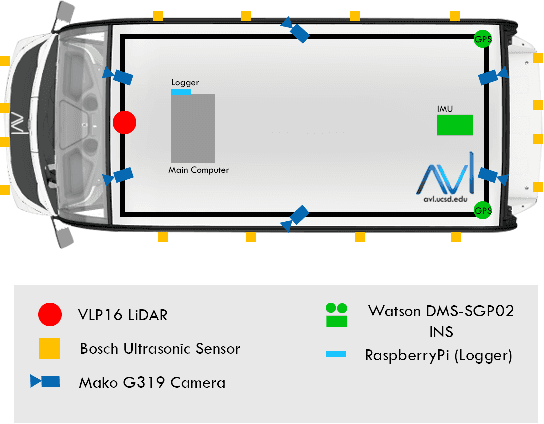
Recent advancement in statistical learning and computational ability has enabled autonomous vehicle technology to develop at a much faster rate and become widely adopted. While many of the architectures previously introduced are capable of operating under highly dynamic environments, many of these are constrained to smaller-scale deployments and require constant maintenance due to the associated scalability cost with high-definition (HD) maps. HD maps provide critical information for self-driving cars to drive safely. However, traditional approaches for creating HD maps involves tedious manual labeling. As an attempt to tackle this problem, we fuse 2D image semantic segmentation with pre-built point cloud maps collected from a relatively inexpensive 16 channel LiDAR sensor to construct a local probabilistic semantic map in bird's eye view that encodes static landmarks such as roads, sidewalks, crosswalks, and lanes in the driving environment. Experiments from data collected in an urban environment show that this model can be extended for automatically incorporating road features into HD maps with potential future work directions.
Matching Neuromorphic Events and Color Images via Adversarial Learning
Mar 02, 2020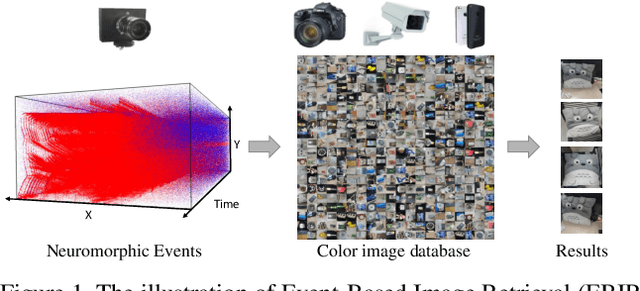
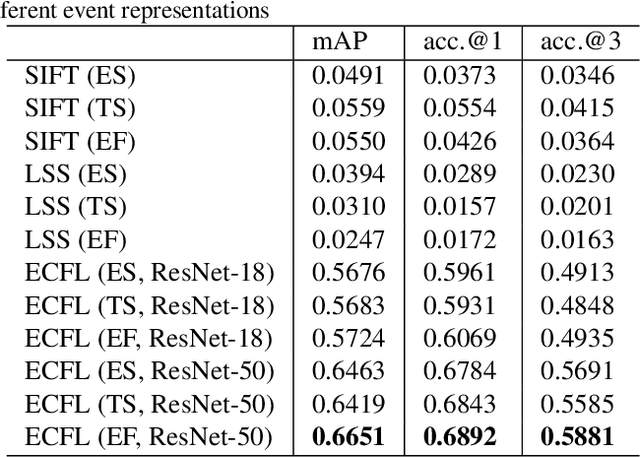
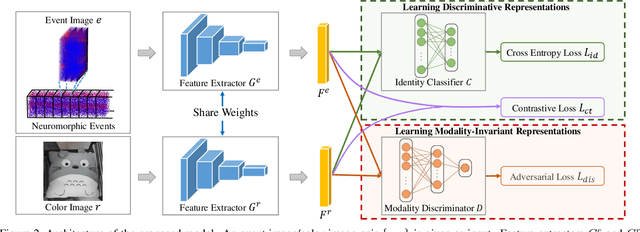
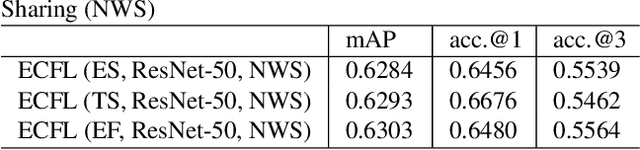
The event camera has appealing properties: high dynamic range, low latency, low power consumption and low memory usage, and thus provides complementariness to conventional frame-based cameras. It only captures the dynamics of a scene and is able to capture almost "continuous" motion. However, different from frame-based camera that reflects the whole appearance as scenes are, the event camera casts away the detailed characteristics of objects, such as texture and color. To take advantages of both modalities, the event camera and frame-based camera are combined together for various machine vision tasks. Then the cross-modal matching between neuromorphic events and color images plays a vital and essential role. In this paper, we propose the Event-Based Image Retrieval (EBIR) problem to exploit the cross-modal matching task. Given an event stream depicting a particular object as query, the aim is to retrieve color images containing the same object. This problem is challenging because there exists a large modality gap between neuromorphic events and color images. We address the EBIR problem by proposing neuromorphic Events-Color image Feature Learning (ECFL). Particularly, the adversarial learning is employed to jointly model neuromorphic events and color images into a common embedding space. We also contribute to the community N-UKbench and EC180 dataset to promote the development of EBIR problem. Extensive experiments on our datasets show that the proposed method is superior in learning effective modality-invariant representation to link two different modalities.
KiU-Net: Towards Accurate Segmentation of Biomedical Images using Over-complete Representations
Jun 08, 2020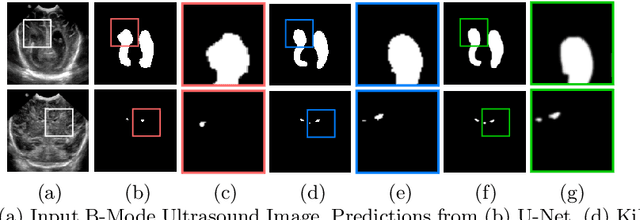
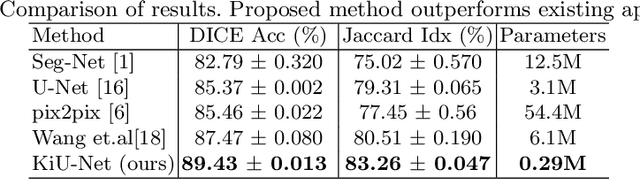
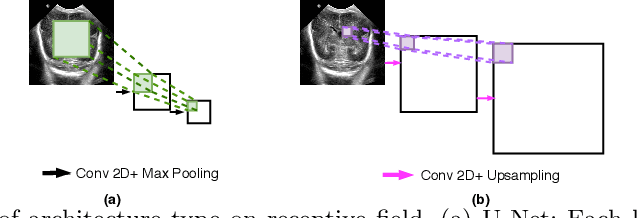

Due to its excellent performance, U-Net is the most widely used backbone architecture for biomedical image segmentation in the recent years. However, in our studies, we observe that there is a considerable performance drop in the case of detecting smaller anatomical landmarks with blurred noisy boundaries. We analyze this issue in detail, and address it by proposing an over-complete architecture (Ki-Net) which involves projecting the data onto higher dimensions (in the spatial sense). This network, when augmented with U-Net, results in significant improvements in the case of segmenting small anatomical landmarks and blurred noisy boundaries while obtaining better overall performance. Furthermore, the proposed network has additional benefits like faster convergence and fewer number of parameters. We evaluate the proposed method on the task of brain anatomy segmentation from 2D Ultrasound (US) of preterm neonates, and achieve an improvement of around 4% in terms of the DICE accuracy and Jaccard index as compared to the standard-U-Net, while outperforming the recent best methods by 2%. Code: https://github.com/jeya-maria-jose/KiU-Net-pytorch .
Human-Aware Motion Deblurring
Jan 19, 2020


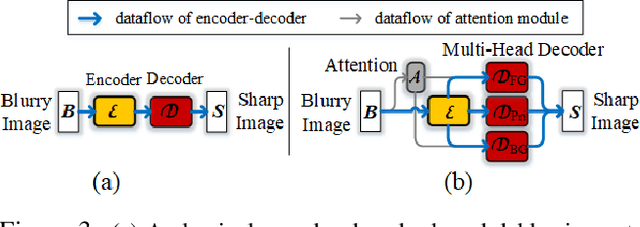
This paper proposes a human-aware deblurring model that disentangles the motion blur between foreground (FG) humans and background (BG). The proposed model is based on a triple-branch encoder-decoder architecture. The first two branches are learned for sharpening FG humans and BG details, respectively; while the third one produces global, harmonious results by comprehensively fusing multi-scale deblurring information from the two domains. The proposed model is further endowed with a supervised, human-aware attention mechanism in an end-to-end fashion. It learns a soft mask that encodes FG human information and explicitly drives the FG/BG decoder-branches to focus on their specific domains. To further benefit the research towards Human-aware Image Deblurring, we introduce a large-scale dataset, named HIDE, which consists of 8,422 blurry and sharp image pairs with 65,784 densely annotated FG human bounding boxes. HIDE is specifically built to span a broad range of scenes, human object sizes, motion patterns, and background complexities. Extensive experiments on public benchmarks and our dataset demonstrate that our model performs favorably against the state-of-the-art motion deblurring methods, especially in capturing semantic details.
Biomechanics-informed Neural Networks for Myocardial Motion Tracking in MRI
Jun 08, 2020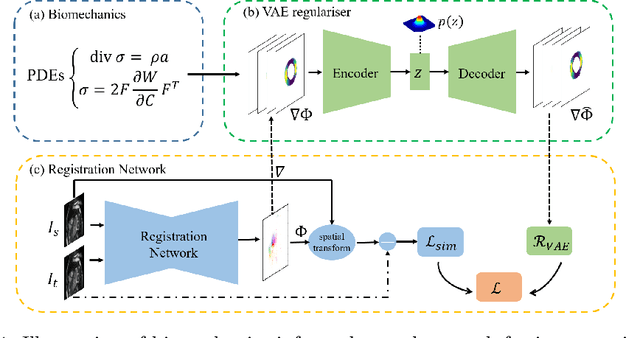
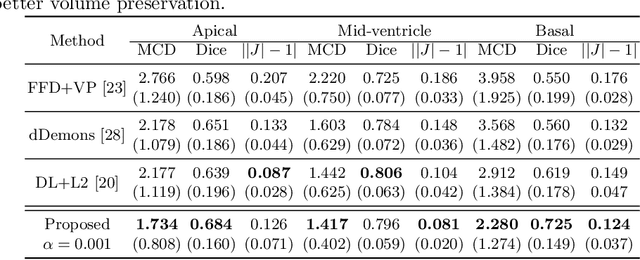
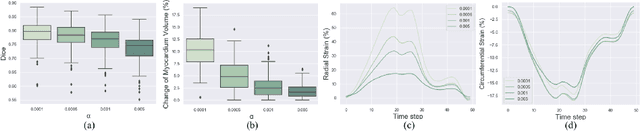
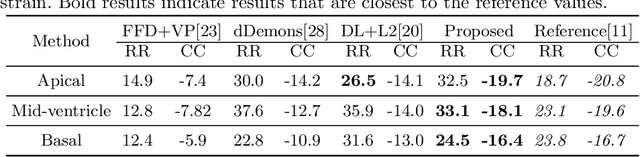
Image registration is an ill-posed inverse problem which often requires regularisation on the solution space. In contrast to most of the current approaches which impose explicit regularisation terms such as smoothness, in this paper we propose a novel method that can implicitly learn biomechanics-informed regularisation. Such an approach can incorporate application-specific prior knowledge into deep learning based registration. Particularly, the proposed biomechanics-informed regularisation leverages a variational autoencoder (VAE) to learn a manifold for biomechanically plausible deformations and to implicitly capture their underlying properties via reconstructing biomechanical simulations. The learnt VAE regulariser then can be coupled with any deep learning based registration network to regularise the solution space to be biomechanically plausible. The proposed method is validated in the context of myocardial motion tracking in cardiac MRI data. The results show that it can achieve better performance against other competing methods in terms of motion tracking accuracy and has the ability to learn biomechanical properties such as incompressibility and strains. The method has also been shown to have better generalisability to unseen domains compared with commonly used L2 regularisation schemes.