 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Semantic Aggregation for Contrastive Representation Learning
Dec 04, 2020
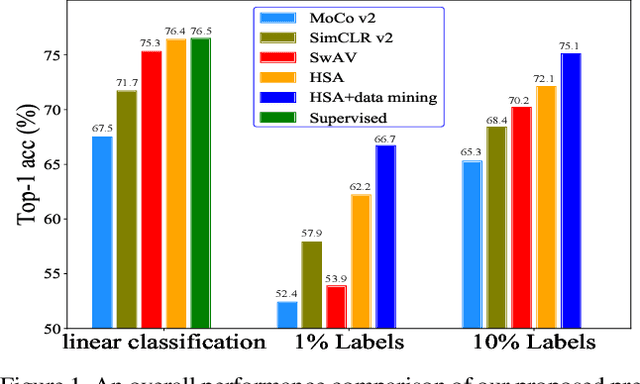
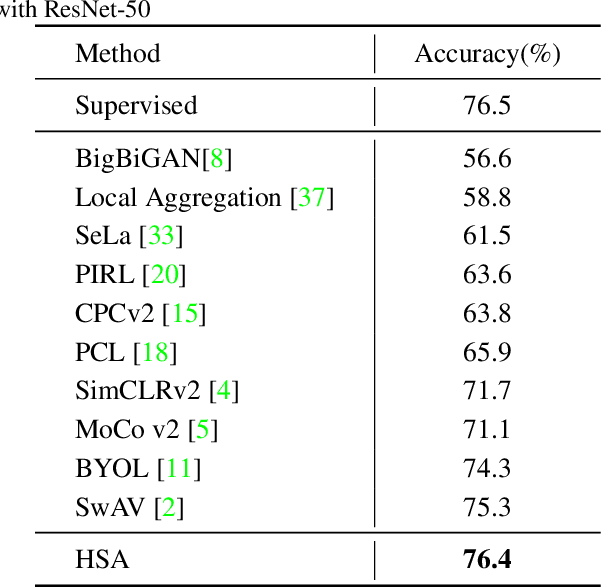
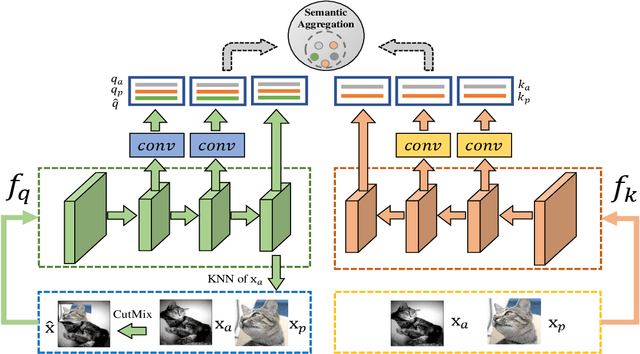
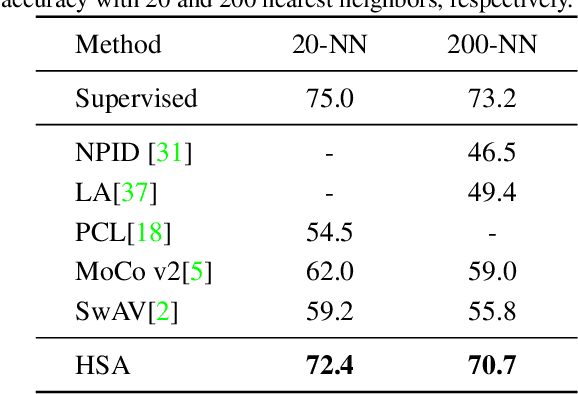
Self-supervised learning based on instance discrimination has shown remarkable progress. In particular, contrastive learning, which regards each image as well as its augmentations as a separate class, and pushes all other images away, has been proved effective for pretraining. However, contrasting two images that are de facto similar in semantic space is hard for optimization and not applicable for general representations. In this paper, we tackle the representation inefficiency of contrastive learning and propose a hierarchical training strategy to explicitly model the invariance to semantic similar images in a bottom-up way. This is achieved by extending the contrastive loss to allow for multiple positives per anchor, and explicitly pulling semantically similar images/patches together at the earlier layers as well as the last embedding space. In this way, we are able to learn feature representation that is more discriminative throughout different layers, which we find is beneficial for fast convergence. The hierarchical semantic aggregation strategy produces more discriminative representation on several unsupervised benchmarks. Notably, on ImageNet with ResNet-50 as backbone, we reach $76.4\%$ top-1 accuracy with linear evaluation, and $75.1\%$ top-1 accuracy with only $10\%$ labels.
Highly Scalable Image Reconstruction using Deep Neural Networks with Bandpass Filtering
May 08, 2018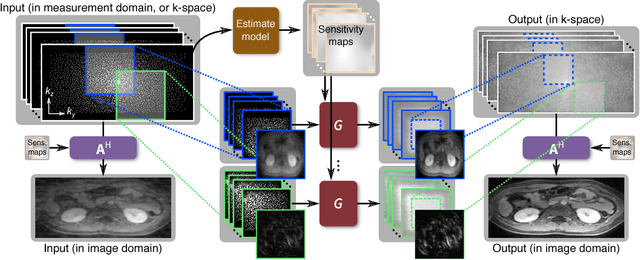
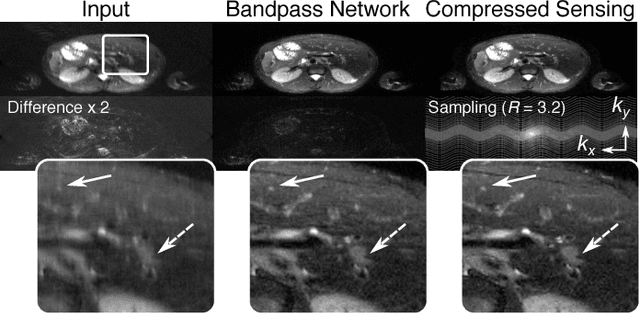
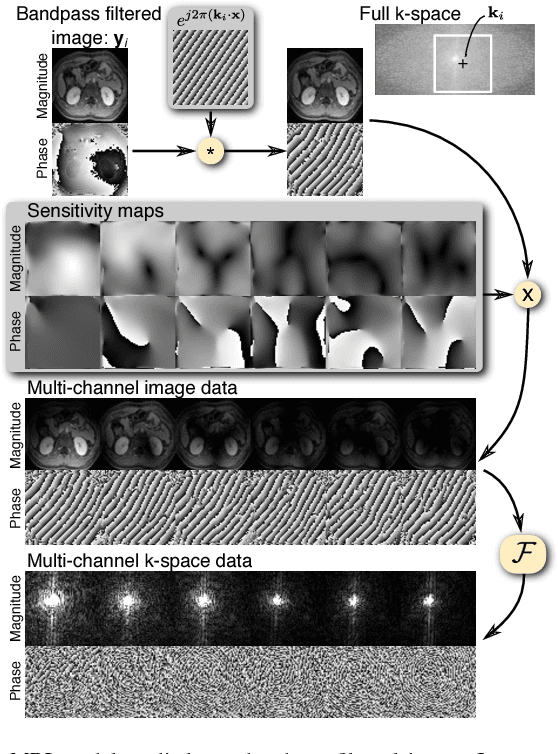
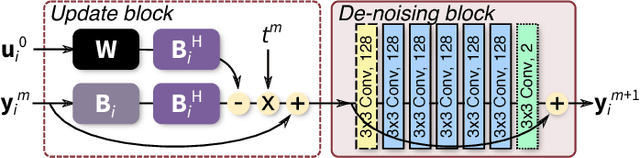
To increase the flexibility and scalability of deep neural networks for image reconstruction, a framework is proposed based on bandpass filtering. For many applications, sensing measurements are performed indirectly. For example, in magnetic resonance imaging, data are sampled in the frequency domain. The introduction of bandpass filtering enables leveraging known imaging physics while ensuring that the final reconstruction is consistent with actual measurements to maintain reconstruction accuracy. We demonstrate this flexible architecture for reconstructing subsampled datasets of MRI scans. The resulting high subsampling rates increase the speed of MRI acquisitions and enable the visualization rapid hemodynamics.
Practical No-box Adversarial Attacks against DNNs
Dec 04, 2020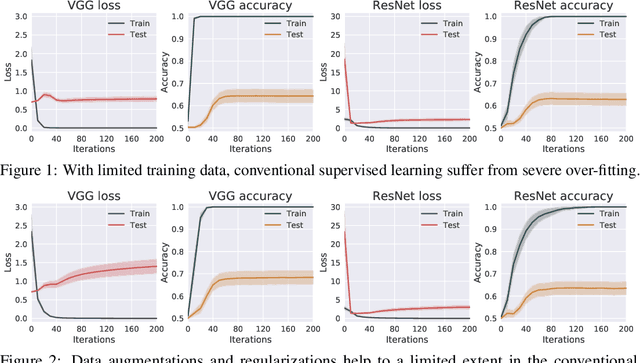
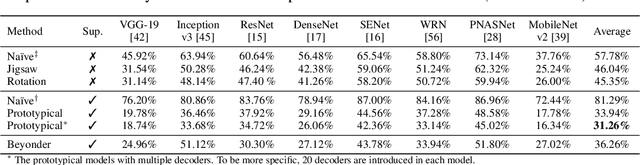
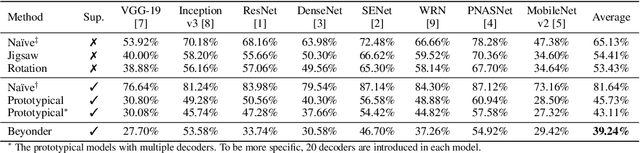
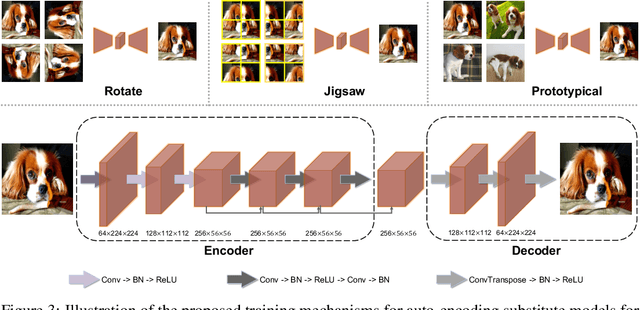
The study of adversarial vulnerabilities of deep neural networks (DNNs) has progressed rapidly. Existing attacks require either internal access (to the architecture, parameters, or training set of the victim model) or external access (to query the model). However, both the access may be infeasible or expensive in many scenarios. We investigate no-box adversarial examples, where the attacker can neither access the model information or the training set nor query the model. Instead, the attacker can only gather a small number of examples from the same problem domain as that of the victim model. Such a stronger threat model greatly expands the applicability of adversarial attacks. We propose three mechanisms for training with a very small dataset (on the order of tens of examples) and find that prototypical reconstruction is the most effective. Our experiments show that adversarial examples crafted on prototypical auto-encoding models transfer well to a variety of image classification and face verification models. On a commercial celebrity recognition system held by clarifai.com, our approach significantly diminishes the average prediction accuracy of the system to only 15.40%, which is on par with the attack that transfers adversarial examples from a pre-trained Arcface model.
Stereo Frustums: A Siamese Pipeline for 3D Object Detection
Oct 27, 2020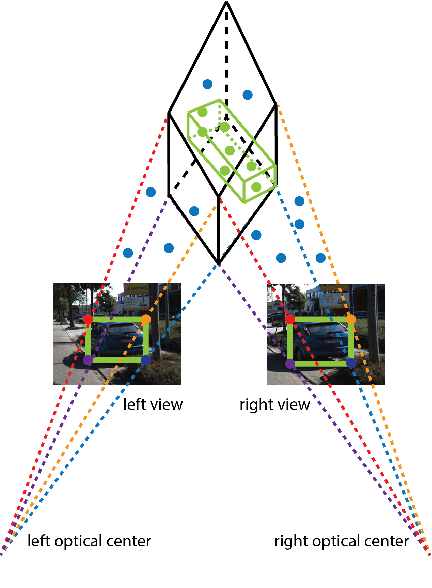
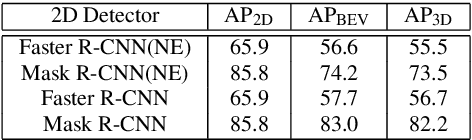
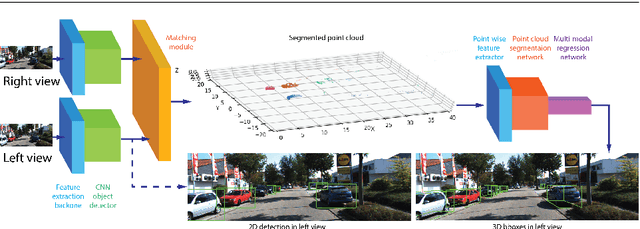
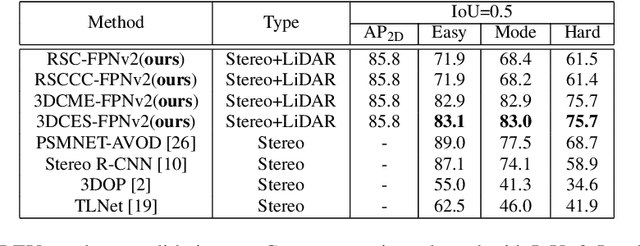
The paper proposes a light-weighted stereo frustums matching module for 3D objection detection. The proposed framework takes advantage of a high-performance 2D detector and a point cloud segmentation network to regress 3D bounding boxes for autonomous driving vehicles. Instead of performing traditional stereo matching to compute disparities, the module directly takes the 2D proposals from both the left and the right views as input. Based on the epipolar constraints recovered from the well-calibrated stereo cameras, we propose four matching algorithms to search for the best match for each proposal between the stereo image pairs. Each matching pair proposes a segmentation of the scene which is then fed into a 3D bounding box regression network. Results of extensive experiments on KITTI dataset demonstrate that the proposed Siamese pipeline outperforms the state-of-the-art stereo-based 3D bounding box regression methods.
Localized Interactive Instance Segmentation
Oct 20, 2020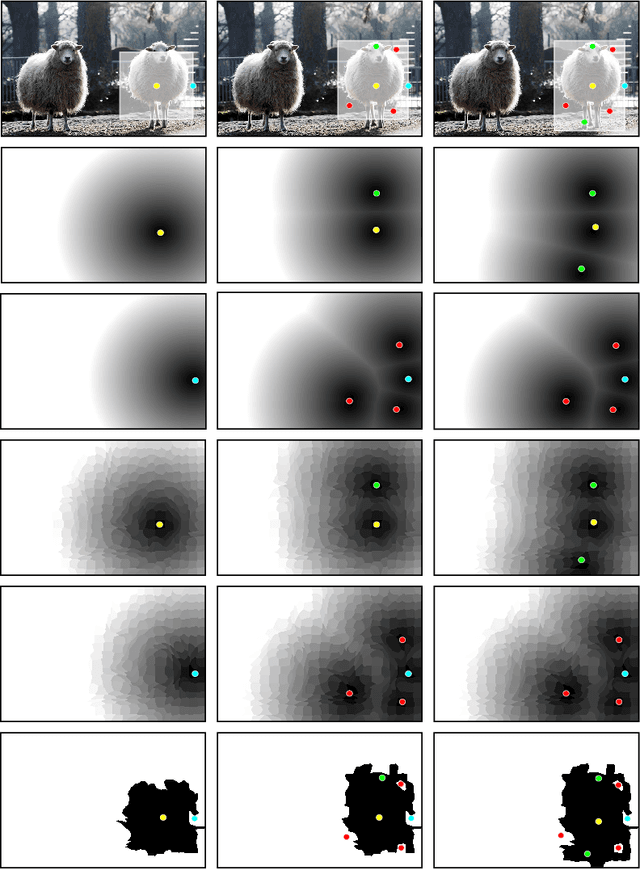
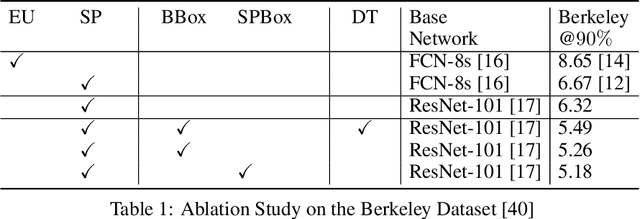
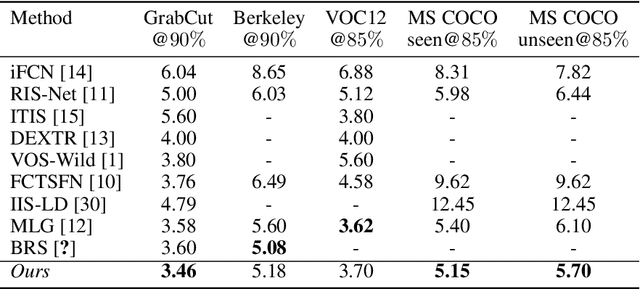

In current interactive instance segmentation works, the user is granted a free hand when providing clicks to segment an object; clicks are allowed on background pixels and other object instances far from the target object. This form of interaction is highly inconsistent with the end goal of efficiently isolating objects of interest. In our work, we propose a clicking scheme wherein user interactions are restricted to the proximity of the object. In addition, we propose a novel transformation of the user-provided clicks to generate a weak localization prior on the object which is consistent with image structures such as edges, textures etc. We demonstrate the effectiveness of our proposed clicking scheme and localization strategy through detailed experimentation in which we raise state-of-the-art on several standard interactive segmentation benchmarks.
Robust and On-the-fly Dataset Denoising for Image Classification
Mar 24, 2020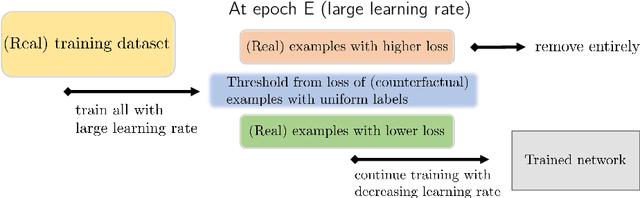
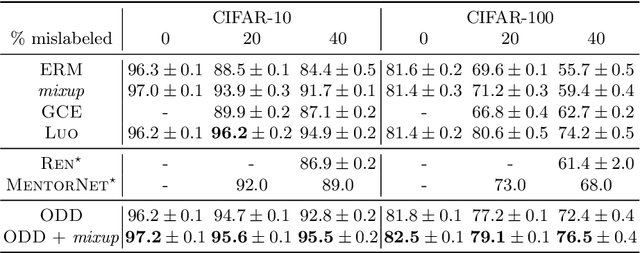

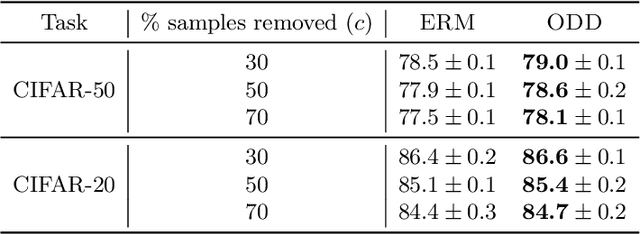
Memorization in over-parameterized neural networks could severely hurt generalization in the presence of mislabeled examples. However, mislabeled examples are hard to avoid in extremely large datasets collected with weak supervision. We address this problem by reasoning counterfactually about the loss distribution of examples with uniform random labels had they were trained with the real examples, and use this information to remove noisy examples from the training set. First, we observe that examples with uniform random labels have higher losses when trained with stochastic gradient descent under large learning rates. Then, we propose to model the loss distribution of the counterfactual examples using only the network parameters, which is able to model such examples with remarkable success. Finally, we propose to remove examples whose loss exceeds a certain quantile of the modeled loss distribution. This leads to On-the-fly Data Denoising (ODD), a simple yet effective algorithm that is robust to mislabeled examples, while introducing almost zero computational overhead compared to standard training. ODD is able to achieve state-of-the-art results on a wide range of datasets including real-world ones such as WebVision and Clothing1M.
Learning Collision-Free Space Detection from Stereo Images: Homography Matrix Brings Better Data Augmentation
Dec 14, 2020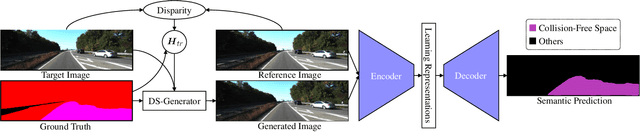
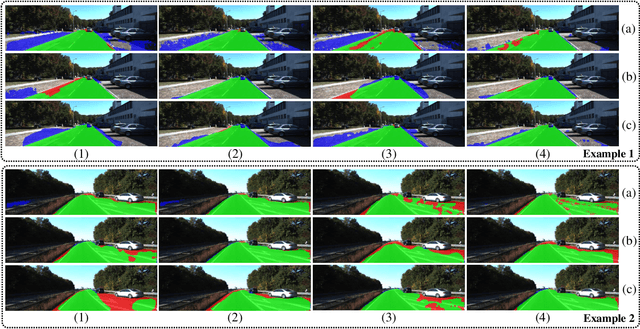

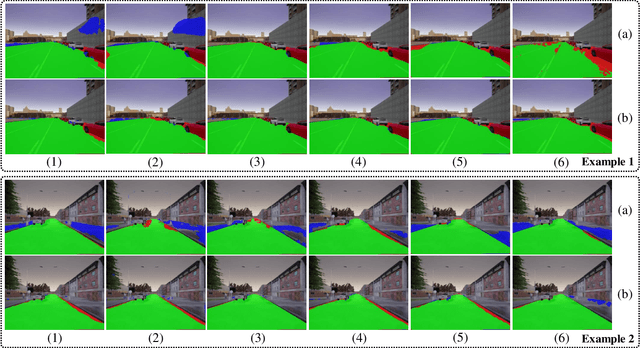
Collision-free space detection is a critical component of autonomous vehicle perception. The state-of-the-art algorithms are typically based on supervised learning. The performance of such approaches is always dependent on the quality and amount of labeled training data. Additionally, it remains an open challenge to train deep convolutional neural networks (DCNNs) using only a small quantity of training samples. Therefore, this paper mainly explores an effective training data augmentation approach that can be employed to improve the overall DCNN performance, when additional images captured from different views are available. Due to the fact that the pixels of the collision-free space (generally regarded as a planar surface) between two images captured from different views can be associated by a homography matrix, the scenario of the target image can be transformed into the reference view. This provides a simple but effective way of generating training data from additional multi-view images. Extensive experimental results, conducted with six state-of-the-art semantic segmentation DCNNs on three datasets, demonstrate the effectiveness of our proposed training data augmentation algorithm for enhancing collision-free space detection performance. When validated on the KITTI road benchmark, our approach provides the best results for stereo vision-based collision-free space detection.
Ensemble learning of diffractive optical networks
Sep 15, 2020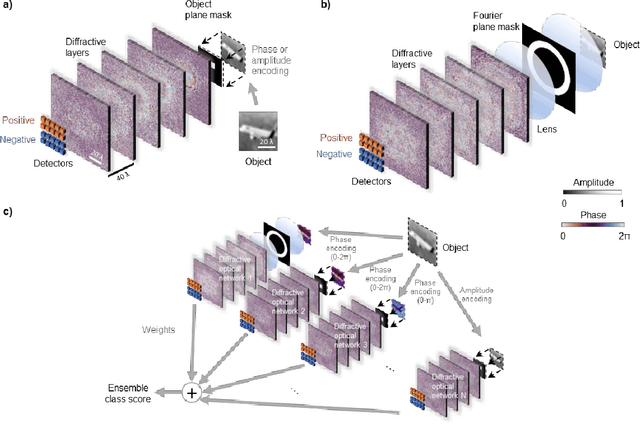
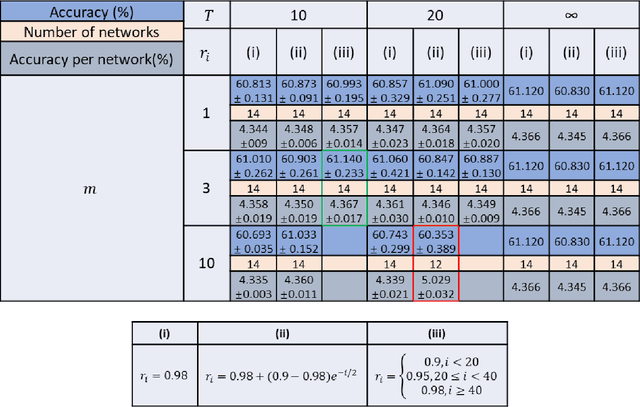
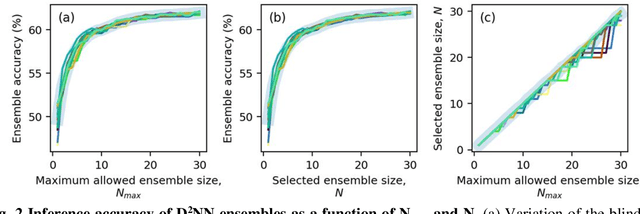
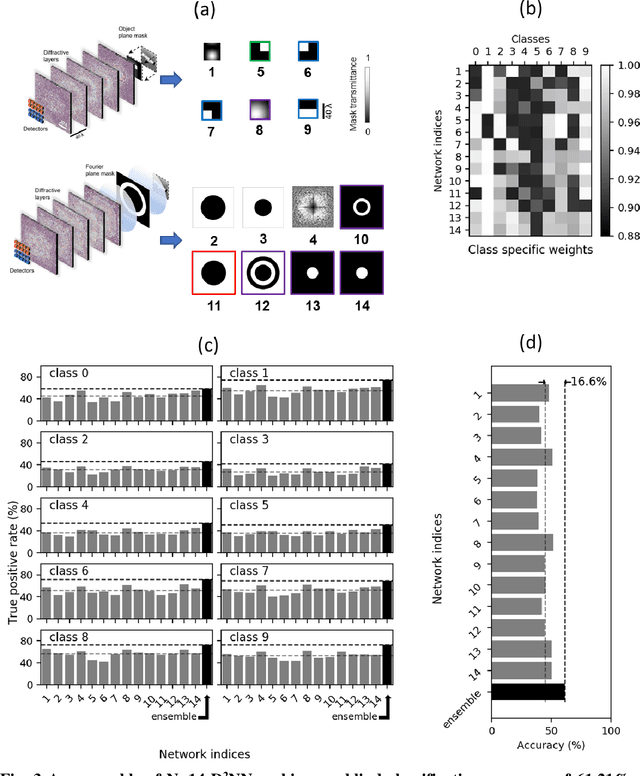
A plethora of research advances have emerged in the fields of optics and photonics that benefit from harnessing the power of machine learning. Specifically, there has been a revival of interest in optical computing hardware, due to its potential advantages for machine learning tasks in terms of parallelization, power efficiency and computation speed. Diffractive Deep Neural Networks (D2NNs) form such an optical computing framework, which benefits from deep learning-based design of successive diffractive layers to all-optically process information as the input light diffracts through these passive layers. D2NNs have demonstrated success in various tasks, including e.g., object classification, spectral-encoding of information, optical pulse shaping and imaging, among others. Here, we significantly improve the inference performance of diffractive optical networks using feature engineering and ensemble learning. After independently training a total of 1252 D2NNs that were diversely engineered with a variety of passive input filters, we applied a pruning algorithm to select an optimized ensemble of D2NNs that collectively improve their image classification accuracy. Through this pruning, we numerically demonstrated that ensembles of N=14 and N=30 D2NNs achieve blind testing accuracies of 61.14% and 62.13%, respectively, on the classification of CIFAR-10 test images, providing an inference improvement of >16% compared to the average performance of the individual D2NNs within each ensemble. These results constitute the highest inference accuracies achieved to date by any diffractive optical neural network design on the same dataset and might provide a significant leapfrog to extend the application space of diffractive optical image classification and machine vision systems.
Dynamic memory to alleviate catastrophic forgetting in continuous learning settings
Jul 07, 2020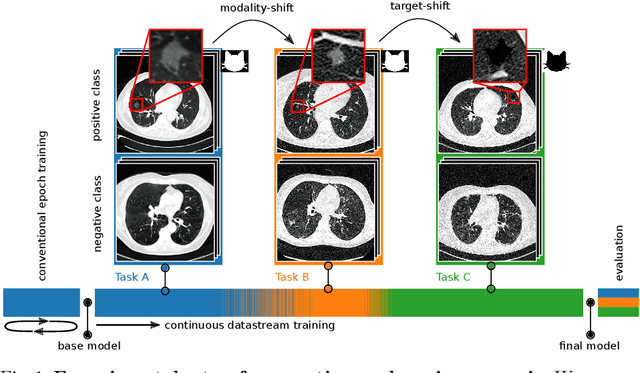
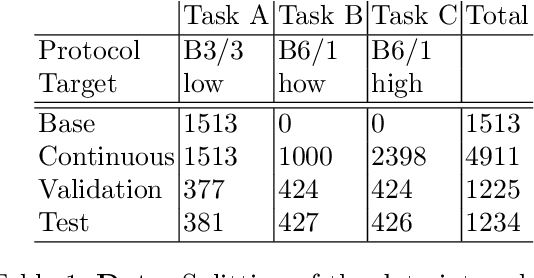
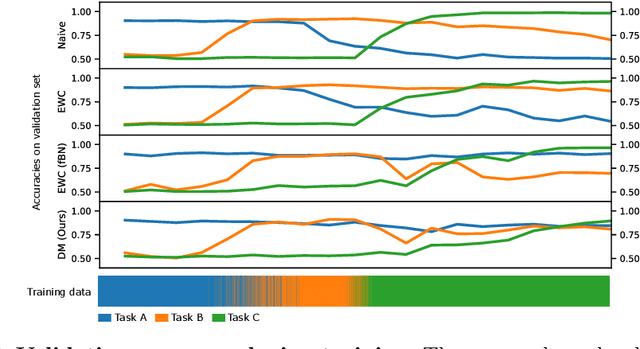
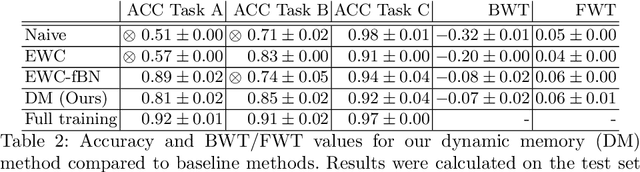
In medical imaging, technical progress or changes in diagnostic procedures lead to a continuous change in image appearance. Scanner manufacturer, reconstruction kernel, dose, other protocol specific settings or administering of contrast agents are examples that influence image content independent of the scanned biology. Such domain and task shifts limit the applicability of machine learning algorithms in the clinical routine by rendering models obsolete over time. Here, we address the problem of data shifts in a continuous learning scenario by adapting a model to unseen variations in the source domain while counteracting catastrophic forgetting effects. Our method uses a dynamic memory to facilitate rehearsal of a diverse training data subset to mitigate forgetting. We evaluated our approach on routine clinical CT data obtained with two different scanner protocols and synthetic classification tasks. Experiments show that dynamic memory counters catastrophic forgetting in a setting with multiple data shifts without the necessity for explicit knowledge about when these shifts occur.
Fully automated 3D segmentation of dopamine transporter SPECT images using an estimation-based approach
Jan 17, 2021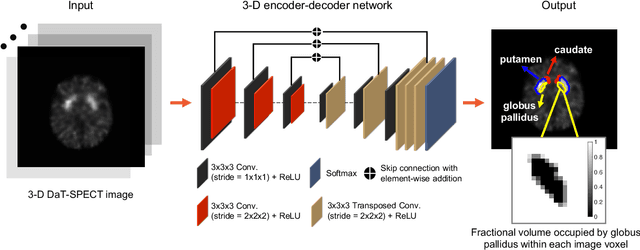
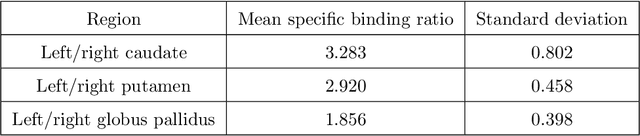
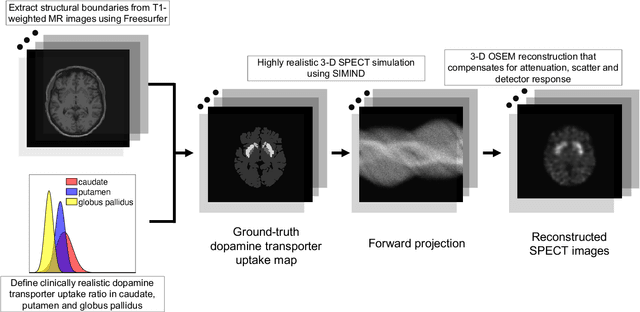
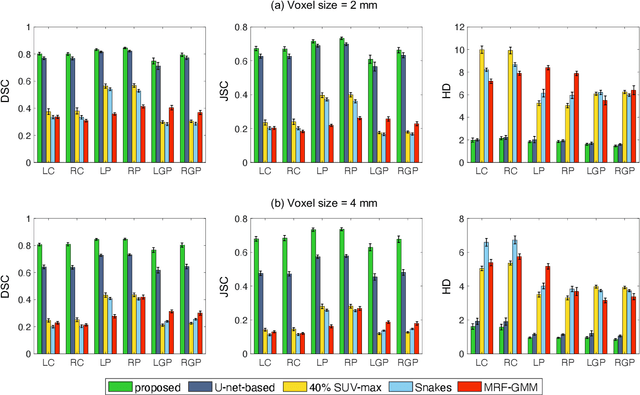
Quantitative measures of uptake in caudate, putamen, and globus pallidus in dopamine transporter (DaT) brain SPECT have potential as biomarkers for the severity of Parkinson disease. Reliable quantification of uptake requires accurate segmentation of these regions. However, segmentation is challenging in DaT SPECT due to partial-volume effects, system noise, physiological variability, and the small size of these regions. To address these challenges, we propose an estimation-based approach to segmentation. This approach estimates the posterior mean of the fractional volume occupied by caudate, putamen, and globus pallidus within each voxel of a 3D SPECT image. The estimate is obtained by minimizing a cost function based on the binary cross-entropy loss between the true and estimated fractional volumes over a population of SPECT images, where the distribution of the true fractional volumes is obtained from magnetic resonance images from clinical populations. The proposed method accounts for both the sources of partial-volume effects in SPECT, namely the limited system resolution and tissue-fraction effects. The method was implemented using an encoder-decoder network and evaluated using realistic clinically guided SPECT simulation studies, where the ground-truth fractional volumes were known. The method significantly outperformed all other considered segmentation methods and yielded accurate segmentation with dice similarity coefficients of ~ 0.80 for all regions. The method was relatively insensitive to changes in voxel size. Further, the method was relatively robust up to +/- 10 degrees of patient head tilt along transaxial, sagittal, and coronal planes. Overall, the results demonstrate the efficacy of the proposed method to yield accurate fully automated segmentation of caudate, putamen, and globus pallidus in 3D DaT-SPECT images.