 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Role-specific Guided Large Language Model for Ophthalmic Consultation Based on Stylistic Differentiation
Jul 29, 2024Ophthalmology consultations are crucial for diagnosing, treating, and preventing eye diseases. However, the growing demand for consultations exceeds the availability of ophthalmologists. By leveraging large pre-trained language models, we can design effective dialogues for specific scenarios, aiding in consultations. Traditional fine-tuning strategies for question-answering tasks are impractical due to increasing model size and often ignoring patient-doctor role function during consultations. In this paper, we propose EyeDoctor, an ophthalmic medical questioning large language model that enhances accuracy through doctor-patient role perception guided and an augmented knowledge base with external disease information. Experimental results show EyeDoctor achieves higher question-answering precision in ophthalmology consultations. Notably, EyeDoctor demonstrated a 7.25% improvement in Rouge-1 scores and a 10.16% improvement in F1 scores on multi-round datasets compared to second best model ChatGPT, highlighting the importance of doctor-patient role differentiation and dynamic knowledge base expansion for intelligent medical consultations. EyeDoc also serves as a free available web based service and souce code is available at https://github.com/sperfu/EyeDoc.
Class-attention Video Transformer for Engagement Intensity Prediction
Aug 12, 2022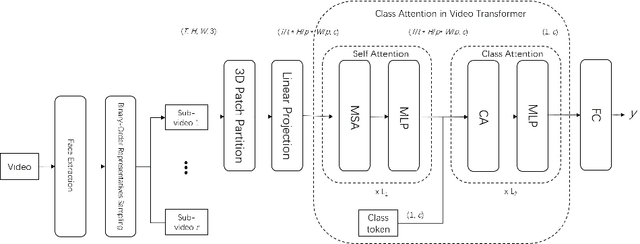
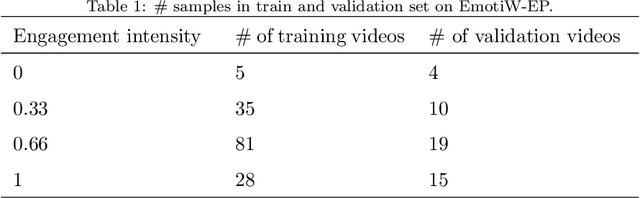
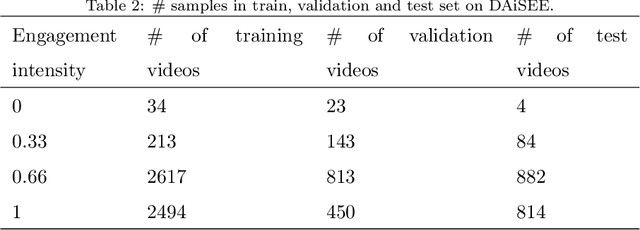
In order to deal with variant-length long videos, prior works extract multi-modal features and fuse them to predict students' engagement intensity. In this paper, we present a new end-to-end method Class Attention in Video Transformer (CavT), which involves a single vector to process class embedding and to uniformly perform end-to-end learning on variant-length long videos and fixed-length short videos. Furthermore, to address the lack of sufficient samples, we propose a binary-order representatives sampling method (BorS) to add multiple video sequences of each video to augment the training set. BorS+CavT not only achieves the state-of-the-art MSE (0.0495) on the EmotiW-EP dataset, but also obtains the state-of-the-art MSE (0.0377) on the DAiSEE dataset. The code and models will be made publicly available at https://github.com/mountainai/cavt.