 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
System to Integrate Fairness Transparently: An Industry Approach
Jun 10, 2020
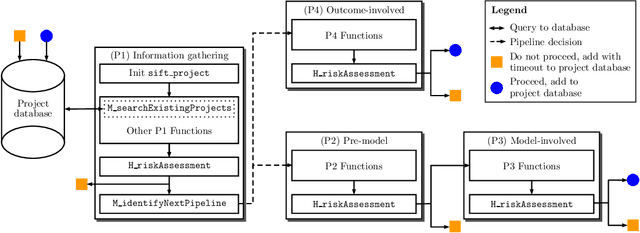
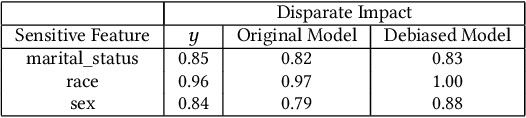
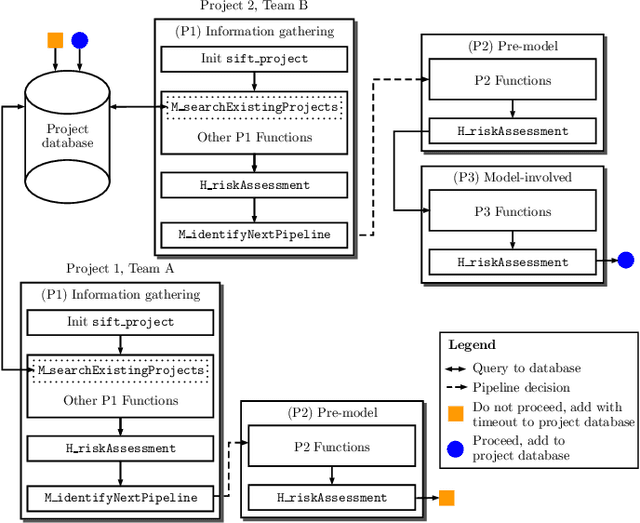
There have been significant research efforts to address the issue of unintentional bias in Machine Learning (ML). Many well-known companies have dealt with the fallout after the deployment of their products due to this issue. In an industrial context, enterprises have large-scale ML solutions for a broad class of use cases deployed for different swaths of customers. Trading off the cost of detecting and mitigating bias across this landscape over the lifetime of each use case against the risk of impact to the brand image is a key consideration. We propose a framework for industrial uses that addresses their methodological and mechanization needs. Our approach benefits from prior experience handling security and privacy concerns as well as past internal ML projects. Through significant reuse of bias handling ability at every stage in the ML development lifecycle to guide users we can lower overall costs of reducing bias.
Networks with pixels embedding: a method to improve noise resistance in images classification
May 24, 2020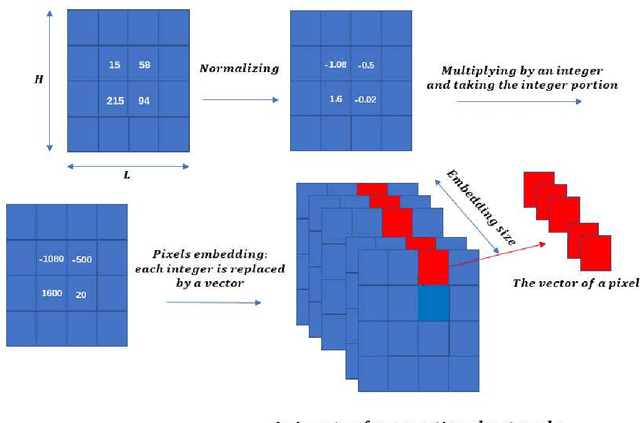
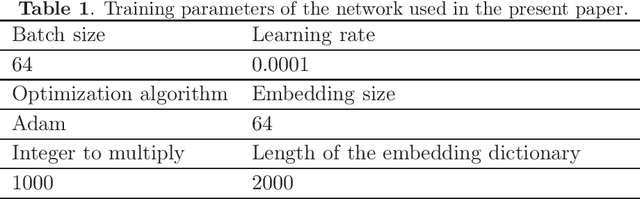
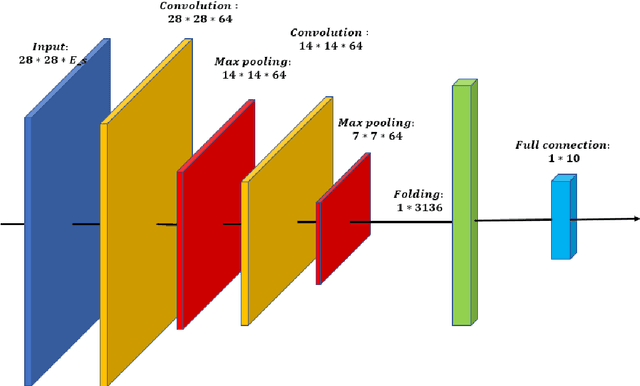
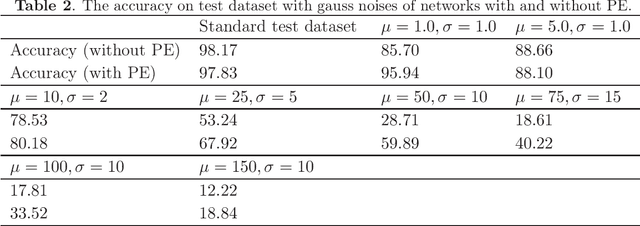
In the task of images classification, usually, the network is sensitive to noises. For example, an image of cat with noises might be misclassified as an ostrich. Conventionally, to overcome the problem of noises, one uses the technique of data enhancement, that is, to teach the network to distinguish noises by adding more images with noises in the training dataset. In this work, we provide a noise-resistance network in images classification by introducing a technique of pixels embedding. We test the network with pixels embedding, which is abbreviated as the network with PE, on the mnist database of handwritten digits. It shows that the network with PE outperforms the conventional network on images with noises. The technique of pixels embedding can be used in many tasks of images classification to improve noise resistance.
Joint Training of Variational Auto-Encoder and Latent Energy-Based Model
Jun 10, 2020

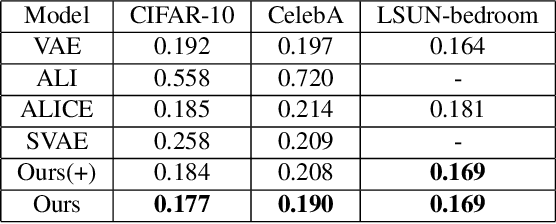

This paper proposes a joint training method to learn both the variational auto-encoder (VAE) and the latent energy-based model (EBM). The joint training of VAE and latent EBM are based on an objective function that consists of three Kullback-Leibler divergences between three joint distributions on the latent vector and the image, and the objective function is of an elegant symmetric and anti-symmetric form of divergence triangle that seamlessly integrates variational and adversarial learning. In this joint training scheme, the latent EBM serves as a critic of the generator model, while the generator model and the inference model in VAE serve as the approximate synthesis sampler and inference sampler of the latent EBM. Our experiments show that the joint training greatly improves the synthesis quality of the VAE. It also enables learning of an energy function that is capable of detecting out of sample examples for anomaly detection.
Fast Low-rank Representation based Spatial Pyramid Matching for Image Classification
Oct 02, 2015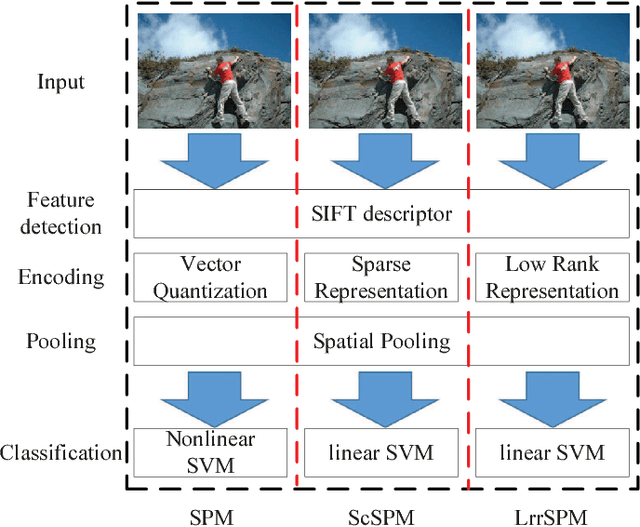

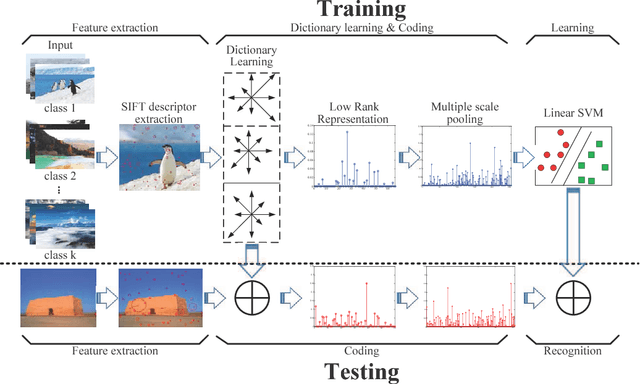
Spatial Pyramid Matching (SPM) and its variants have achieved a lot of success in image classification. The main difference among them is their encoding schemes. For example, ScSPM incorporates Sparse Code (SC) instead of Vector Quantization (VQ) into the framework of SPM. Although the methods achieve a higher recognition rate than the traditional SPM, they consume more time to encode the local descriptors extracted from the image. In this paper, we propose using Low Rank Representation (LRR) to encode the descriptors under the framework of SPM. Different from SC, LRR considers the group effect among data points instead of sparsity. Benefiting from this property, the proposed method (i.e., LrrSPM) can offer a better performance. To further improve the generalizability and robustness, we reformulate the rank-minimization problem as a truncated projection problem. Extensive experimental studies show that LrrSPM is more efficient than its counterparts (e.g., ScSPM) while achieving competitive recognition rates on nine image data sets.
* accepted into knowledge based systems, 2015
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020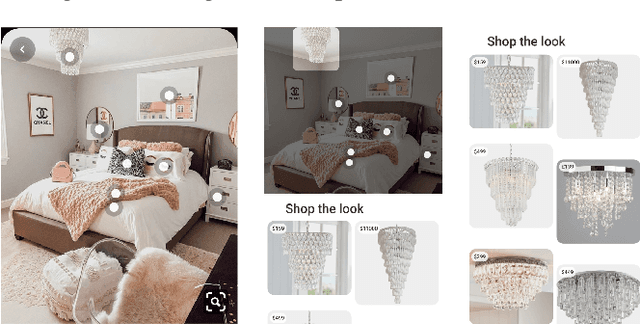

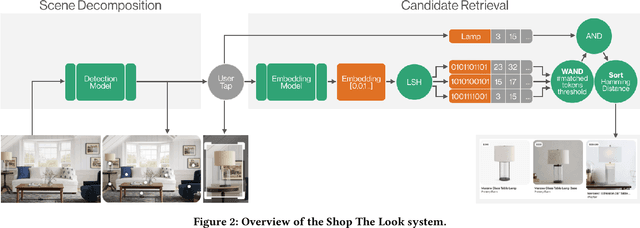
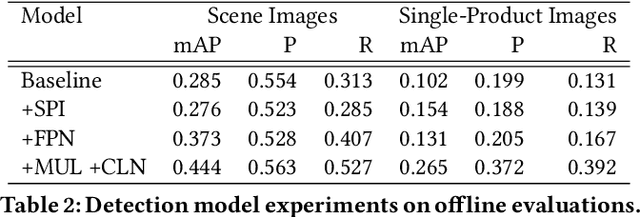
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.
Sparse Coding Approach for Multi-Frame Image Super Resolution
Feb 17, 2014
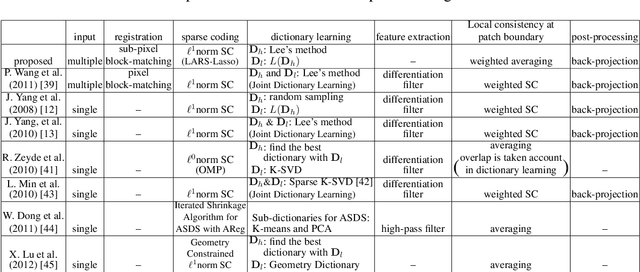
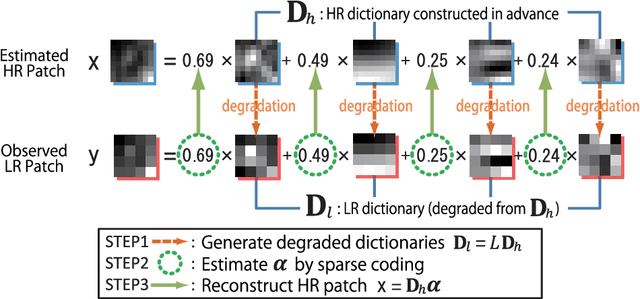
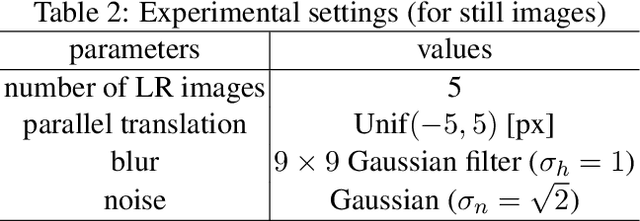
An image super-resolution method from multiple observation of low-resolution images is proposed. The method is based on sub-pixel accuracy block matching for estimating relative displacements of observed images, and sparse signal representation for estimating the corresponding high-resolution image. Relative displacements of small patches of observed low-resolution images are accurately estimated by a computationally efficient block matching method. Since the estimated displacements are also regarded as a warping component of image degradation process, the matching results are directly utilized to generate low-resolution dictionary for sparse image representation. The matching scores of the block matching are used to select a subset of low-resolution patches for reconstructing a high-resolution patch, that is, an adaptive selection of informative low-resolution images is realized. When there is only one low-resolution image, the proposed method works as a single-frame super-resolution method. The proposed method is shown to perform comparable or superior to conventional single- and multi-frame super-resolution methods through experiments using various real-world datasets.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020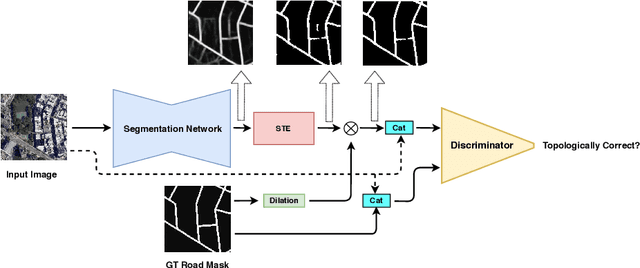
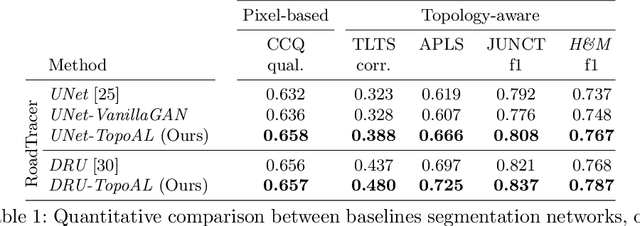

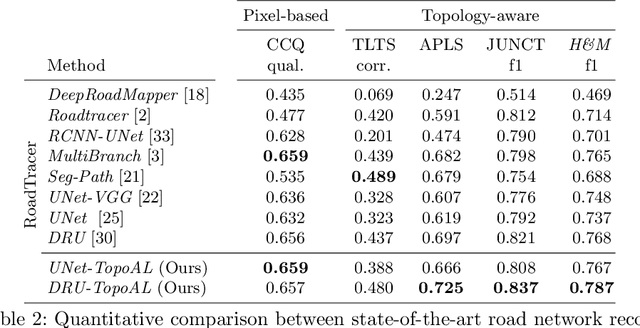
Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
Lesion Harvester: Iteratively Mining Unlabeled Lesions and Hard-Negative Examples at Scale
Jan 21, 2020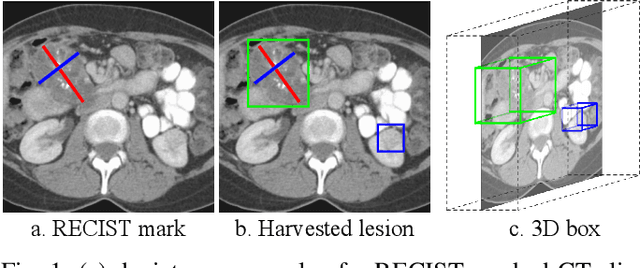
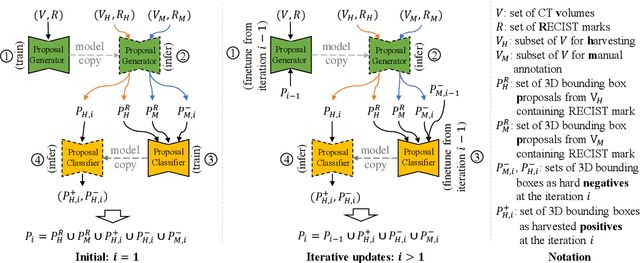
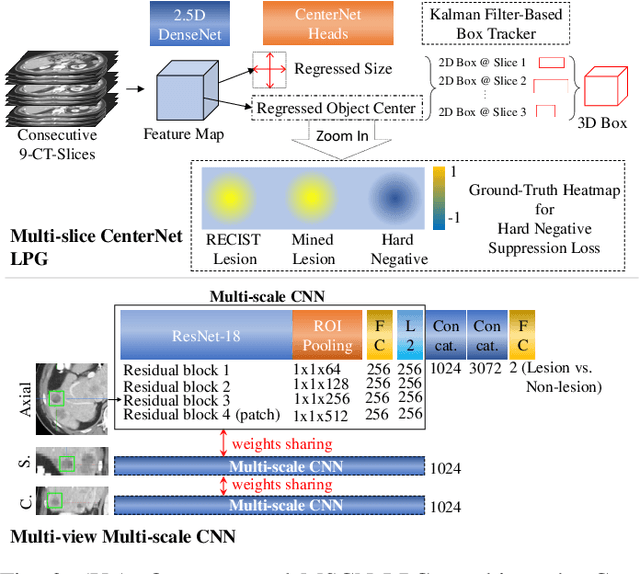
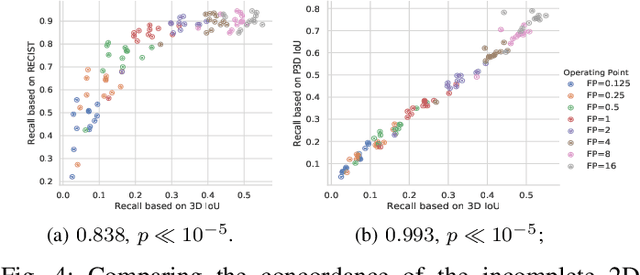
Acquiring large-scale medical image data, necessary for training machine learning algorithms, is frequently intractable, due to prohibitive expert-driven annotation costs. Recent datasets extracted from hospital archives, e.g., DeepLesion, have begun to address this problem. However, these are often incompletely or noisily labeled, e.g., DeepLesion leaves over 50% of its lesions unlabeled. Thus, effective methods to harvest missing annotations are critical for continued progress in medical image analysis. This is the goal of our work, where we develop a powerful system to harvest missing lesions from the DeepLesion dataset at high precision. Accepting the need for some degree of expert labor to achieve high fidelity, we exploit a small fully-labeled subset of medical image volumes and use it to intelligently mine annotations from the remainder. To do this, we chain together a highly sensitive lesion proposal generator and a very selective lesion proposal classifier. While our framework is generic, we optimize our performance by proposing a 3D contextual lesion proposal generator and by using a multi-view multi-scale lesion proposal classifier. These produce harvested and hard-negative proposals, which we then re-use to finetune our proposal generator by using a novel hard negative suppression loss, continuing this process until no extra lesions are found. Extensive experimental analysis demonstrates that our method can harvest an additional 9,805 lesions while keeping precision above 90%. To demonstrate the benefits of our approach, we show that lesion detectors trained on our harvested lesions can significantly outperform the same variants only trained on the original annotations, with boost of average precision of 7% to 10%. We open source our code and annotations at https://github.com/JimmyCai91/DeepLesionAnnotation.
A Robust Iris Authentication System on GPU-Based Edge Devices using Multi-Modalities Learning Model
Dec 02, 2019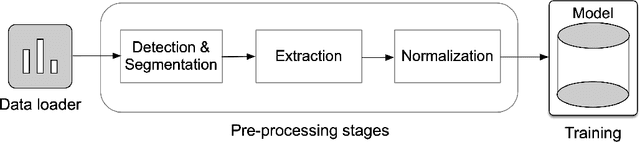
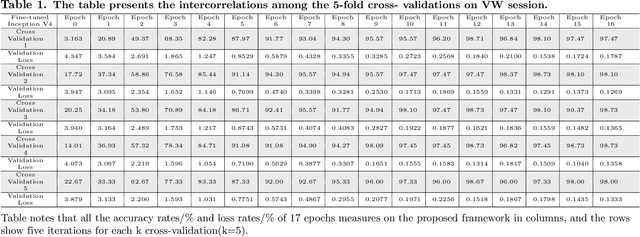
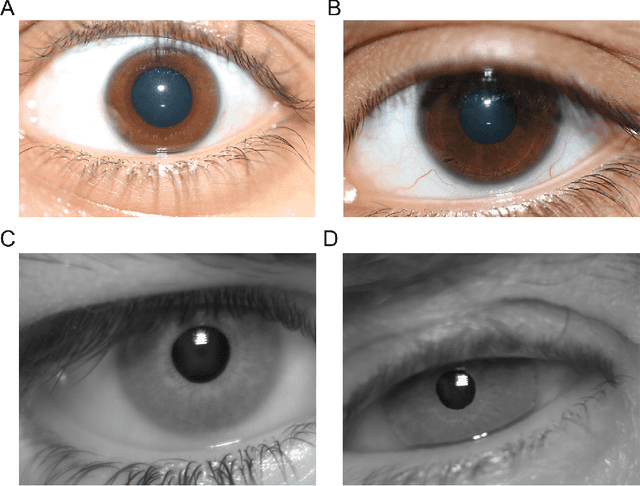
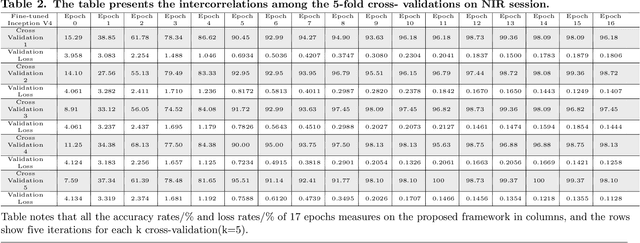
In recent years, mobile Internet has accelerated the proliferation of smart mobile development. The mobile payment, mobile security and privacy protection have become the focus of widespread attention. Iris recognition becomes a high-security authentication technology in these fields, it is widely used in distinct science fields in biometric authentication fields. The Convolutional Neural Network (CNN) is one of the mainstream deep learning approaches for image recognition, whereas its anti-noise ability is weak and needs a certain amount of memory to train in image classification tasks. Under these conditions we put forward a fine-tuning neural network model based on the Mask R-CNN and Inception V4 neural network model, which integrates every component in an overall system that combines the iris detection, extraction, and recognition function as an iris recognition system. The proposed framework has the characteristics of scalability and high availability; it not only can learn part-whole relationships of the iris image but also enhancing the robustness of the whole framework. Importantly, the proposed model can be trained using the different spectrum of samples, such as Visible Wavelength (VW) and Near Infrared (NIR) iris biometric databases. The recognition average accuracy of 99.10% is achieved while executing in the mobile edge calculation device of the Jetson Nano.
T-GD: Transferable GAN-generated Images Detection Framework
Aug 10, 2020
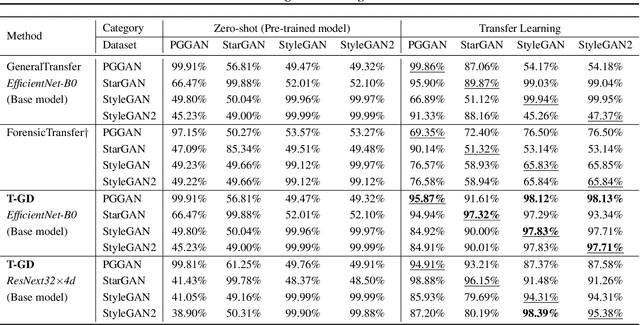
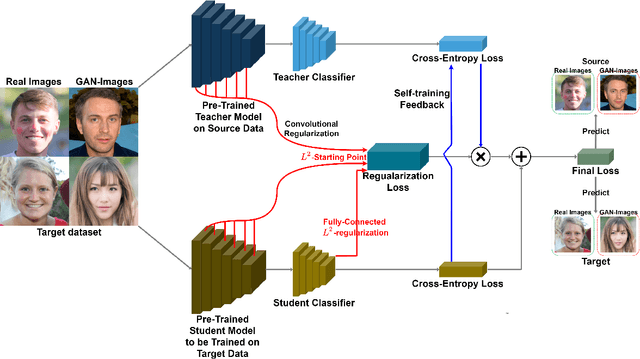
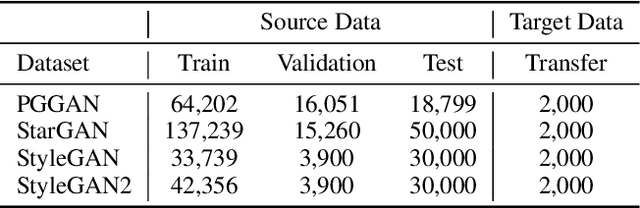
Recent advancements in Generative Adversarial Networks (GANs) enable the generation of highly realistic images, raising concerns about their misuse for malicious purposes. Detecting these GAN-generated images (GAN-images) becomes increasingly challenging due to the significant reduction of underlying artifacts and specific patterns. The absence of such traces can hinder detection algorithms from identifying GAN-images and transferring knowledge to identify other types of GAN-images as well. In this work, we present the Transferable GAN-images Detection framework T-GD, a robust transferable framework for an effective detection of GAN-images. T-GD is composed of a teacher and a student model that can iteratively teach and evaluate each other to improve the detection performance. First, we train the teacher model on the source dataset and use it as a starting point for learning the target dataset. To train the student model, we inject noise by mixing up the source and target datasets, while constraining the weight variation to preserve the starting point. Our approach is a self-training method, but distinguishes itself from prior approaches by focusing on improving the transferability of GAN-image detection. T-GD achieves high performance on the source dataset by overcoming catastrophic forgetting and effectively detecting state-of-the-art GAN-images with only a small volume of data without any metadata information.