 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Integrating Feature and Image Pyramid: A Lung Nodule Detector Learned in Curriculum Fashion
Aug 01, 2018
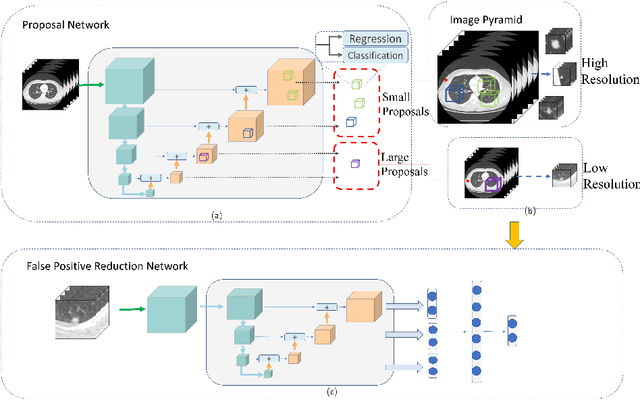
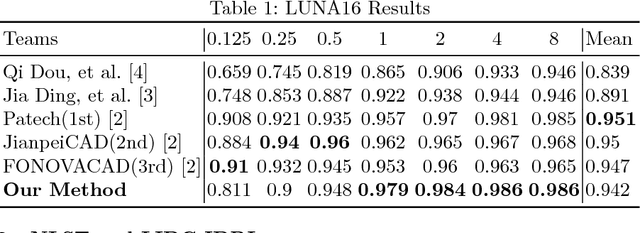
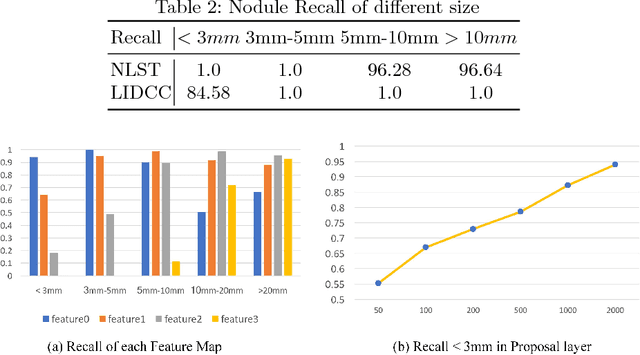

Lung nodules suffer large variation in size and appearance in CT images. Nodules less than 10mm can easily lose information after down-sampling in convolutional neural networks, which results in low sensitivity. In this paper, a combination of 3D image and feature pyramid is exploited to integrate lower-level texture features with high-level semantic features, thus leading to a higher recall. However, 3D operations are time and memory consuming, which aggravates the situation with the explosive growth of medical images. To tackle this problem, we propose a general curriculum training strategy to speed up training. An dynamic sampling method is designed to pick up partial samples which give the best contribution to network training, thus leading to much less time consuming. In experiments, we demonstrate that the proposed network outperforms previous state-of-the-art methods. Meanwhile, our sampling strategy halves the training time of the proposal network on LUNA16.
Connecting Vision and Language with Localized Narratives
Dec 06, 2019
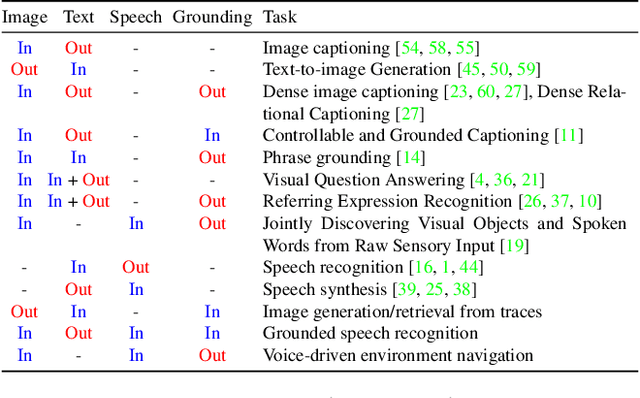

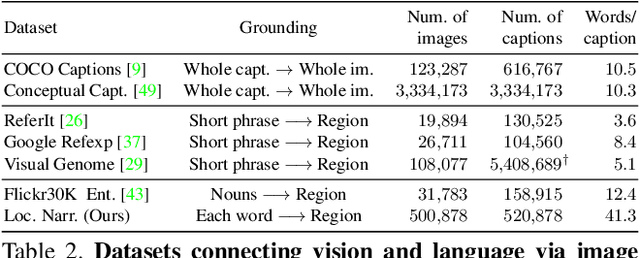
We propose Localized Narratives, an efficient way to collect image captions with dense visual grounding. We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data. We annotate 500k images with Localized Narratives: the whole COCO dataset and 380k images of the Open Images dataset. We provide an extensive analysis of these annotations, which we will release early 2020. Moreover, we demonstrate the utility of our data on two applications which benefit from our mouse trace: controlled image captioning and image generation.
MGD-GAN: Text-to-Pedestrian generation through Multi-Grained Discrimination
Oct 02, 2020

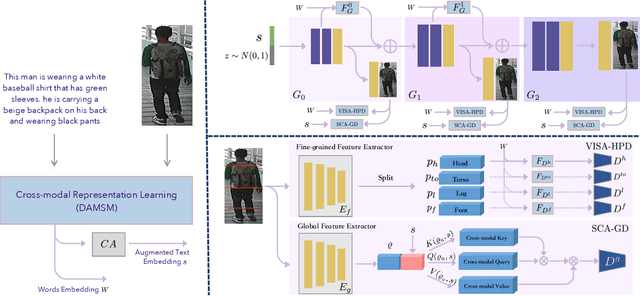

In this paper, we investigate the problem of text-to-pedestrian synthesis, which has many potential applications in art, design, and video surveillance. Existing methods for text-to-bird/flower synthesis are still far from solving this fine-grained image generation problem, due to the complex structure and heterogeneous appearance that the pedestrians naturally take on. To this end, we propose the Multi-Grained Discrimination enhanced Generative Adversarial Network, that capitalizes a human-part-based Discriminator (HPD) and a self-cross-attended (SCA) global Discriminator in order to capture the coherence of the complex body structure. A fined-grained word-level attention mechanism is employed in the HPD module to enforce diversified appearance and vivid details. In addition, two pedestrian generation metrics, named Pose Score and Pose Variance, are devised to evaluate the generation quality and diversity, respectively. We conduct extensive experiments and ablation studies on the caption-annotated pedestrian dataset, CUHK Person Description Dataset. The substantial improvement over the various metrics demonstrates the efficacy of MGD-GAN on the text-to-pedestrian synthesis scenario.
Learning Propagation Rules for Attribution Map Generation
Oct 14, 2020
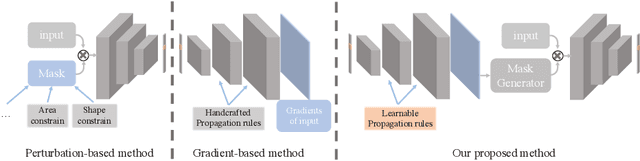
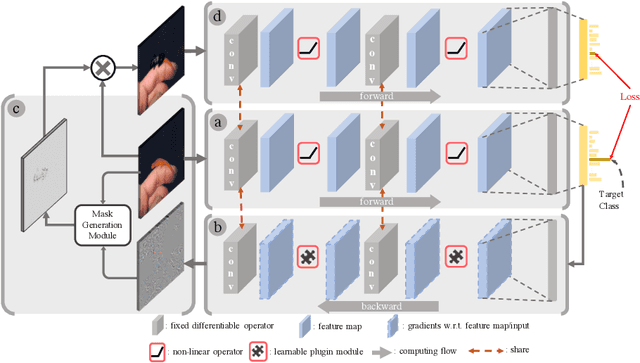
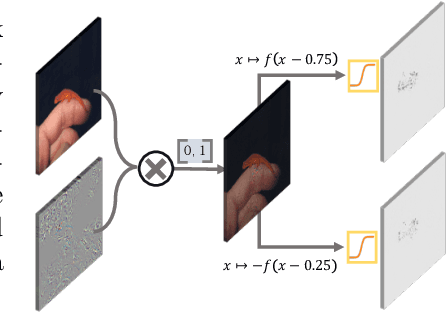
Prior gradient-based attribution-map methods rely on handcrafted propagation rules for the non-linear/activation layers during the backward pass, so as to produce gradients of the input and then the attribution map. Despite the promising results achieved, such methods are sensitive to the non-informative high-frequency components and lack adaptability for various models and samples. In this paper, we propose a dedicated method to generate attribution maps that allow us to learn the propagation rules automatically, overcoming the flaws of the handcrafted ones. Specifically, we introduce a learnable plugin module, which enables adaptive propagation rules for each pixel, to the non-linear layers during the backward pass for mask generating. The masked input image is then fed into the model again to obtain new output that can be used as a guidance when combined with the original one. The introduced learnable module can be trained under any auto-grad framework with higher-order differential support. As demonstrated on five datasets and six network architectures, the proposed method yields state-of-the-art results and gives cleaner and more visually plausible attribution maps.
Approximating the Hotelling Observer with Autoencoder-Learned Efficient Channels for Binary Signal Detection Tasks
Mar 04, 2020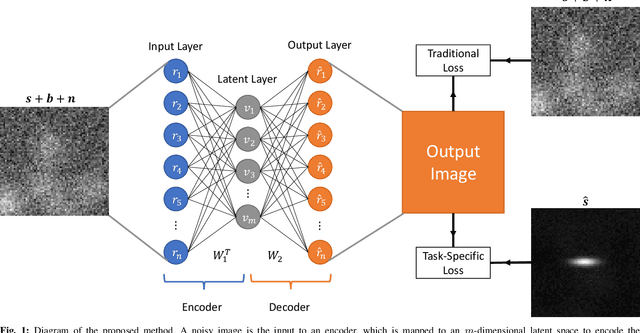


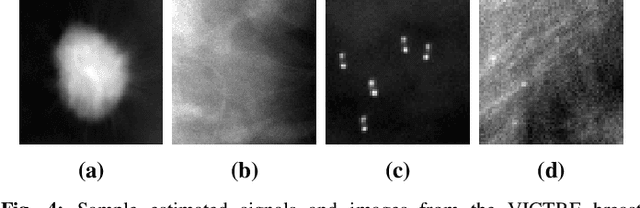
The objective assessment of image quality (IQ) has been advocated for the analysis and optimization of medical imaging systems. One method of obtaining such IQ metrics is through a mathematical observer. The Bayesian ideal observer is optimal by definition for signal detection tasks, but is frequently both intractable and non-linear. As an alternative, linear observers are sometimes used for task-based image quality assessment. The optimal linear observer is the Hotelling observer (HO). The computational cost of calculating the HO increases with image size, making a reduction in the dimensionality of the data desirable. Channelized methods have become popular for this purpose, and many competing methods are available for computing efficient channels. In this work, a novel method for learning channels using an autoencoder (AE) is presented. AEs are a type of artificial neural network (ANN) that are frequently employed to learn concise representations of data to reduce dimensionality. Modifying the traditional AE loss function to focus on task-relevant information permits the development of efficient AE-channels. These AE-channels were trained and tested on a variety of signal shapes and backgrounds to evaluate their performance. In the experiments, the AE-learned channels were competitive with and frequently outperformed other state-of-the-art methods for approximating the HO. The performance gains were greatest for the datasets with a small number of training images and noisy estimates of the signal image. Overall, AEs are demonstrated to be competitive with state-of-the-art methods for generating efficient channels for the HO and can have superior performance on small datasets.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

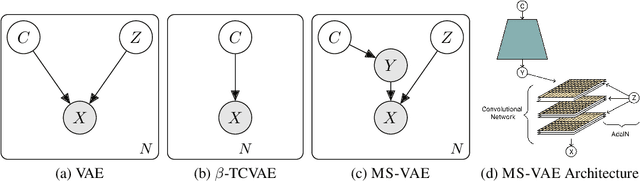

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
Learning Deep Features in Instrumental Variable Regression
Oct 14, 2020
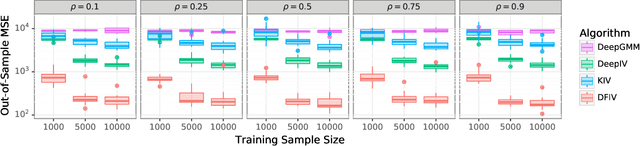

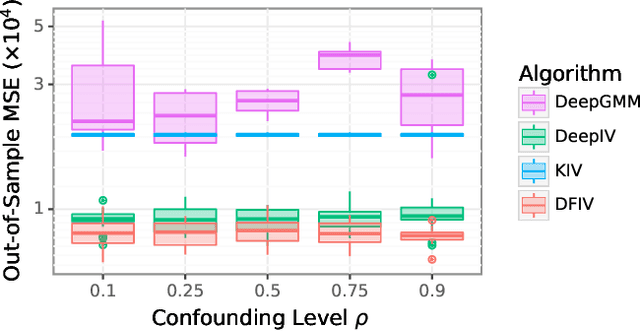
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables by utilizing an instrumental variable, which is conditionally independent of the outcome given the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, {\it deep feature instrumental variable regression (DFIV)}, to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.
Coarse2Fine: Two-Layer Fusion For Image Retrieval
Jul 04, 2016

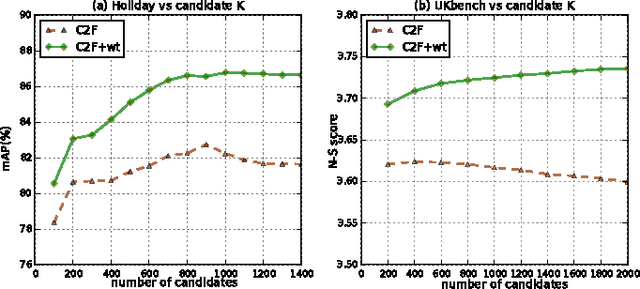
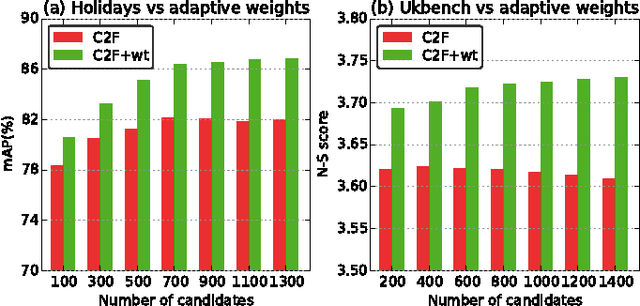
This paper addresses the problem of large-scale image retrieval. We propose a two-layer fusion method which takes advantage of global and local cues and ranks database images from coarse to fine (C2F). Departing from the previous methods fusing multiple image descriptors simultaneously, C2F is featured by a layered procedure composed by filtering and refining. In particular, C2F consists of three components. 1) Distractor filtering. With holistic representations, noise images are filtered out from the database, so the number of candidate images to be used for comparison with the query can be greatly reduced. 2) Adaptive weighting. For a certain query, the similarity of candidate images can be estimated by holistic similarity scores in complementary to the local ones. 3) Candidate refining. Accurate retrieval is conducted via local features, combining the pre-computed adaptive weights. Experiments are presented on two benchmarks, \emph{i.e.,} Holidays and Ukbench datasets. We show that our method outperforms recent fusion methods in terms of storage consumption and computation complexity, and that the accuracy is competitive to the state-of-the-arts.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020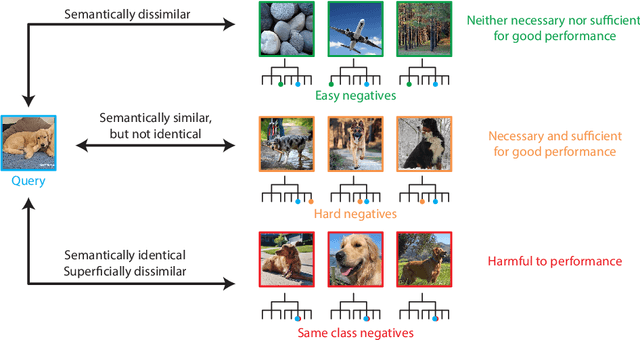
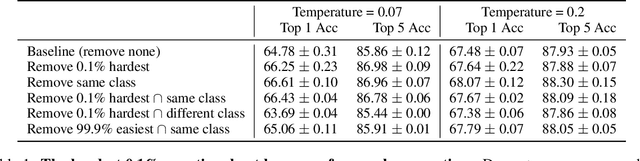
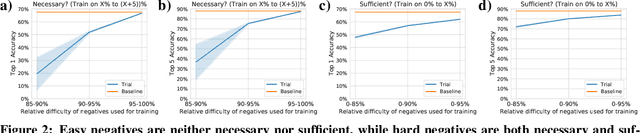
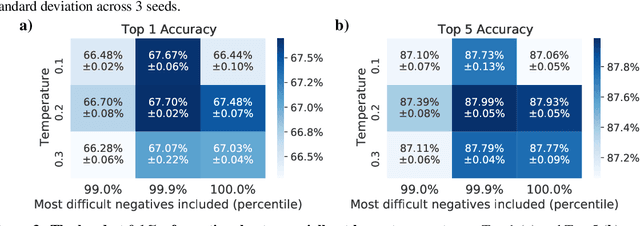
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.
Deep Patch-based Human Segmentation
Jul 11, 2020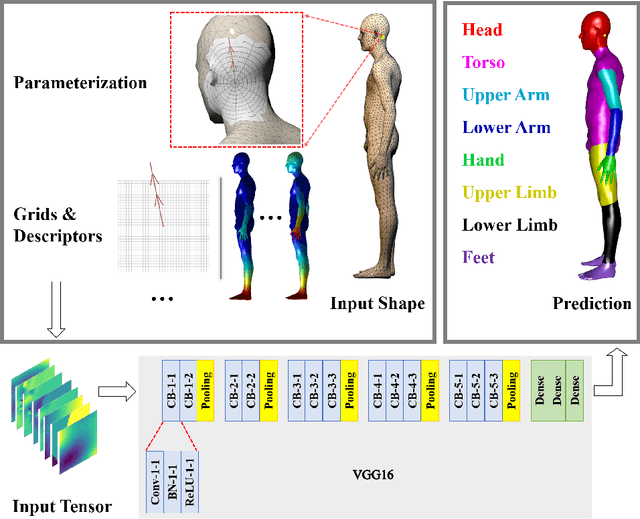
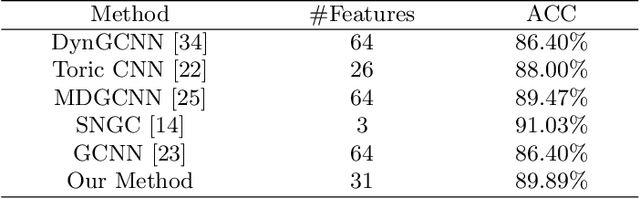
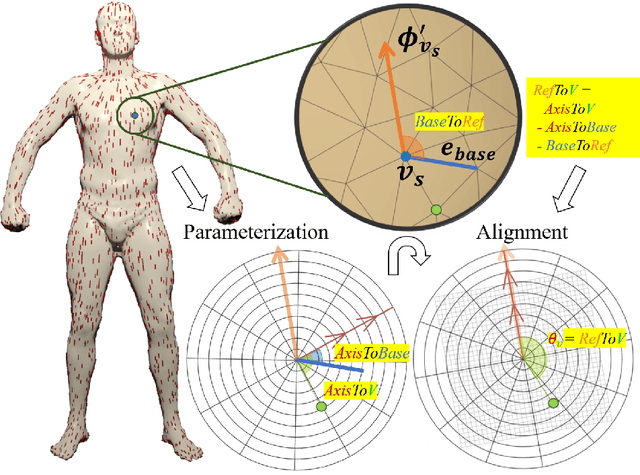

3D human segmentation has seen noticeable progress in re-cent years. It, however, still remains a challenge to date. In this paper, weintroduce a deep patch-based method for 3D human segmentation. Wefirst extract a local surface patch for each vertex and then parameterizeit into a 2D grid (or image). We then embed identified shape descriptorsinto the 2D grids which are further fed into the powerful 2D Convolu-tional Neural Network for regressing corresponding semantic labels (e.g.,head, torso). Experiments demonstrate that our method is effective inhuman segmentation, and achieves state-of-the-art accuracy.