 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CurlingNet: Compositional Learning between Images and Text for Fashion IQ Data
Mar 30, 2020
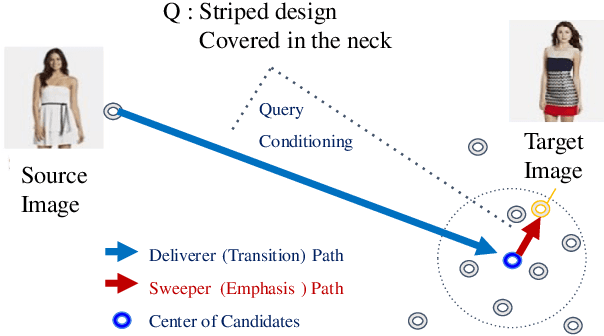
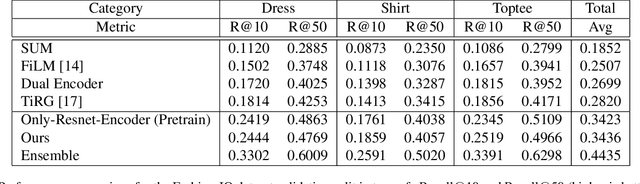
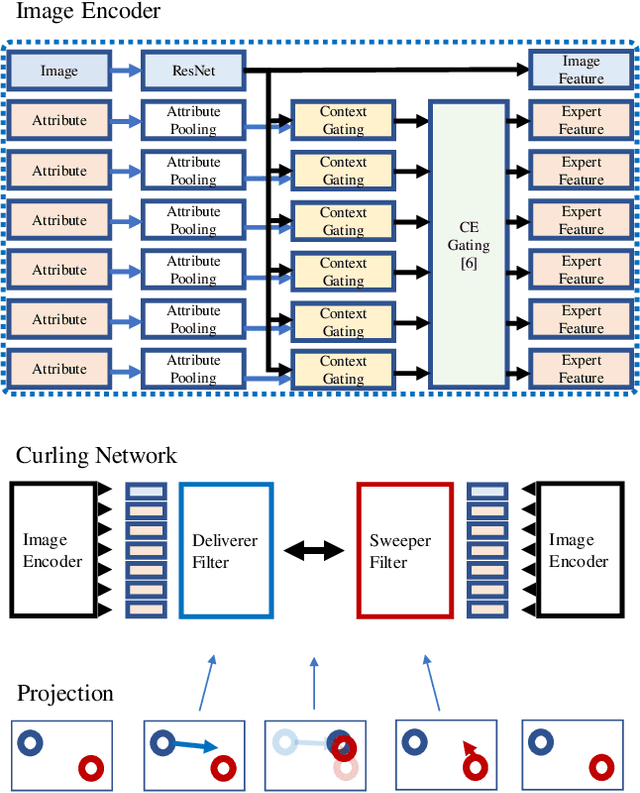
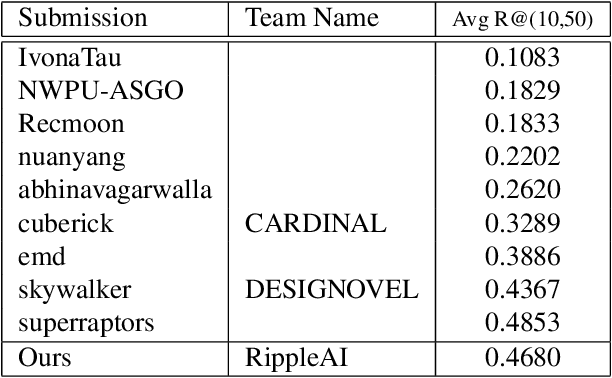
We present an approach named CurlingNet that can measure the semantic distance of composition of image-text embedding. In order to learn an effective image-text composition for the data in the fashion domain, our model proposes two key components as follows. First, the Delivery makes the transition of a source image in an embedding space. Second, the Sweeping emphasizes query-related components of fashion images in the embedding space. We utilize a channel-wise gating mechanism to make it possible. Our single model outperforms previous state-of-the-art image-text composition models including TIRG and FiLM. We participate in the first fashion-IQ challenge in ICCV 2019, for which ensemble of our model achieves one of the best performances.
Semi-supervised few-shot learning for medical image segmentation
Apr 09, 2020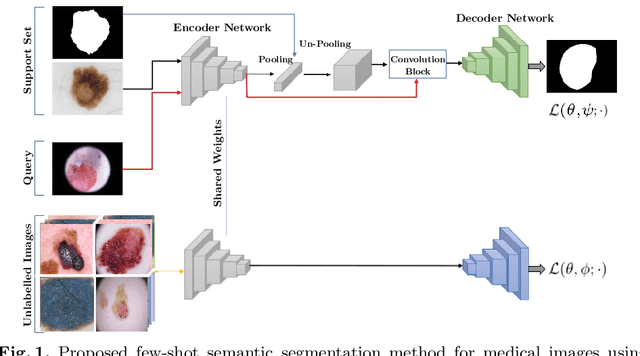
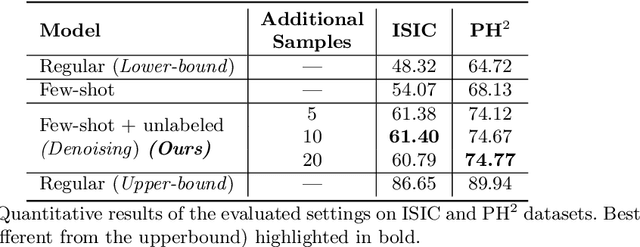


Recent years have witnessed the great progress of deep neural networks on semantic segmentation, particularly in medical imaging. Nevertheless, training high-performing models require large amounts of pixel-level ground truth masks, which can be prohibitive to obtain in the medical domain. Furthermore, training such models in a low-data regime highly increases the risk of overfitting. Recent attempts to alleviate the need for large annotated datasets have developed training strategies under the few-shot learning paradigm, which addresses this shortcoming by learning a novel class from only a few labeled examples. In this context, a segmentation model is trained on episodes, which represent different segmentation problems, each of them trained with a very small labeled dataset. In this work, we propose a novel few-shot learning framework for semantic segmentation, where unlabeled images are also made available at each episode. To handle this new learning paradigm, we propose to include surrogate tasks that can leverage very powerful supervisory signals --derived from the data itself-- for semantic feature learning. We show that including unlabeled surrogate tasks in the episodic training leads to more powerful feature representations, which ultimately results in better generability to unseen tasks. We demonstrate the efficiency of our method in the task of skin lesion segmentation in two publicly available datasets. Furthermore, our approach is general and model-agnostic, which can be combined with different deep architectures.
Anatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 12, 2020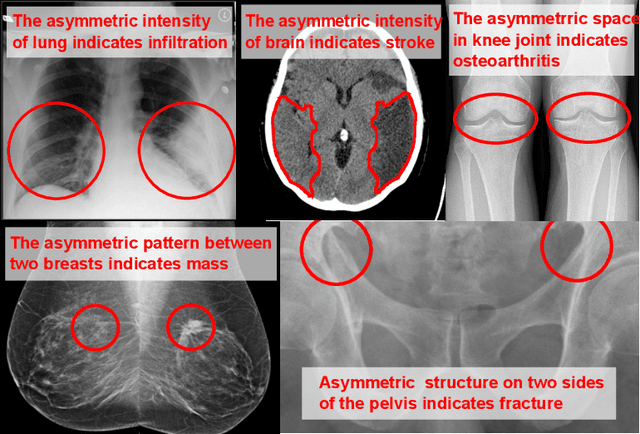
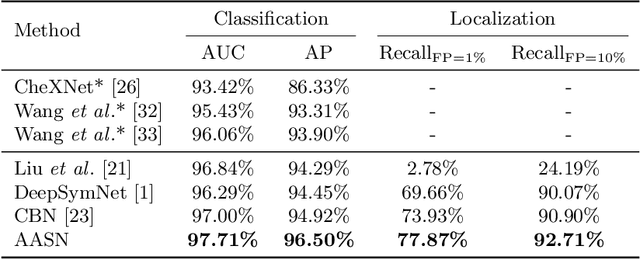
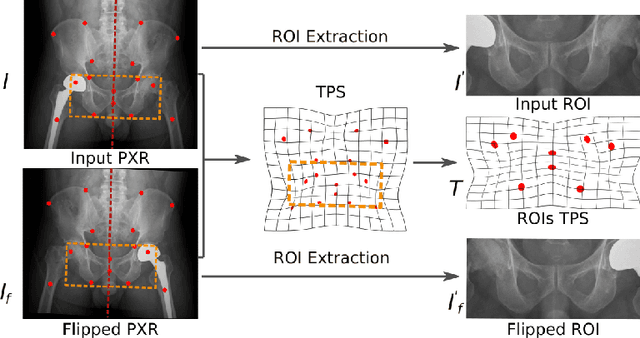
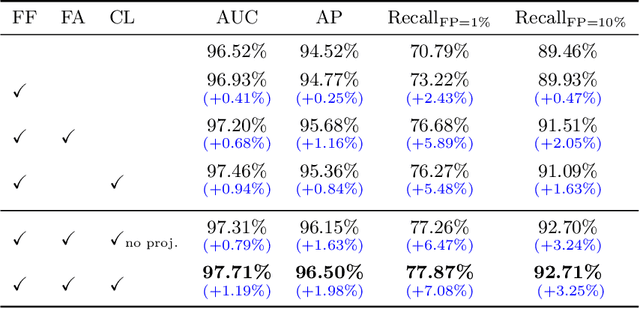
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.
One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
Nov 30, 2020
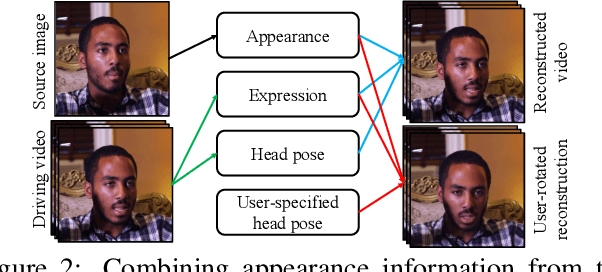

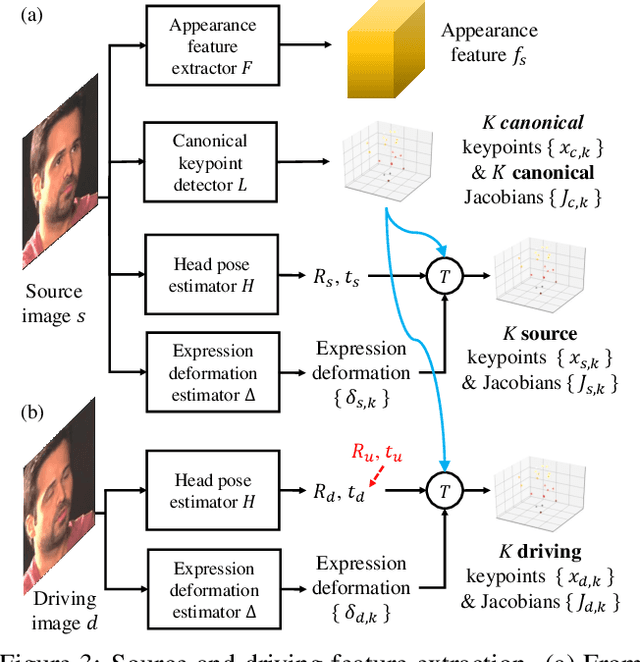
We propose a neural talking-head video synthesis model and demonstrate its application to video conferencing. Our model learns to synthesize a talking-head video using a source image containing the target person's appearance and a driving video that dictates the motion in the output. Our motion is encoded based on a novel keypoint representation, where the identity-specific and motion-related information is decomposed unsupervisedly. Extensive experimental validation shows that our model outperforms competing methods on benchmark datasets. Moreover, our compact keypoint representation enables a video conferencing system that achieves the same visual quality as the commercial H.264 standard while only using one-tenth of the bandwidth. Besides, we show our keypoint representation allows the user to rotate the head during synthesis, which is useful for simulating a face-to-face video conferencing experience.
VAEBM: A Symbiosis between Variational Autoencoders and Energy-based Models
Oct 01, 2020
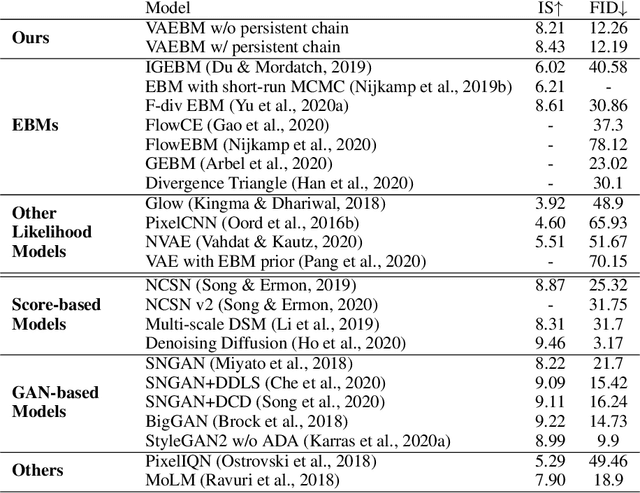


Energy-based models (EBMs) have recently been successful in representing complex distributions of small images. However, sampling from them requires expensive Markov chain Monte Carlo (MCMC) iterations that mix slowly in high dimensional pixel space. Unlike EBMs, variational autoencoders (VAEs) generate samples quickly and are equipped with a latent space that enables fast traversal of the data manifold. However, VAEs tend to assign high probability density to regions in data space outside the actual data distribution and often fail at generating sharp images. In this paper, we propose VAEBM, a symbiotic composition of a VAE and an EBM that offers the best of both worlds. VAEBM captures the overall mode structure of the data distribution using a state-of-the-art VAE and it relies on its EBM component to explicitly exclude non-data-like regions from the model and refine the image samples. Moreover, the VAE component in VAEBM allows us to speed up MCMC updates by reparameterizing them in the VAE's latent space. Our experimental results show that VAEBM outperforms state-of-the-art VAEs and EBMs in generative quality on several benchmark image datasets by a large margin. It can generate high-quality images as large as 256$\times$256 pixels with short MCMC chains. We also demonstrate that VAEBM provides complete mode coverage and performs well in out-of-distribution detection.
Rethinking movie genre classification with fine-grained semantic clustering
Dec 07, 2020
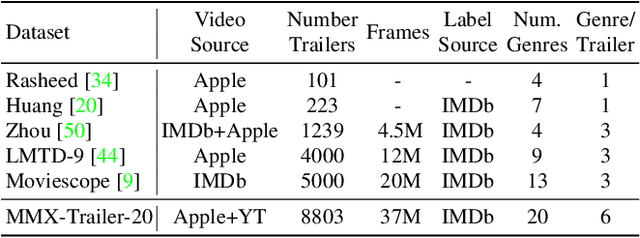
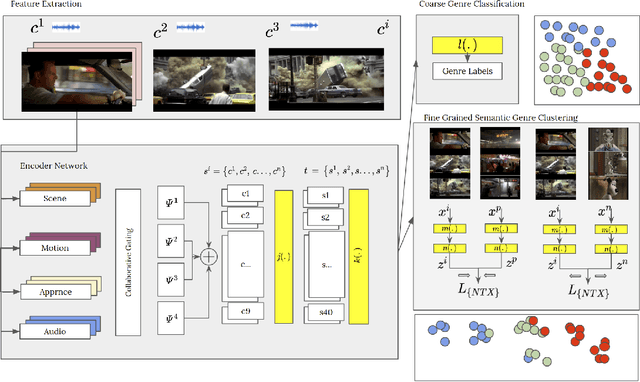
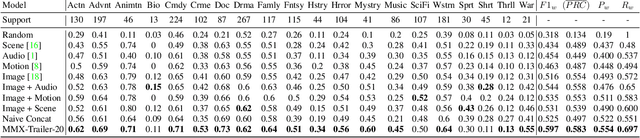
Movie genre classification is an active research area in machine learning. However, due to the limited labels available, there can be large semantic variations between movies within a single genre definition. We expand these 'coarse' genre labels by identifying 'fine-grained' semantic information within the multi-modal content of movies. By leveraging pre-trained 'expert' networks, we learn the influence of different combinations of modes for multi-label genre classification. Using a contrastive loss, we continue to fine-tune this 'coarse' genre classification network to identify high-level intertextual similarities between the movies across all genre labels. This leads to a more 'fine-grained' and detailed clustering, based on semantic similarities while still retaining some genre information. Our approach is demonstrated on a newly introduced multi-modal 37,866,450 frame, 8,800 movie trailer dataset, MMX-Trailer-20, which includes pre-computed audio, location, motion, and image embeddings.
MirrorNet: Bio-Inspired Adversarial Attack for Camouflaged Object Segmentation
Jul 25, 2020
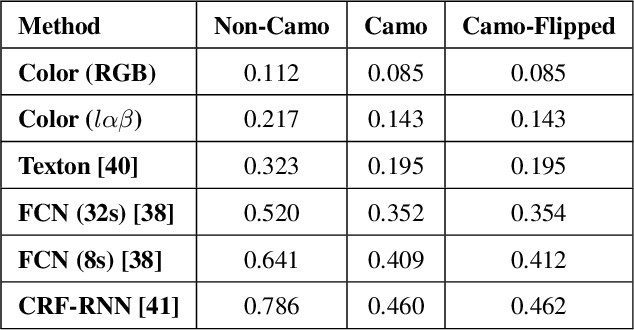

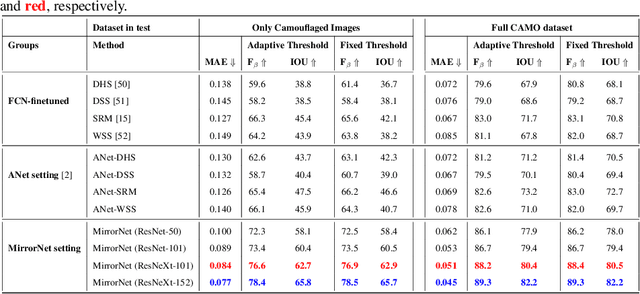
Camouflaged objects are generally difficult to be detected in their natural environment even for human beings. In this paper, we propose a novel bio-inspired network, named the MirrorNet, that leverages both instance segmentation and adversarial attack for the camouflaged object segmentation. Differently from existing networks for segmentation, our proposed network possesses two segmentation streams: the main stream and the adversarial stream corresponding with the original image and its flipped image, respectively. The output from the adversarial stream is then fused into the main stream's result for the final camouflage map to boost up the segmentation accuracy. Extensive experiments conducted on the public CAMO dataset demonstrate the effectiveness of our proposed network. Our proposed method achieves 89% in accuracy, outperforming the state-of-the-arts. Project Page: https://sites.google.com/view/ltnghia/research/camo
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

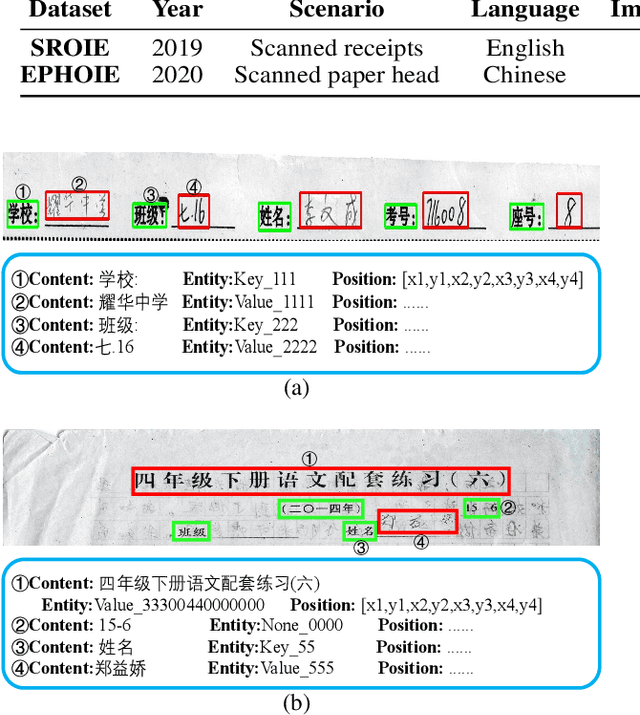
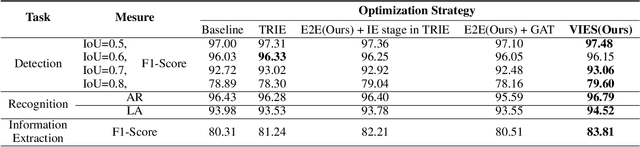
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
Scale-covariant and scale-invariant Gaussian derivative networks
Nov 30, 2020

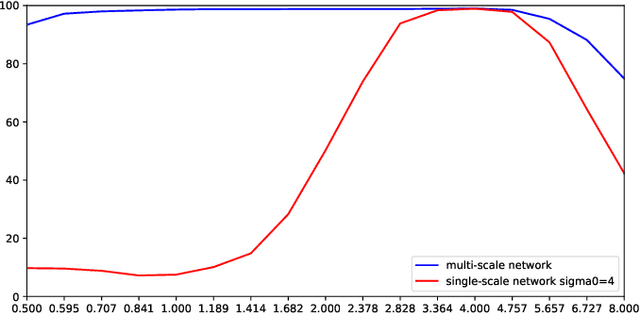
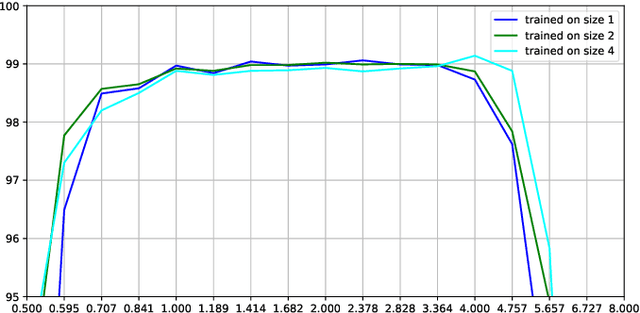
This article presents a hybrid approach between scale-space theory and deep learning, where a deep learning architecture is constructed by coupling parameterized scale-space operations in cascade. By sharing the learnt parameters between multiple scale channels, and by using the transformation properties of the scale-space primitives under scaling transformations, the resulting network becomes provably scale covariant. By in addition performing max pooling over the multiple scale channels, a resulting network architecture for image classification also becomes provably scale invariant. We investigate the performance of such networks on the MNISTLargeScale dataset, which contains rescaled images from original MNIST over a factor 4 concerning training data and over a factor of 16 concerning testing data. It is demonstrated that the resulting approach allows for scale generalization, enabling good performance for classifying patterns at scales not present in the training data.
Multi-Label Image Classification with Regional Latent Semantic Dependencies
Mar 12, 2017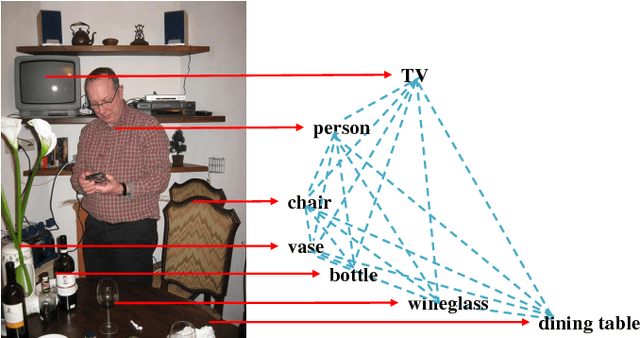
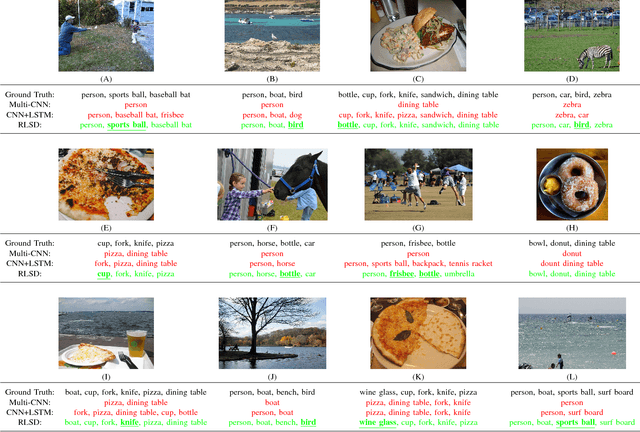

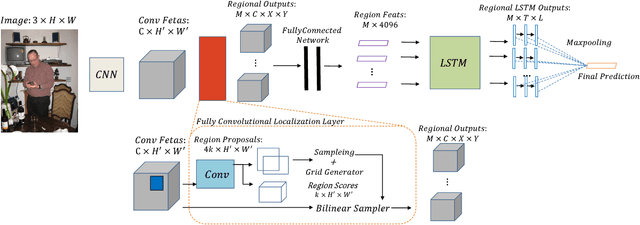
Deep convolution neural networks (CNN) have demonstrated advanced performance on single-label image classification, and various progress also have been made to apply CNN methods on multi-label image classification, which requires to annotate objects, attributes, scene categories etc. in a single shot. Recent state-of-the-art approaches to multi-label image classification exploit the label dependencies in an image, at global level, largely improving the labeling capacity. However, predicting small objects and visual concepts is still challenging due to the limited discrimination of the global visual features. In this paper, we propose a Regional Latent Semantic Dependencies model (RLSD) to address this problem. The utilized model includes a fully convolutional localization architecture to localize the regions that may contain multiple highly-dependent labels. The localized regions are further sent to the recurrent neural networks (RNN) to characterize the latent semantic dependencies at the regional level. Experimental results on several benchmark datasets show that our proposed model achieves the best performance compared to the state-of-the-art models, especially for predicting small objects occurred in the images. In addition, we set up an upper bound model (RLSD+ft-RPN) using bounding box coordinates during training, the experimental results also show that our RLSD can approach the upper bound without using the bounding-box annotations, which is more realistic in the real world.