 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompt to Production:Automating Brand-Safe Marketing Imagery with Text-to-Image Models
Feb 12, 2026Text-to-image models have made significant strides, producing impressive results in generating images from textual descriptions. However, creating a scalable pipeline for deploying these models in production remains a challenge. Achieving the right balance between automation and human feedback is critical to maintain both scale and quality. While automation can handle large volumes, human oversight is still an essential component to ensure that the generated images meet the desired standards and are aligned with the creative vision. This paper presents a new pipeline that offers a fully automated, scalable solution for generating marketing images of commercial products using text-to-image models. The proposed system maintains the quality and fidelity of images, while also introducing sufficient creative variation to adhere to marketing guidelines. By streamlining this process, we ensure a seamless blend of efficiency and human oversight, achieving a $30.77\%$ increase in marketing object fidelity using DINOV2 and a $52.00\%$ increase in human preference over the generated outcome.
Improved Few-Shot Image Classification Through Multiple-Choice Questions
Jul 23, 2024Through a simple multiple choice language prompt a VQA model can operate as a zero-shot image classifier, producing a classification label. Compared to typical image encoders, VQA models offer an advantage: VQA-produced image embeddings can be infused with the most relevant visual information through tailored language prompts. Nevertheless, for most tasks, zero-shot VQA performance is lacking, either because of unfamiliar category names, or dissimilar pre-training data and test data distributions. We propose a simple method to boost VQA performance for image classification using only a handful of labeled examples and a multiple-choice question. This few-shot method is training-free and maintains the dynamic and flexible advantages of the VQA model. Rather than relying on the final language output, our approach uses multiple-choice questions to extract prompt-specific latent representations, which are enriched with relevant visual information. These representations are combined to create a final overall image embedding, which is decoded via reference to latent class prototypes constructed from the few labeled examples. We demonstrate this method outperforms both pure visual encoders and zero-shot VQA baselines to achieve impressive performance on common few-shot tasks including MiniImageNet, Caltech-UCSD Birds, and CIFAR-100. Finally, we show our approach does particularly well in settings with numerous diverse visual attributes such as the fabric, article-style, texture, and view of different articles of clothing, where other few-shot approaches struggle, as we can tailor our image representations only on the semantic features of interest.
Automated Virtual Product Placement and Assessment in Images using Diffusion Models
May 02, 2024In Virtual Product Placement (VPP) applications, the discrete integration of specific brand products into images or videos has emerged as a challenging yet important task. This paper introduces a novel three-stage fully automated VPP system. In the first stage, a language-guided image segmentation model identifies optimal regions within images for product inpainting. In the second stage, Stable Diffusion (SD), fine-tuned with a few example product images, is used to inpaint the product into the previously identified candidate regions. The final stage introduces an "Alignment Module", which is designed to effectively sieve out low-quality images. Comprehensive experiments demonstrate that the Alignment Module ensures the presence of the intended product in every generated image and enhances the average quality of images by 35%. The results presented in this paper demonstrate the effectiveness of the proposed VPP system, which holds significant potential for transforming the landscape of virtual advertising and marketing strategies.
DocBed: A Multi-Stage OCR Solution for Documents with Complex Layouts
Feb 03, 2022
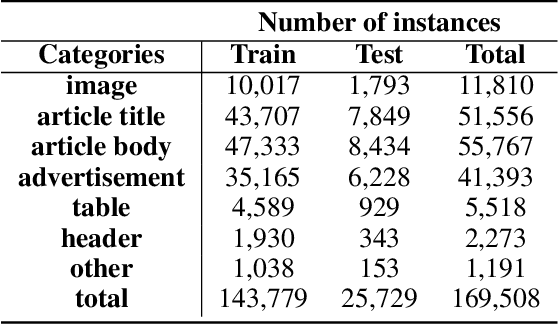
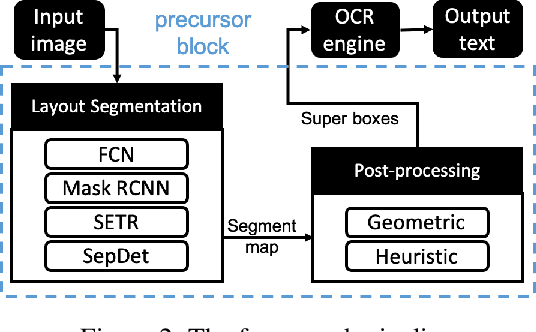
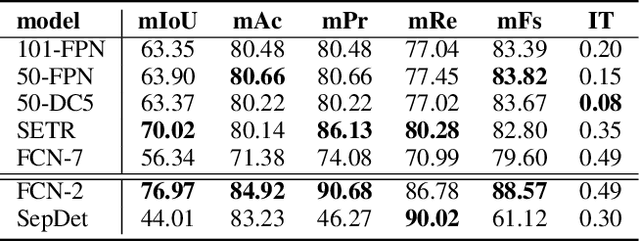
Digitization of newspapers is of interest for many reasons including preservation of history, accessibility and search ability, etc. While digitization of documents such as scientific articles and magazines is prevalent in literature, one of the main challenges for digitization of newspaper lies in its complex layout (e.g. articles spanning multiple columns, text interrupted by images) analysis, which is necessary to preserve human read-order. This work provides a major breakthrough in the digitization of newspapers on three fronts: first, releasing a dataset of 3000 fully-annotated, real-world newspaper images from 21 different U.S. states representing an extensive variety of complex layouts for document layout analysis; second, proposing layout segmentation as a precursor to existing optical character recognition (OCR) engines, where multiple state-of-the-art image segmentation models and several post-processing methods are explored for document layout segmentation; third, providing a thorough and structured evaluation protocol for isolated layout segmentation and end-to-end OCR.
A Few-Shot Sequential Approach for Object Counting
Jul 07, 2020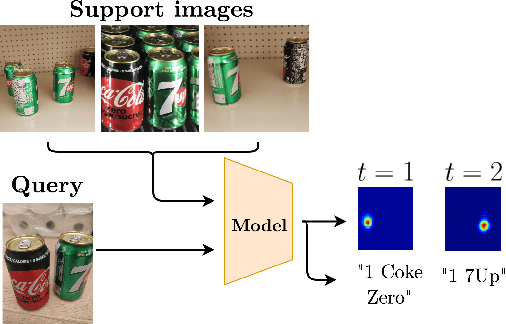
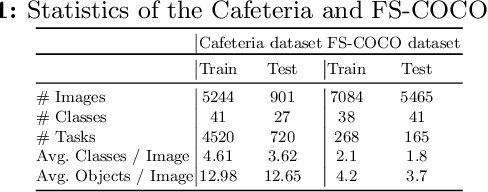
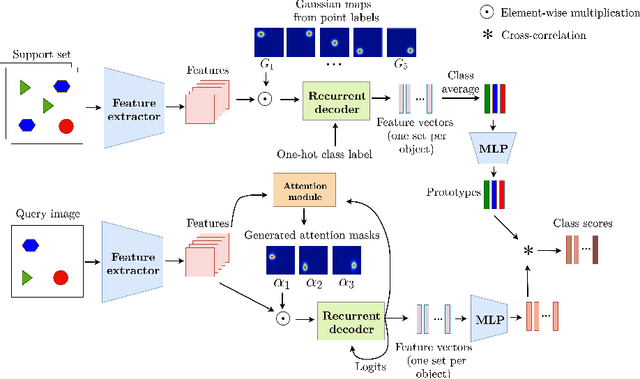
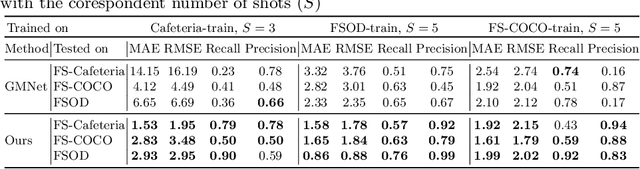
In this work, we address the problem of few-shot multi-class object counting with point-level annotations. The proposed technique leverages a class agnostic attention mechanism that sequentially attends to objects in the image and extracts their relevant features. This process is employed on an adapted prototypical-based few-shot approach that uses the extracted features to classify each one either as one of the classes present in the support set images or as background. The proposed technique is trained on point-level annotations and uses a novel loss function that disentangles class-dependent and class-agnostic aspects of the model to help with the task of few-shot object counting. We present our results on a variety of object-counting/detection datasets, including FSOD and MS COCO. In addition, we introduce a new dataset that is specifically designed for weakly supervised multi-class object counting/detection and contains considerably different classes and distribution of number of classes/instances per image compared to the existing datasets. We demonstrate the robustness of our approach by testing our system on a totally different distribution of classes from what it has been trained on.