 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Visibility-aware Generalizable Neural Radiance Fields for Interacting Hands
Jan 02, 2024
Neural radiance fields (NeRFs) are promising 3D representations for scenes, objects, and humans. However, most existing methods require multi-view inputs and per-scene training, which limits their real-life applications. Moreover, current methods focus on single-subject cases, leaving scenes of interacting hands that involve severe inter-hand occlusions and challenging view variations remain unsolved. To tackle these issues, this paper proposes a generalizable visibility-aware NeRF (VA-NeRF) framework for interacting hands. Specifically, given an image of interacting hands as input, our VA-NeRF first obtains a mesh-based representation of hands and extracts their corresponding geometric and textural features. Subsequently, a feature fusion module that exploits the visibility of query points and mesh vertices is introduced to adaptively merge features of both hands, enabling the recovery of features in unseen areas. Additionally, our VA-NeRF is optimized together with a novel discriminator within an adversarial learning paradigm. In contrast to conventional discriminators that predict a single real/fake label for the synthesized image, the proposed discriminator generates a pixel-wise visibility map, providing fine-grained supervision for unseen areas and encouraging the VA-NeRF to improve the visual quality of synthesized images. Experiments on the Interhand2.6M dataset demonstrate that our proposed VA-NeRF outperforms conventional NeRFs significantly. Project Page: \url{https://github.com/XuanHuang0/VANeRF}.
Divide-and-Conquer Attack: Harnessing the Power of LLM to Bypass the Censorship of Text-to-Image Generation Model
Dec 12, 2023Text-to-image generative models offer many innovative services but also raise ethical concerns due to their potential to generate unethical images. Most publicly available text-to-image models employ safety filters to prevent unintended generation intents. In this work, we introduce the Divide-and-Conquer Attack to circumvent the safety filters of state-of-the-art text-to-image models. Our attack leverages LLMs as agents for text transformation, creating adversarial prompts from sensitive ones. We have developed effective helper prompts that enable LLMs to break down sensitive drawing prompts into multiple harmless descriptions, allowing them to bypass safety filters while still generating sensitive images. This means that the latent harmful meaning only becomes apparent when all individual elements are drawn together. Our evaluation demonstrates that our attack successfully circumvents the closed-box safety filter of SOTA DALLE-3 integrated natively into ChatGPT to generate unethical images. This approach, which essentially uses LLM-generated adversarial prompts against GPT-4-assisted DALLE-3, is akin to using one's own spear to breach their shield. It could have more severe security implications than previous manual crafting or iterative model querying methods, and we hope it stimulates more attention towards similar efforts. Our code and data are available at: https://github.com/researchcode001/Divide-and-Conquer-Attack
Towards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Jan 01, 2024Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods.
Transformer-based Selective Super-Resolution for Efficient Image Refinement
Dec 10, 2023Conventional super-resolution methods suffer from two drawbacks: substantial computational cost in upscaling an entire large image, and the introduction of extraneous or potentially detrimental information for downstream computer vision tasks during the refinement of the background. To solve these issues, we propose a novel transformer-based algorithm, Selective Super-Resolution (SSR), which partitions images into non-overlapping tiles, selects tiles of interest at various scales with a pyramid architecture, and exclusively reconstructs these selected tiles with deep features. Experimental results on three datasets demonstrate the efficiency and robust performance of our approach for super-resolution. Compared to the state-of-the-art methods, the FID score is reduced from 26.78 to 10.41 with 40% reduction in computation cost for the BDD100K dataset. The source code is available at https://github.com/destiny301/SSR.
GazeCLIP: Towards Enhancing Gaze Estimation via Text Guidance
Dec 30, 2023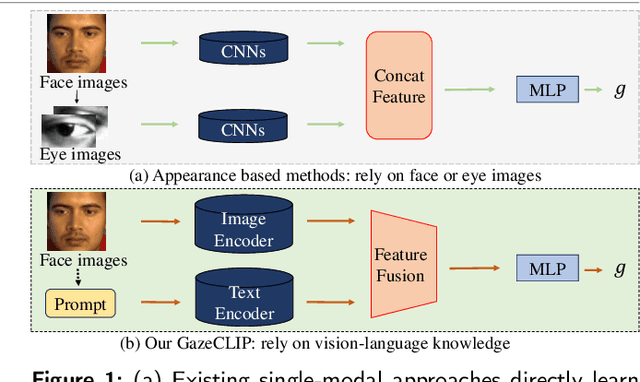

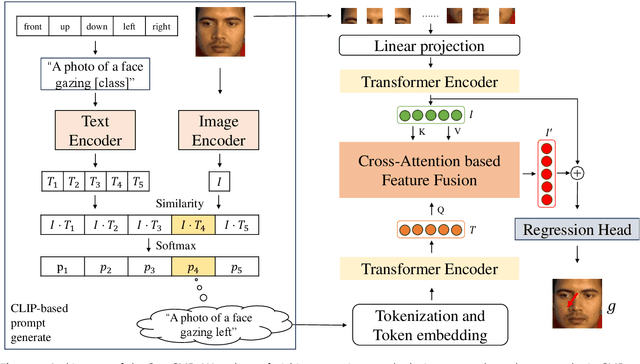
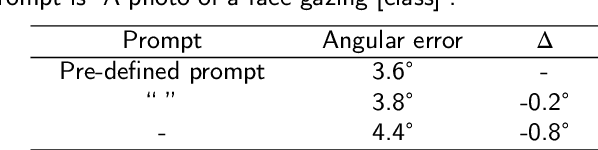
Over the past decade, visual gaze estimation has garnered growing attention within the research community, thanks to its wide-ranging application scenarios. While existing estimation approaches have achieved remarkable success in enhancing prediction accuracy, they primarily infer gaze directions from single-image signals and discard the huge potentials of the currently dominant text guidance. Notably, visual-language collaboration has been extensively explored across a range of visual tasks, such as image synthesis and manipulation, leveraging the remarkable transferability of large-scale Contrastive Language-Image Pre-training (CLIP) model. Nevertheless, existing gaze estimation approaches ignore the rich semantic cues conveyed by linguistic signals and priors in CLIP feature space, thereby yielding performance setbacks. In pursuit of making up this gap, we delve deeply into the text-eye collaboration protocol and introduce a novel gaze estimation framework in this paper, referred to as GazeCLIP. Specifically, we intricately design a linguistic description generator to produce text signals with coarse directional cues. Additionally, a CLIP-based backbone that excels in characterizing text-eye pairs for gaze estimation is presented. This is followed by the implementation of a fine-grained multi-modal fusion module aimed at modeling the interrelationships between heterogeneous inputs. Extensive experiments on three challenging datasets demonstrate the superiority of the proposed GazeCLIP which surpasses the previous approaches and achieves the state-of-the-art estimation accuracy.
RetouchUAA: Unconstrained Adversarial Attack via Image Retouching
Nov 27, 2023
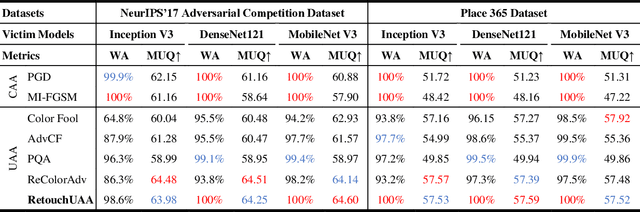
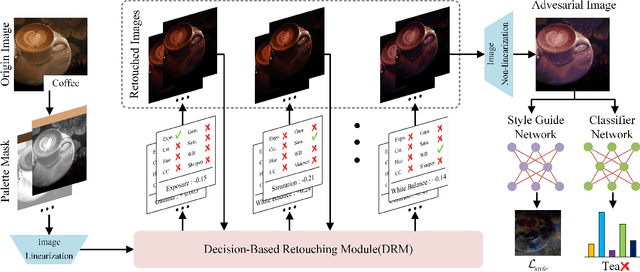
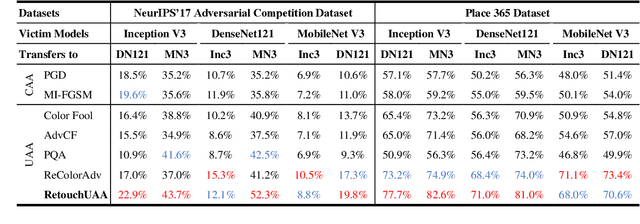
Deep Neural Networks (DNNs) are susceptible to adversarial examples. Conventional attacks generate controlled noise-like perturbations that fail to reflect real-world scenarios and hard to interpretable. In contrast, recent unconstrained attacks mimic natural image transformations occurring in the real world for perceptible but inconspicuous attacks, yet compromise realism due to neglect of image post-processing and uncontrolled attack direction. In this paper, we propose RetouchUAA, an unconstrained attack that exploits a real-life perturbation: image retouching styles, highlighting its potential threat to DNNs. Compared to existing attacks, RetouchUAA offers several notable advantages. Firstly, RetouchUAA excels in generating interpretable and realistic perturbations through two key designs: the image retouching attack framework and the retouching style guidance module. The former custom-designed human-interpretability retouching framework for adversarial attack by linearizing images while modelling the local processing and retouching decision-making in human retouching behaviour, provides an explicit and reasonable pipeline for understanding the robustness of DNNs against retouching. The latter guides the adversarial image towards standard retouching styles, thereby ensuring its realism. Secondly, attributed to the design of the retouching decision regularization and the persistent attack strategy, RetouchUAA also exhibits outstanding attack capability and defense robustness, posing a heavy threat to DNNs. Experiments on ImageNet and Place365 reveal that RetouchUAA achieves nearly 100\% white-box attack success against three DNNs, while achieving a better trade-off between image naturalness, transferability and defense robustness than baseline attacks.
Encoder-minimal and Decoder-minimal Framework for Remote Sensing Image Dehazing
Dec 13, 2023Haze obscures remote sensing images, hindering valuable information extraction. To this end, we propose RSHazeNet, an encoder-minimal and decoder-minimal framework for efficient remote sensing image dehazing. Specifically, regarding the process of merging features within the same level, we develop an innovative module called intra-level transposed fusion module (ITFM). This module employs adaptive transposed self-attention to capture comprehensive context-aware information, facilitating the robust context-aware feature fusion. Meanwhile, we present a cross-level multi-view interaction module (CMIM) to enable effective interactions between features from various levels, mitigating the loss of information due to the repeated sampling operations. In addition, we propose a multi-view progressive extraction block (MPEB) that partitions the features into four distinct components and employs convolution with varying kernel sizes, groups, and dilation factors to facilitate view-progressive feature learning. Extensive experiments demonstrate the superiority of our proposed RSHazeNet. We release the source code and all pre-trained models at \url{https://github.com/chdwyb/RSHazeNet}.
The Contemporary Art of Image Search: Iterative User Intent Expansion via Vision-Language Model
Dec 05, 2023Image search is an essential and user-friendly method to explore vast galleries of digital images. However, existing image search methods heavily rely on proximity measurements like tag matching or image similarity, requiring precise user inputs for satisfactory results. To meet the growing demand for a contemporary image search engine that enables accurate comprehension of users' search intentions, we introduce an innovative user intent expansion framework. Our framework leverages visual-language models to parse and compose multi-modal user inputs to provide more accurate and satisfying results. It comprises two-stage processes: 1) a parsing stage that incorporates a language parsing module with large language models to enhance the comprehension of textual inputs, along with a visual parsing module that integrates an interactive segmentation module to swiftly identify detailed visual elements within images; and 2) a logic composition stage that combines multiple user search intents into a unified logic expression for more sophisticated operations in complex searching scenarios. Moreover, the intent expansion framework enables users to perform flexible contextualized interactions with the search results to further specify or adjust their detailed search intents iteratively. We implemented the framework into an image search system for NFT (non-fungible token) search and conducted a user study to evaluate its usability and novel properties. The results indicate that the proposed framework significantly improves users' image search experience. Particularly the parsing and contextualized interactions prove useful in allowing users to express their search intents more accurately and engage in a more enjoyable iterative search experience.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Dec 02, 2023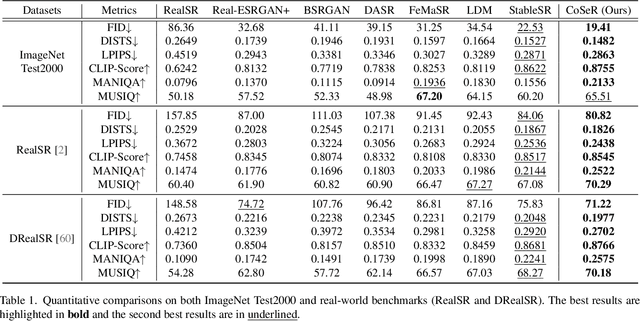
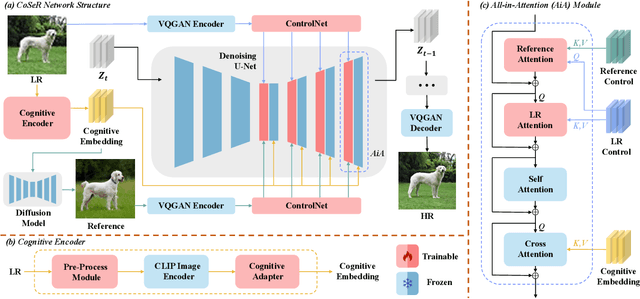
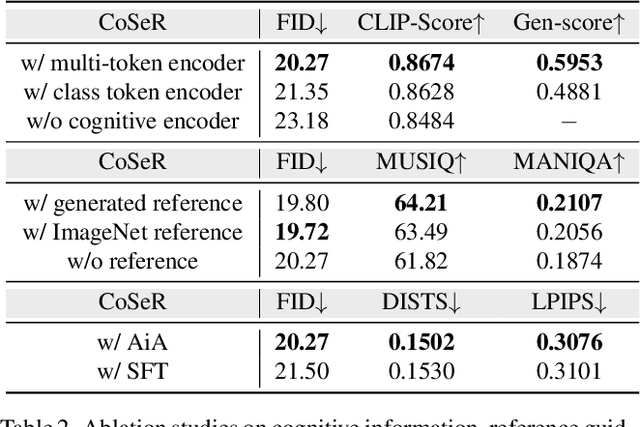
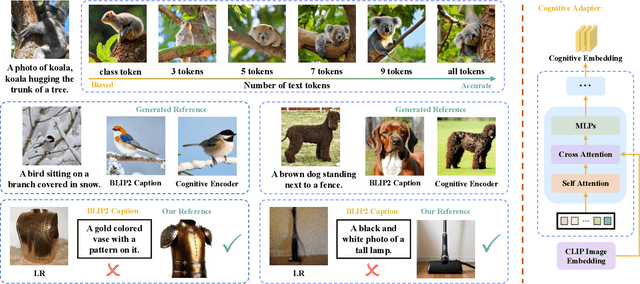
Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
Pixel-Superpixel Contrastive Learning and Pseudo-Label Correction for Hyperspectral Image Clustering
Dec 15, 2023Hyperspectral image (HSI) clustering is gaining considerable attention owing to recent methods that overcome the inefficiency and misleading results from the absence of supervised information. Contrastive learning methods excel at existing pixel level and super pixel level HSI clustering tasks. The pixel-level contrastive learning method can effectively improve the ability of the model to capture fine features of HSI but requires a large time overhead. The super pixel-level contrastive learning method utilizes the homogeneity of HSI and reduces computing resources; however, it yields rough classification results. To exploit the strengths of both methods, we present a pixel super pixel contrastive learning and pseudo-label correction (PSCPC) method for the HSI clustering. PSCPC can reasonably capture domain-specific and fine-grained features through super pixels and the comparative learning of a small number of pixels within the super pixels. To improve the clustering performance of super pixels, this paper proposes a pseudo-label correction module that aligns the clustering pseudo-labels of pixels and super-pixels. In addition, pixel-level clustering results are used to supervise super pixel-level clustering, improving the generalization ability of the model. Extensive experiments demonstrate the effectiveness and efficiency of PSCPC.