 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLesion Harvester: Iteratively Mining Unlabeled Lesions and Hard-Negative Examples at Scale
Paper and Code
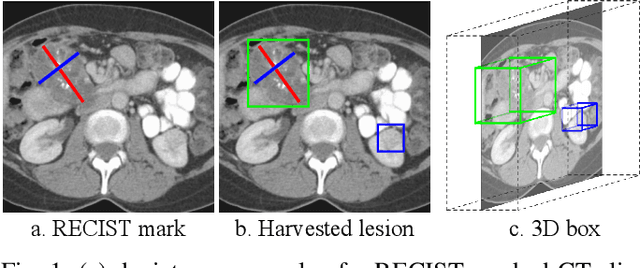
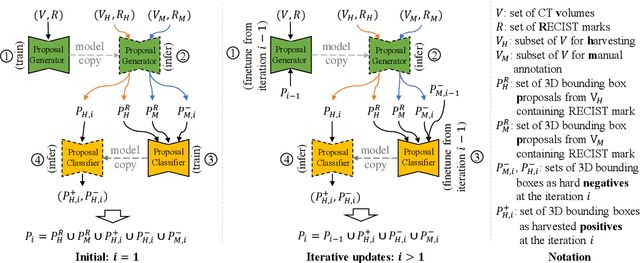
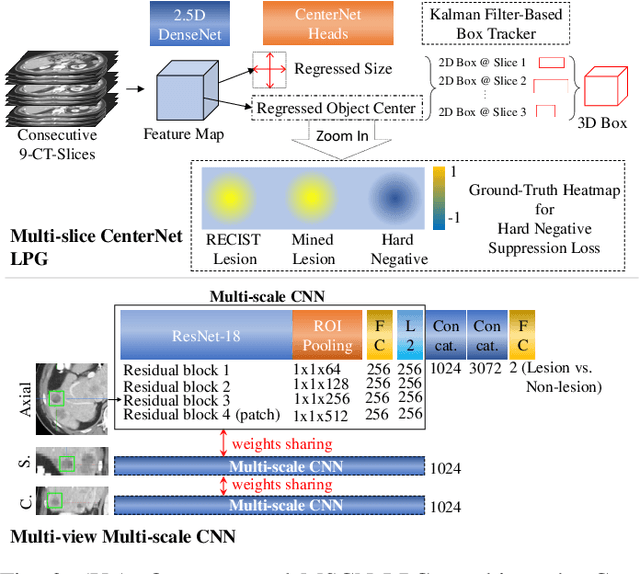
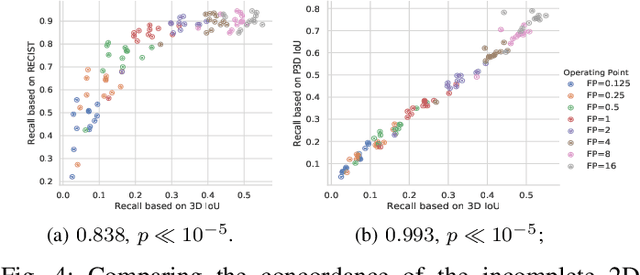
Acquiring large-scale medical image data, necessary for training machine learning algorithms, is frequently intractable, due to prohibitive expert-driven annotation costs. Recent datasets extracted from hospital archives, e.g., DeepLesion, have begun to address this problem. However, these are often incompletely or noisily labeled, e.g., DeepLesion leaves over 50% of its lesions unlabeled. Thus, effective methods to harvest missing annotations are critical for continued progress in medical image analysis. This is the goal of our work, where we develop a powerful system to harvest missing lesions from the DeepLesion dataset at high precision. Accepting the need for some degree of expert labor to achieve high fidelity, we exploit a small fully-labeled subset of medical image volumes and use it to intelligently mine annotations from the remainder. To do this, we chain together a highly sensitive lesion proposal generator and a very selective lesion proposal classifier. While our framework is generic, we optimize our performance by proposing a 3D contextual lesion proposal generator and by using a multi-view multi-scale lesion proposal classifier. These produce harvested and hard-negative proposals, which we then re-use to finetune our proposal generator by using a novel hard negative suppression loss, continuing this process until no extra lesions are found. Extensive experimental analysis demonstrates that our method can harvest an additional 9,805 lesions while keeping precision above 90%. To demonstrate the benefits of our approach, we show that lesion detectors trained on our harvested lesions can significantly outperform the same variants only trained on the original annotations, with boost of average precision of 7% to 10%. We open source our annotations at https://github.com/JimmyCai91/DeepLesionAnnotation.