 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020
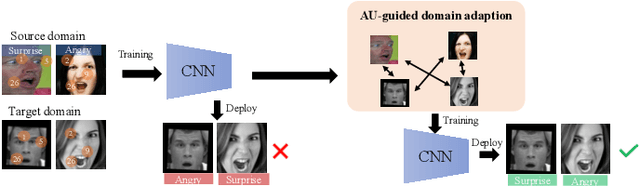
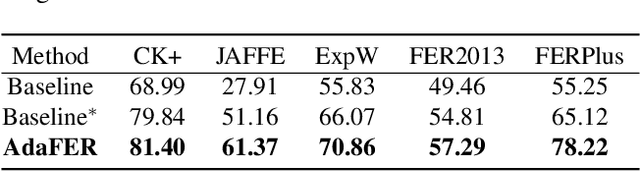
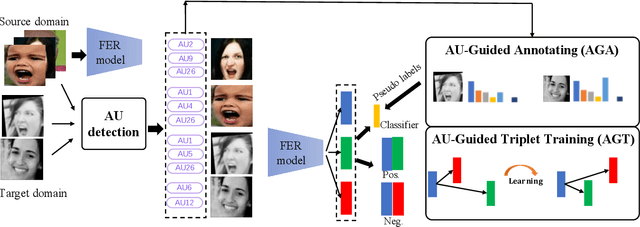
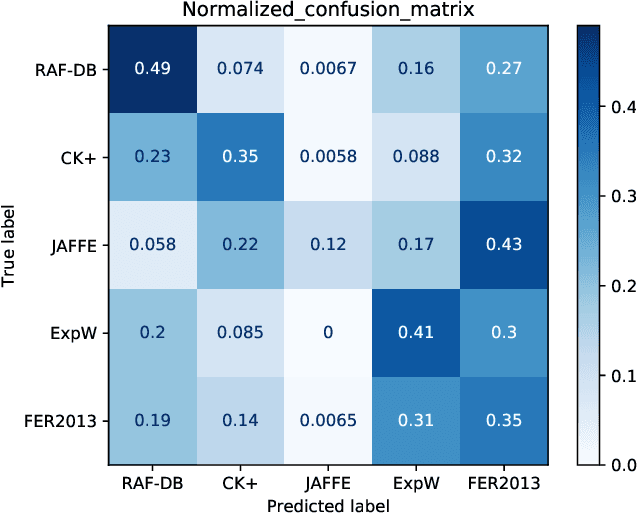
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
Object Detection-Based Variable Quantization Processing
Sep 01, 2020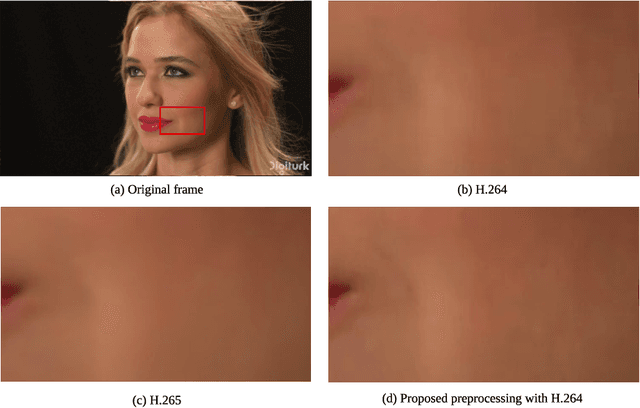
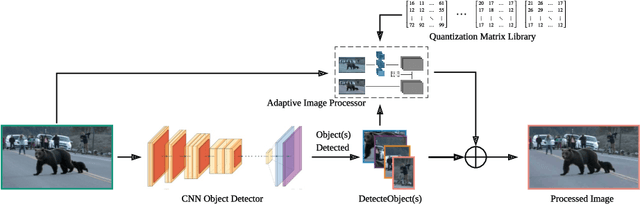
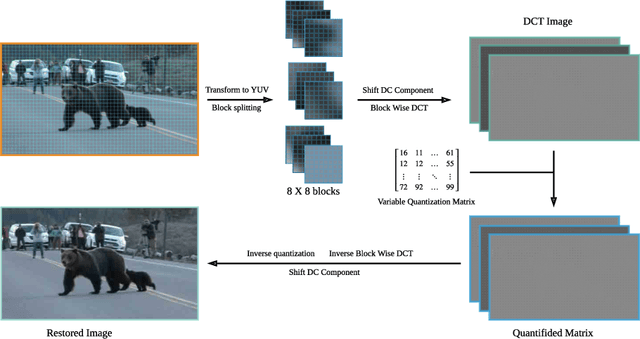
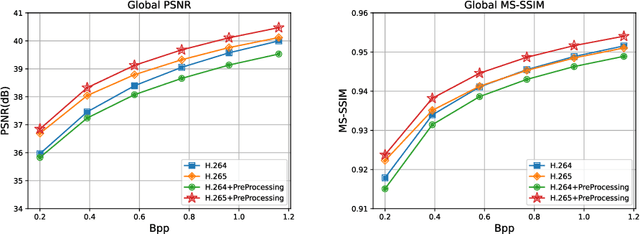
In this paper, we propose a preprocessing method for conventional image and video encoders that can make these existing encoders content-aware. By going through our process, a higher quality parameter could be set on a traditional encoder without increasing the output size. A still frame or an image will firstly go through an object detector. Either the properties of the detection result will decide the parameters of the following procedures, or the system will be bypassed if no object is detected in the given frame. The processing method utilizes an adaptive quantization process to determine the portion of data to be dropped. This method is primarily based on the JPEG compression theory and is optimum for JPEG-based encoders such as JPEG encoders and the Motion JPEG encoders. However, other DCT-based encoders like MPEG part 2, H.264, etc. can also benefit from this method. In the experiments, we compare the MS-SSIM under the same bitrate as well as similar MS-SSIM but enhanced bitrate. As this method is based on human perception, even with similar MS-SSIM, the overall watching experience will be better than the direct encoded ones.
A simulation environment for drone cinematography
Oct 03, 2020
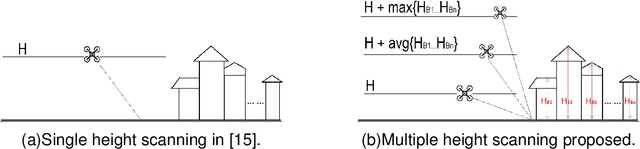

In this paper, we present a workflow for the simulation of drone operations exploiting realistic background environments constructed within Unreal Engine 4 (UE4). Methods for environmental image capture, 3D reconstruction (photogrammetry) and the creation of foreground assets are presented along with a flexible and user-friendly simulation interface. Given the geographical location of the selected area and the camera parameters employed, the scanning strategy and its associated flight parameters are first determined for image capture. Source imagery can be extracted from virtual globe software or obtained through aerial photography of the scene (e.g. using drones). The latter case is clearly more time consuming but can provide enhanced detail, particularly where coverage of virtual globe software is limited. The captured images are then used to generate 3D background environment models employing photogrammetry software. The reconstructed 3D models are then imported into the simulation interface as background environment assets together with appropriate foreground object models as a basis for shot planning and rehearsal. The tool supports both free-flight and parameterisable standard shot types along with programmable scenarios associated with foreground assets and event dynamics. It also supports the exporting of flight plans. Camera shots can also be designed to provide suitable coverage of any landmarks which need to appear in-shot. This simulation tool will contribute to enhanced productivity, improved safety (awareness and mitigations for crowds and buildings), improved confidence of operators and directors and ultimately enhanced quality of viewer experience.
An Efficient Generation Method based on Dynamic Curvature of the Reference Curve for Robust Trajectory Planning
Dec 29, 2020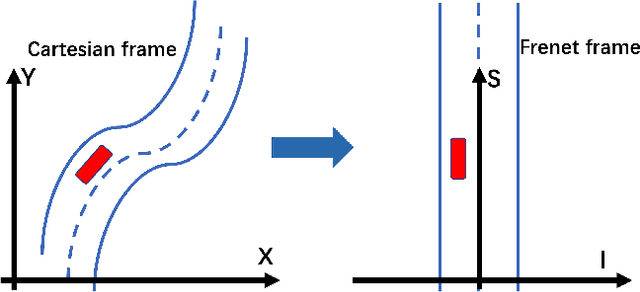
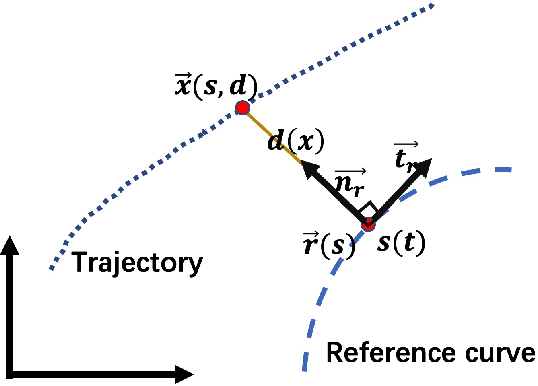
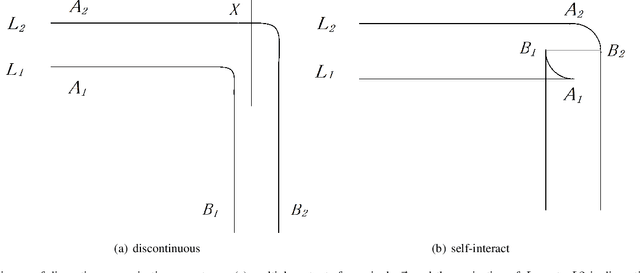
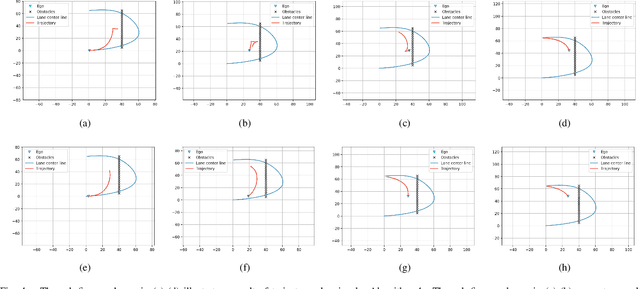
Trajectory planning is a fundamental task on various autonomous driving platforms, such as social robotics and self-driving cars. Many trajectory planning algorithms use a reference curve based Frenet frame with time to reduce the planning dimension. However, there is a common implicit assumption in classic trajectory planning approaches, which is that the generated trajectory should follow the reference curve continuously. This assumption is not always true in real applications and it might cause some undesired issues in planning. One issue is that the projection of the planned trajectory onto the reference curve maybe discontinuous. Then, some segments on the reference curve are not the image of any part of the planned path. Another issue is that the planned path might self-intersect when following a simple reference curve continuously. The generated trajectories are unnatural and suboptimal ones when these issues happen. In this paper, we firstly demonstrate these issues and then introduce an efficient trajectory generation method which uses a new transformation from the Cartesian frame to Frenet frames. Experimental results on a simulated street scenario demonstrated the effectiveness of the proposed method.
Learning normal appearance for fetal anomaly screening: Application to the unsupervised detection of Hypoplastic Left Heart Syndrome
Nov 15, 2020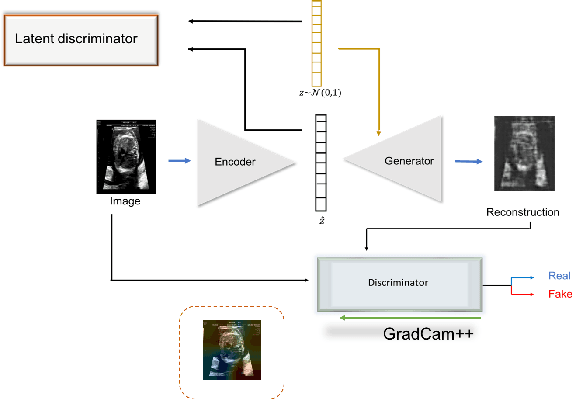
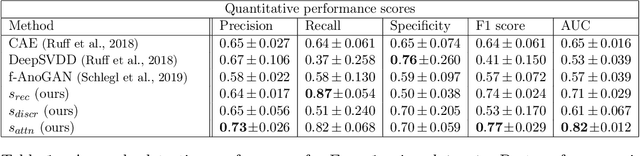
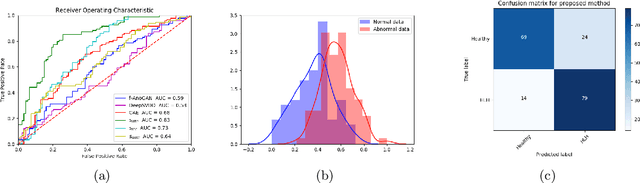
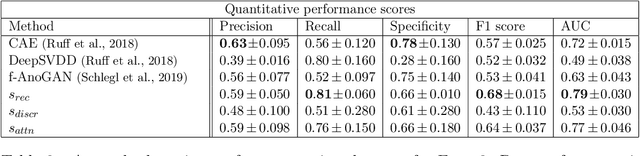
Congenital heart disease is considered as one the most common groups of congenital malformations which affects $6-11$ per $1000$ newborns. In this work, an automated framework for detection of cardiac anomalies during ultrasound screening is proposed and evaluated on the example of Hypoplastic Left Heart Syndrome (HLHS), a sub-category of congenital heart disease. We propose an unsupervised approach that learns healthy anatomy exclusively from clinically confirmed normal control patients. We evaluate a number of known anomaly detection frameworks together with a new model architecture based on the $\alpha$-GAN network and find evidence that the proposed model performs significantly better than the state-of-the-art in image-based anomaly detection, yielding average $0.81$ AUC \emph{and} a better robustness towards initialisation compared to previous works.
Learning Invariances in Neural Networks
Oct 22, 2020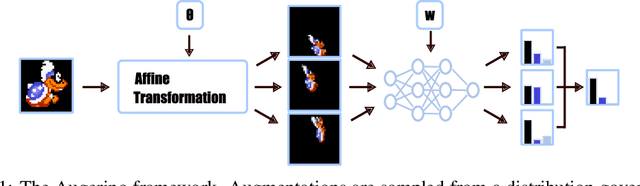

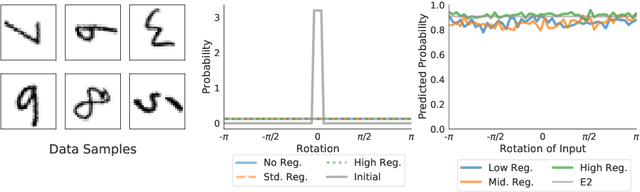

Invariances to translations have imbued convolutional neural networks with powerful generalization properties. However, we often do not know a priori what invariances are present in the data, or to what extent a model should be invariant to a given symmetry group. We show how to \emph{learn} invariances and equivariances by parameterizing a distribution over augmentations and optimizing the training loss simultaneously with respect to the network parameters and augmentation parameters. With this simple procedure we can recover the correct set and extent of invariances on image classification, regression, segmentation, and molecular property prediction from a large space of augmentations, on training data alone.
Bridging the gap between Natural and Medical Images through Deep Colorization
May 21, 2020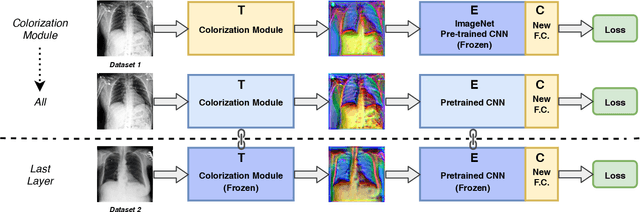
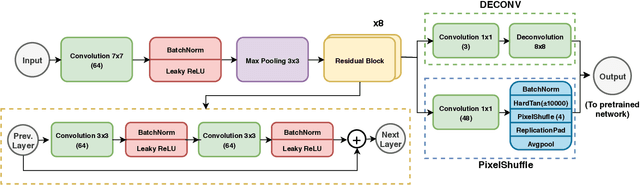
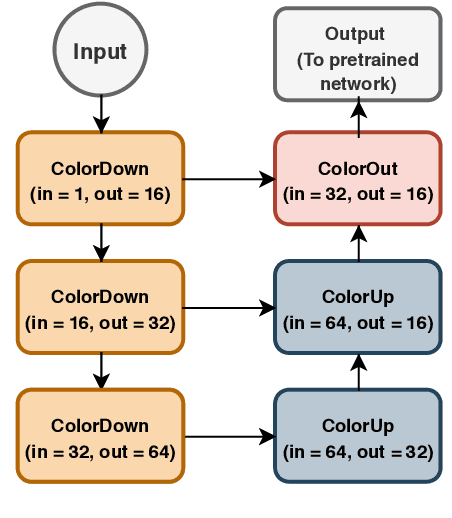
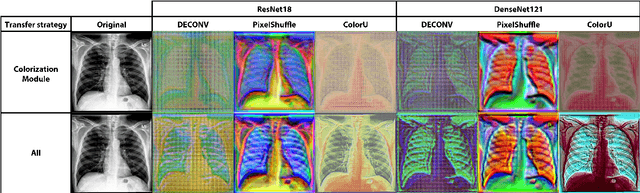
Deep learning has thrived by training on large-scale datasets. However, in many applications, as for medical image diagnosis, getting massive amount of data is still prohibitive due to privacy, lack of acquisition homogeneity and annotation cost. In this scenario, transfer learning from natural image collections is a standard practice that attempts to tackle shape, texture and color discrepancies all at once through pretrained model fine-tuning. In this work, we propose to disentangle those challenges and design a dedicated network module that focuses on color adaptation. We combine learning from scratch of the color module with transfer learning of different classification backbones, obtaining an end-to-end, easy-to-train architecture for diagnostic image recognition on X-ray images. Extensive experiments showed how our approach is particularly efficient in case of data scarcity and provides a new path for further transferring the learned color information across multiple medical datasets.
Image Classification with Rejection using Contextual Information
Sep 03, 2015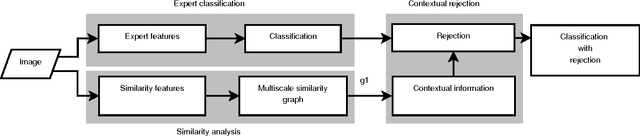
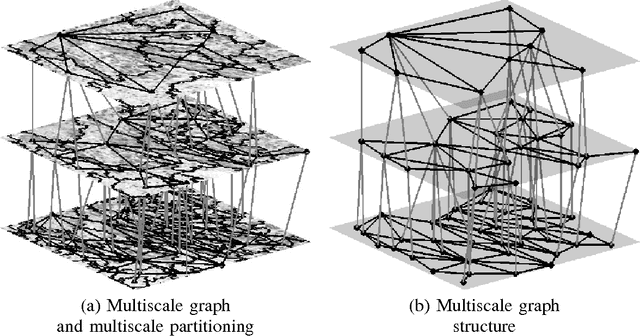
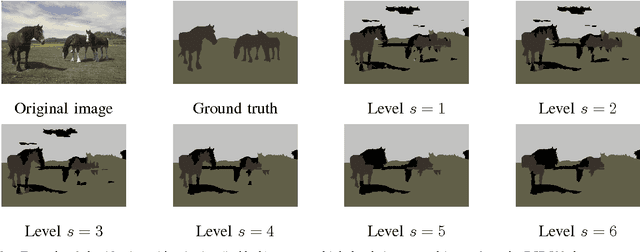
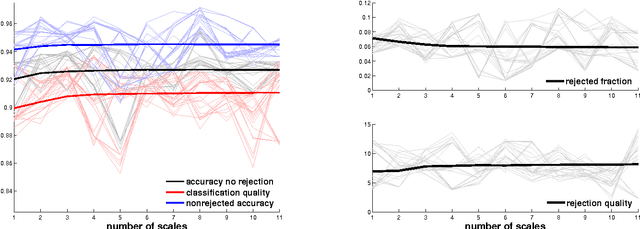
We introduce a new supervised algorithm for image classification with rejection using multiscale contextual information. Rejection is desired in image-classification applications that require a robust classifier but not the classification of the entire image. The proposed algorithm combines local and multiscale contextual information with rejection, improving the classification performance. As a probabilistic model for classification, we adopt a multinomial logistic regression. The concept of rejection with contextual information is implemented by modeling the classification problem as an energy minimization problem over a graph representing local and multiscale similarities of the image. The rejection is introduced through an energy data term associated with the classification risk and the contextual information through an energy smoothness term associated with the local and multiscale similarities within the image. We illustrate the proposed method on the classification of images of H&E-stained teratoma tissues.
AMC: Attention guided Multi-modal Correlation Learning for Image Search
Apr 03, 2017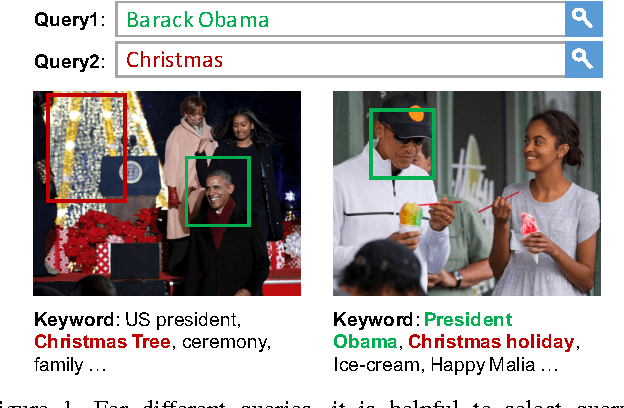

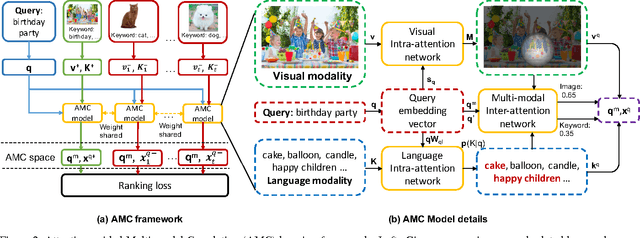
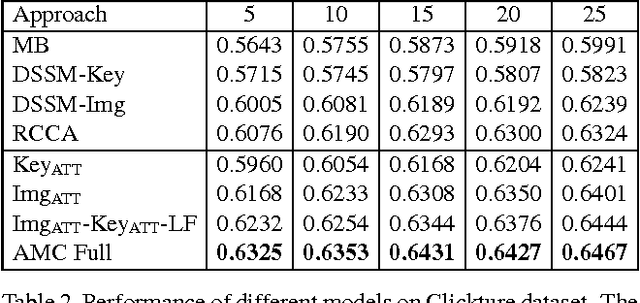
Given a user's query, traditional image search systems rank images according to its relevance to a single modality (e.g., image content or surrounding text). Nowadays, an increasing number of images on the Internet are available with associated meta data in rich modalities (e.g., titles, keywords, tags, etc.), which can be exploited for better similarity measure with queries. In this paper, we leverage visual and textual modalities for image search by learning their correlation with input query. According to the intent of query, attention mechanism can be introduced to adaptively balance the importance of different modalities. We propose a novel Attention guided Multi-modal Correlation (AMC) learning method which consists of a jointly learned hierarchy of intra and inter-attention networks. Conditioned on query's intent, intra-attention networks (i.e., visual intra-attention network and language intra-attention network) attend on informative parts within each modality; a multi-modal inter-attention network promotes the importance of the most query-relevant modalities. In experiments, we evaluate AMC models on the search logs from two real world image search engines and show a significant boost on the ranking of user-clicked images in search results. Additionally, we extend AMC models to caption ranking task on COCO dataset and achieve competitive results compared with recent state-of-the-arts.
MeDaS: An open-source platform as service to help break the walls between medicine and informatics
Jul 12, 2020


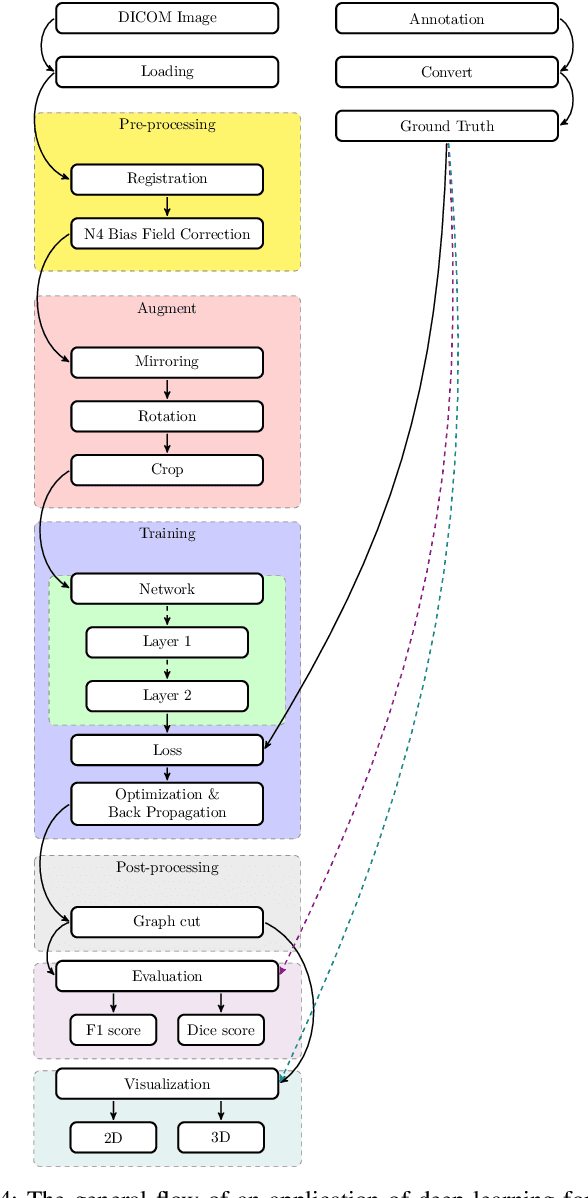
In the past decade, deep learning (DL) has achieved unprecedented success in numerous fields including computer vision, natural language processing, and healthcare. In particular, DL is experiencing an increasing development in applications for advanced medical image analysis in terms of analysis, segmentation, classification, and furthermore. On the one hand, tremendous needs that leverage the power of DL for medical image analysis are arising from the research community of a medical, clinical, and informatics background to jointly share their expertise, knowledge, skills, and experience. On the other hand, barriers between disciplines are on the road for them often hampering a full and efficient collaboration. To this end, we propose our novel open-source platform, i.e., MeDaS -- the MeDical open-source platform as Service. To the best of our knowledge, MeDaS is the first open-source platform proving a collaborative and interactive service for researchers from a medical background easily using DL related toolkits, and at the same time for scientists or engineers from information sciences to understand the medical knowledge side. Based on a series of toolkits and utilities from the idea of RINV (Rapid Implementation aNd Verification), our proposed MeDaS platform can implement pre-processing, post-processing, augmentation, visualization, and other phases needed in medical image analysis. Five tasks including the subjects of lung, liver, brain, chest, and pathology, are validated and demonstrated to be efficiently realisable by using MeDaS.