 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised few-shot learning for medical image segmentation
Apr 09, 2020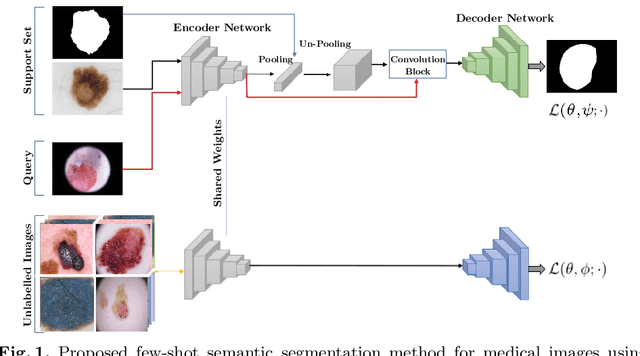
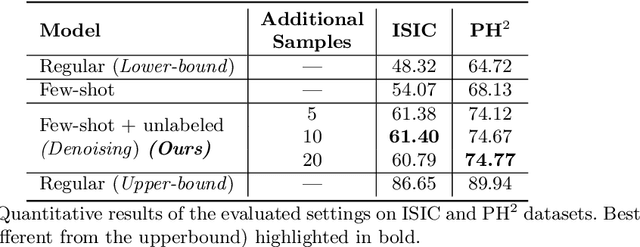


Recent years have witnessed the great progress of deep neural networks on semantic segmentation, particularly in medical imaging. Nevertheless, training high-performing models require large amounts of pixel-level ground truth masks, which can be prohibitive to obtain in the medical domain. Furthermore, training such models in a low-data regime highly increases the risk of overfitting. Recent attempts to alleviate the need for large annotated datasets have developed training strategies under the few-shot learning paradigm, which addresses this shortcoming by learning a novel class from only a few labeled examples. In this context, a segmentation model is trained on episodes, which represent different segmentation problems, each of them trained with a very small labeled dataset. In this work, we propose a novel few-shot learning framework for semantic segmentation, where unlabeled images are also made available at each episode. To handle this new learning paradigm, we propose to include surrogate tasks that can leverage very powerful supervisory signals --derived from the data itself-- for semantic feature learning. We show that including unlabeled surrogate tasks in the episodic training leads to more powerful feature representations, which ultimately results in better generability to unseen tasks. We demonstrate the efficiency of our method in the task of skin lesion segmentation in two publicly available datasets. Furthermore, our approach is general and model-agnostic, which can be combined with different deep architectures.
On the Texture Bias for Few-Shot CNN Segmentation
Mar 09, 2020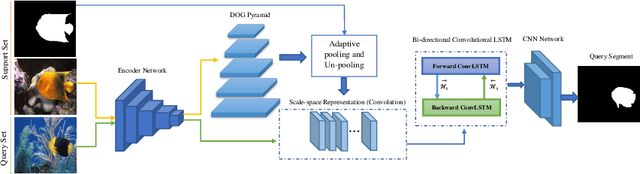


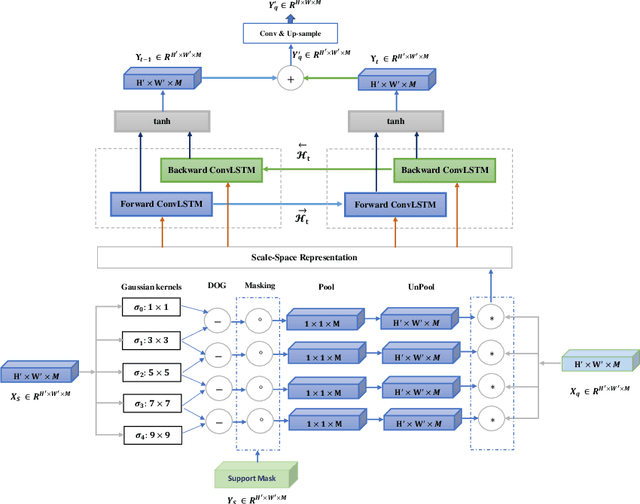
Despite the initial belief that Convolutional Neural Networks (CNNs) are driven by shapes to perform visual recognition tasks, recent evidence suggests that texture bias in CNNs provides higher performing and more robust models. This contrasts with the perceptual bias in the human visual cortex, which has a stronger preference towards shape components. Perceptual differences may explain why CNNs achieve human-level performance when large labeled datasets are available, but their performance significantly degrades in low-labeled data scenarios, such as few-shot semantic segmentation. To remove the texture bias in the context of few-shot learning, we propose a novel architecture that integrates a set of difference of Gaussians (DoG) to attenuate high-frequency local components in the feature space. This produces a set of modified feature maps, whose high-frequency components are diminished at different standard deviation values of the Gaussian distribution in the spatial domain. As this results in multiple feature maps for a single image, we employ a bi-directional convolutional long-short-term-memory to efficiently merge the multi scale-space representations. We perform extensive experiments on two well-known few-shot segmentation benchmarks -Pascal i5 and FSS-1000- and demonstrate that our method outperforms significantly state-of-the-art approaches. The code is available at: https://github.com/rezazad68/fewshot-segmentation