 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Block Shuffle: A Method for High-resolution Fast Style Transfer with Limited Memory
Aug 09, 2020

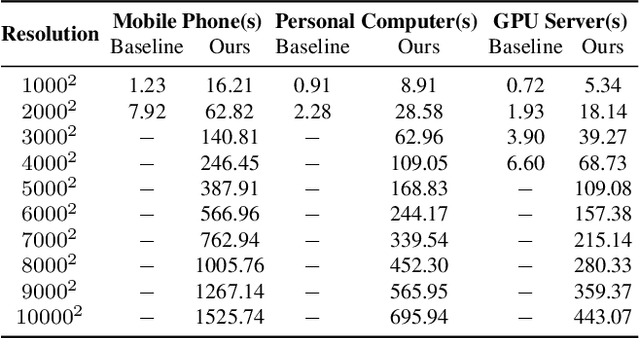
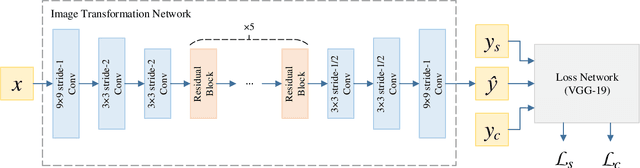
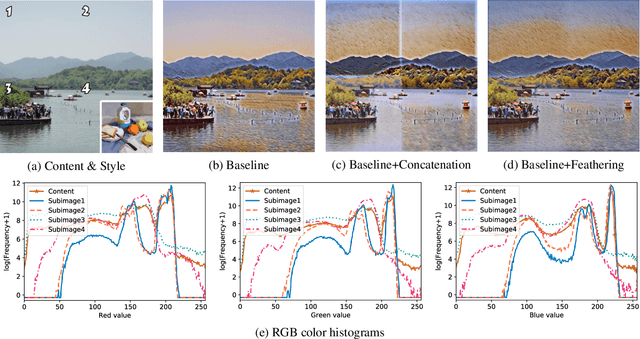
Fast Style Transfer is a series of Neural Style Transfer algorithms that use feed-forward neural networks to render input images. Because of the high dimension of the output layer, these networks require much memory for computation. Therefore, for high-resolution images, most mobile devices and personal computers cannot stylize them, which greatly limits the application scenarios of Fast Style Transfer. At present, the two existing solutions are purchasing more memory and using the feathering-based method, but the former requires additional cost, and the latter has poor image quality. To solve this problem, we propose a novel image synthesis method named \emph{block shuffle}, which converts a single task with high memory consumption to multiple subtasks with low memory consumption. This method can act as a plug-in for Fast Style Transfer without any modification to the network architecture. We use the most popular Fast Style Transfer repository on GitHub as the baseline. Experiments show that the quality of high-resolution images generated by our method is better than that of the feathering-based method. Although our method is an order of magnitude slower than the baseline, it can stylize high-resolution images with limited memory, which is impossible with the baseline. The code and models will be made available on \url{https://github.com/czczup/block-shuffle}.
StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
Jun 28, 2018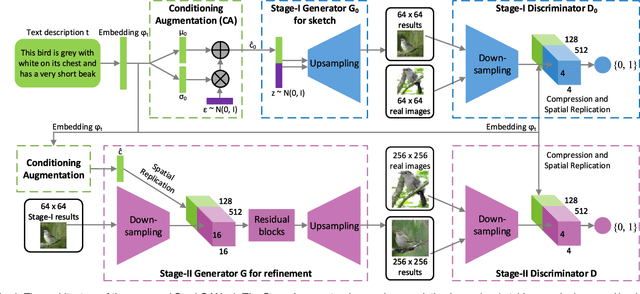

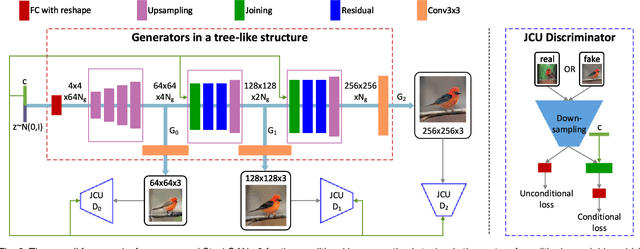

Although Generative Adversarial Networks (GANs) have shown remarkable success in various tasks, they still face challenges in generating high quality images. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) aiming at generating high-resolution photo-realistic images. First, we propose a two-stage generative adversarial network architecture, StackGAN-v1, for text-to-image synthesis. The Stage-I GAN sketches the primitive shape and colors of the object based on given text description, yielding low-resolution images. The Stage-II GAN takes Stage-I results and text descriptions as inputs, and generates high-resolution images with photo-realistic details. Second, an advanced multi-stage generative adversarial network architecture, StackGAN-v2, is proposed for both conditional and unconditional generative tasks. Our StackGAN-v2 consists of multiple generators and discriminators in a tree-like structure; images at multiple scales corresponding to the same scene are generated from different branches of the tree. StackGAN-v2 shows more stable training behavior than StackGAN-v1 by jointly approximating multiple distributions. Extensive experiments demonstrate that the proposed stacked generative adversarial networks significantly outperform other state-of-the-art methods in generating photo-realistic images.
Deep Learning for 3D Point Cloud Understanding: A Survey
Sep 18, 2020
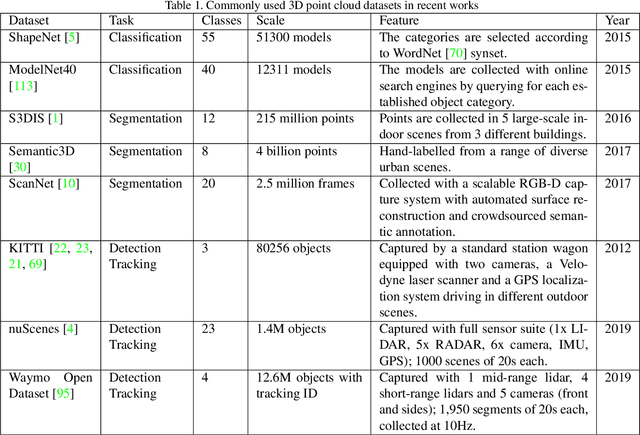
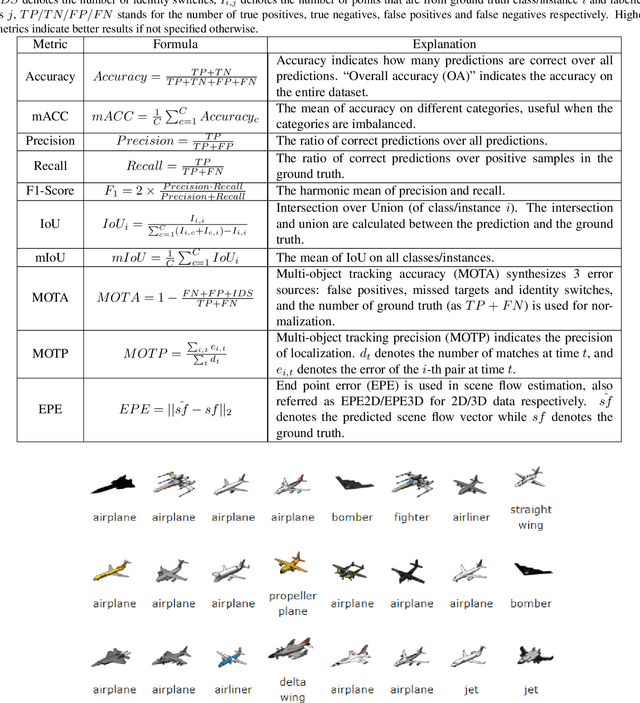
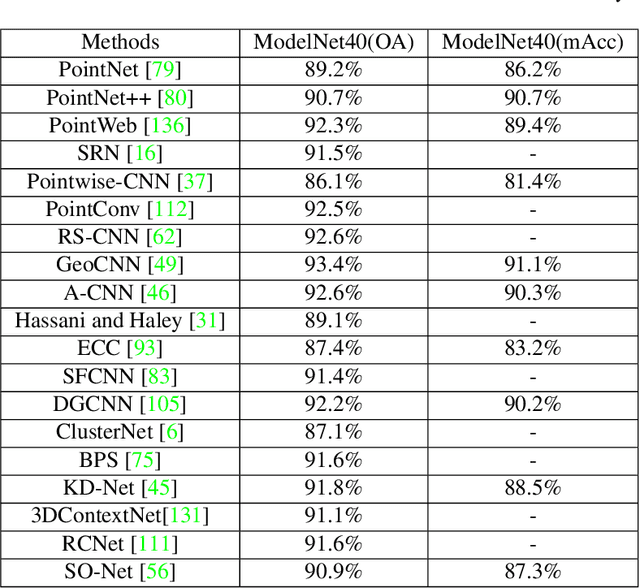
The development of practical applications, such as autonomous driving and robotics, has brought increasing attention to 3D point cloud understanding. While deep learning has achieved remarkable success on image-based tasks, there are many unique challenges faced by deep neural networks in processing massive, unstructured and noisy 3D points. To demonstrate the latest progress of deep learning for 3D point cloud understanding, this paper summarizes recent remarkable research contributions in this area from several different directions (classification, segmentation, detection, tracking, flow estimation, registration, augmentation and completion), together with commonly used datasets, metrics and state-of-the-art performances. More information regarding this survey can be found at: https://github.com/SHI-Labs/3D-Point-Cloud-Learning.
A Few-Shot Sequential Approach for Object Counting
Jul 03, 2020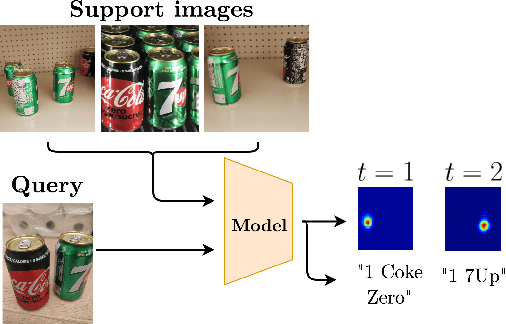
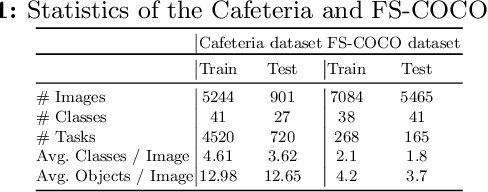
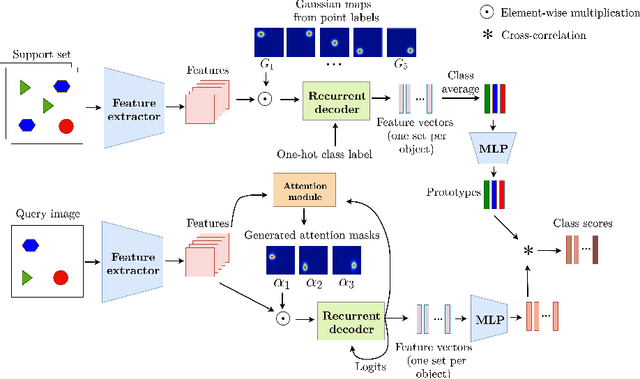
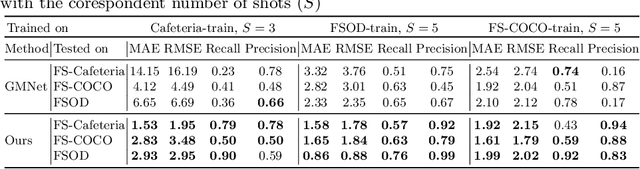
In this work, we address the problem of few-shot multi-classobject counting with point-level annotations. The proposed techniqueleverages a class agnostic attention mechanism that sequentially attendsto objects in the image and extracts their relevant features. This pro-cess is employed on an adapted prototypical-based few-shot approachthat uses the extracted features to classify each one either as one of theclasses present in the support set images or as background. The proposedtechnique is trained on point-level annotations and uses a novel loss func-tion that disentangles class-dependent and class-agnostic aspects of themodel to help with the task of few-shot object counting. We presentour results on a variety of object-counting/detection datasets, includingFSOD and MS COCO. In addition, we introduce a new dataset thatis specifically designed for weakly supervised multi-class object count-ing/detection and contains considerably different classes and distribu-tion of number of classes/instances per image compared to the existingdatasets. We demonstrate the robustness of our approach by testing oursystem on a totally different distribution of classes from what it has beentrained on
ViDi: Descriptive Visual Data Clustering as Radiologist Assistant in COVID-19 Streamline Diagnostic
Nov 30, 2020
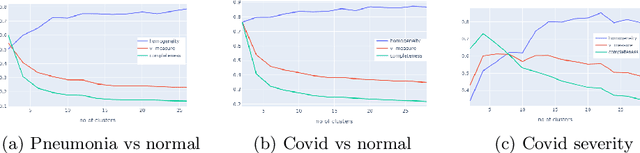

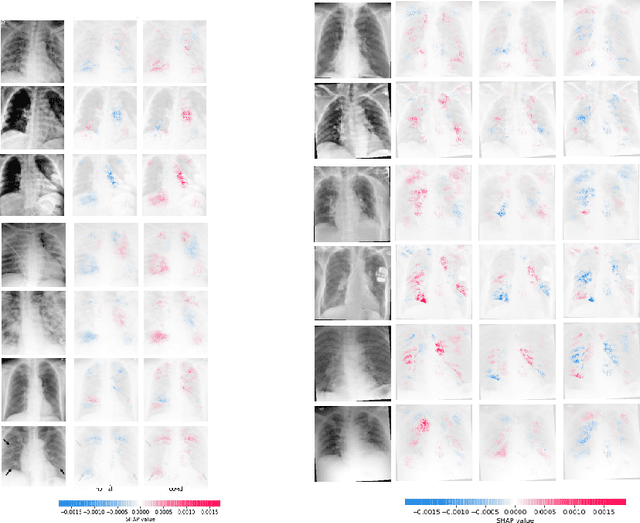
In the light of the COVID-19 pandemic, deep learning methods have been widely investigated in detecting COVID-19 from chest X-rays. However, a more pragmatic approach to applying AI methods to a medical diagnosis is designing a framework that facilitates human-machine interaction and expert decision making. Studies have shown that categorization can play an essential rule in accelerating real-world decision making. Inspired by descriptive document clustering, we propose a domain-independent explanatory clustering framework to group contextually related instances and support radiologists' decision making. While most descriptive clustering approaches employ domain-specific characteristics to form meaningful clusters, we focus on model-level explanation as a more general-purpose element of every learning process to achieve cluster homogeneity. We employ DeepSHAP to generate homogeneous clusters in terms of disease severity and describe the clusters using favorable and unfavorable saliency maps, which visualize the class discriminating regions of an image. These human-interpretable maps complement radiologist knowledge to investigate the whole cluster at once. Besides, as part of this study, we evaluate a model based on VGG-19, which can identify COVID and pneumonia cases with a positive predictive value of 95% and 97%, respectively, comparable to the recent explainable approaches for COVID diagnosis.
Lipschitz Bounded Equilibrium Networks
Oct 05, 2020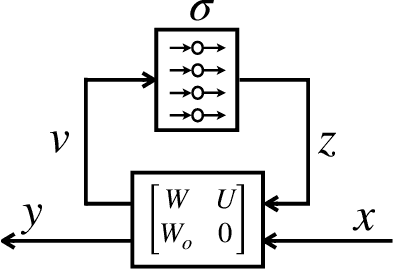
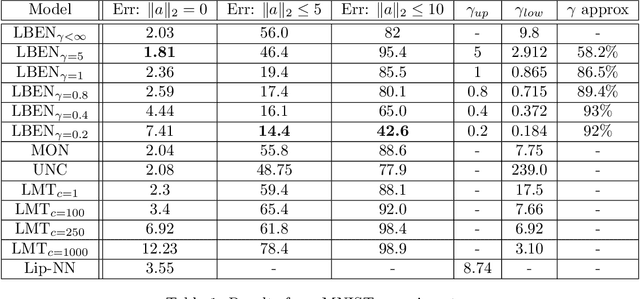
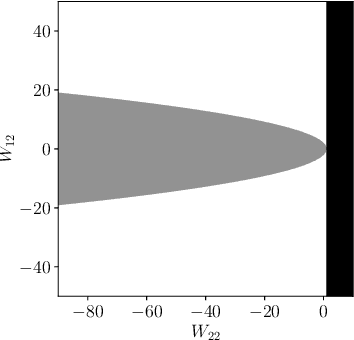

This paper introduces new parameterizations of equilibrium neural networks, i.e. networks defined by implicit equations. This model class includes standard multilayer and residual networks as special cases. The new parameterization admits a Lipschitz bound during training via unconstrained optimization: no projections or barrier functions are required. Lipschitz bounds are a common proxy for robustness and appear in many generalization bounds. Furthermore, compared to previous works we show well-posedness (existence of solutions) under less restrictive conditions on the network weights and more natural assumptions on the activation functions: that they are monotone and slope restricted. These results are proved by establishing novel connections with convex optimization, operator splitting on non-Euclidean spaces, and contracting neural ODEs. In image classification experiments we show that the Lipschitz bounds are very accurate and improve robustness to adversarial attacks.
Feature Selection Using Batch-Wise Attenuation and Feature Mask Normalization
Oct 26, 2020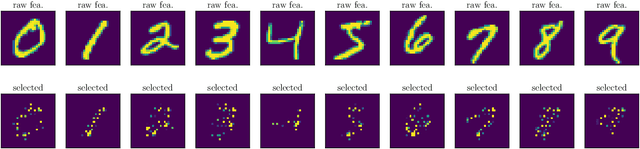
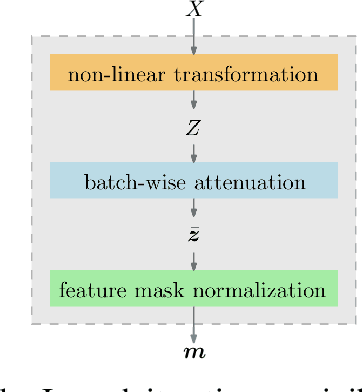
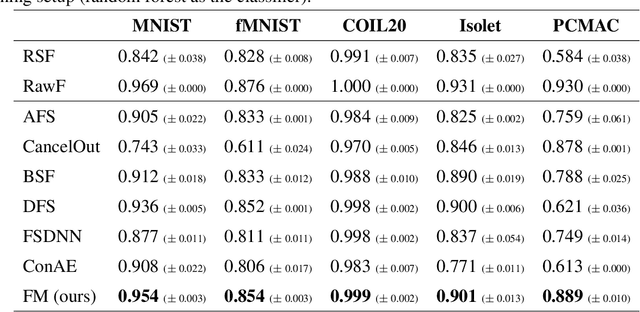
Feature selection is generally used as one of the most important pre-processing techniques in machine learning, as it helps to reduce the dimensionality of data and assists researchers and practitioners in understanding data. Thereby, better performance and reduced computational consumption, memory complexity and even data amount can be expected by utilizing feature selection. However, only few studies leverage the power of deep neural networks to solve the problem of feature selection. In this paper, we propose a feature mask module (FM-module) for feature selection based on a novel batch-wise attenuation and feature mask normalization. The proposed method is almost free from hyperparameters and can be easily integrated into common neural networks as an embedded feature selection method. Experiments on popular image, text and speech datasets have been shown that our approach is easy to use and has superior performance in comparison with other state-of-the-art deep learning based feature selection methods.
Towards Scale-Invariant Graph-related Problem Solving by Iterative Homogeneous Graph Neural Networks
Oct 26, 2020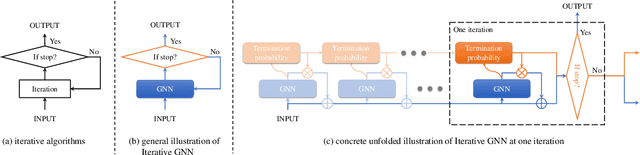
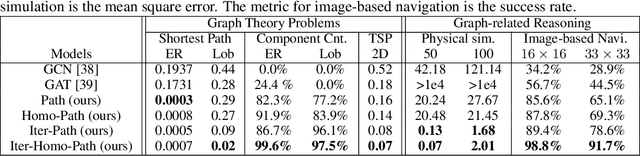
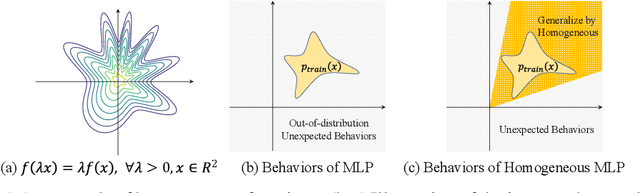

Current graph neural networks (GNNs) lack generalizability with respect to scales (graph sizes, graph diameters, edge weights, etc..) when solving many graph analysis problems. Taking the perspective of synthesizing graph theory programs, we propose several extensions to address the issue. First, inspired by the dependency of the iteration number of common graph theory algorithms on graph size, we learn to terminate the message passing process in GNNs adaptively according to the computation progress. Second, inspired by the fact that many graph theory algorithms are homogeneous with respect to graph weights, we introduce homogeneous transformation layers that are universal homogeneous function approximators, to convert ordinary GNNs to be homogeneous. Experimentally, we show that our GNN can be trained from small-scale graphs but generalize well to large-scale graphs for a number of basic graph theory problems. It also shows generalizability for applications of multi-body physical simulation and image-based navigation problems.
LGVTON: A Landmark Guided Approach to Virtual Try-On
Apr 01, 2020



We address the problem of image based virtual try-on (VTON), where the goal is to synthesize an image of a person wearing the cloth of a model. An essential requirement for generating a perceptually convincing VTON result is preserving the characteristics of the cloth and the person. Keeping this in mind we propose \textit{LGVTON}, a novel self-supervised landmark guided approach to image based virtual try-on. The incorporation of self-supervision tackles the problem of lack of paired training data in model to person VTON scenario. LGVTON uses two types of landmarks to warp the model cloth according to the shape and pose of the person, one, human landmarks, the locations of anatomical keypoints of human, two, fashion landmarks, the structural keypoints of cloth. We introduce an unique way of using landmarks for warping which is more efficient and effective compared to existing warping based methods in current problem scenario. In addition to that, to make the method robust in cases of noisy landmark estimates that causes inaccurate warping, we propose a mask generator module that attempts to predict the true segmentation mask of the model cloth on the person, which in turn guides our image synthesizer module in tackling warping issues. Experimental results show the effectiveness of our method in comparison to the state-of-the-art VTON methods.
Deep Line Art Video Colorization with a Few References
Mar 30, 2020

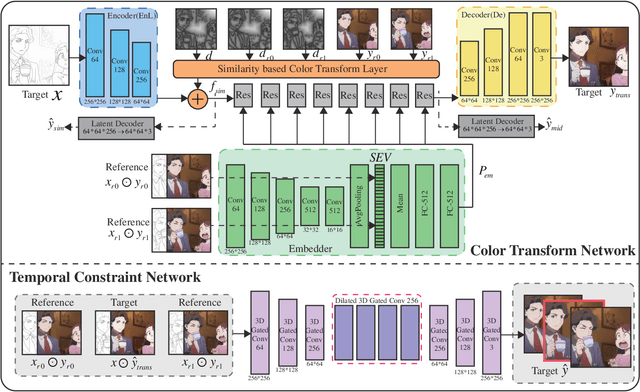

Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.