 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Radar Artifact Labeling Framework (RALF): Method for Plausible Radar Detections in Datasets
Dec 03, 2020
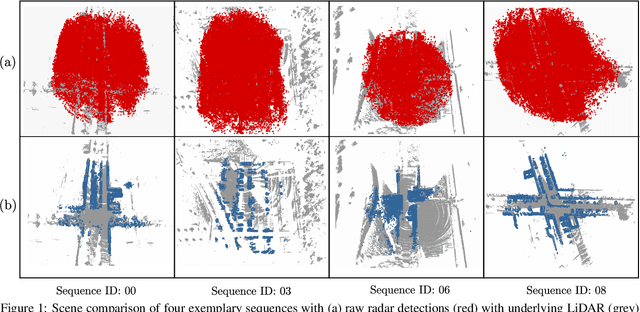
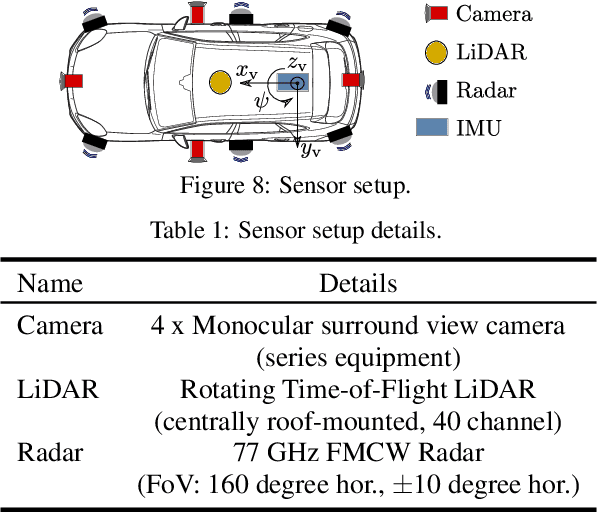
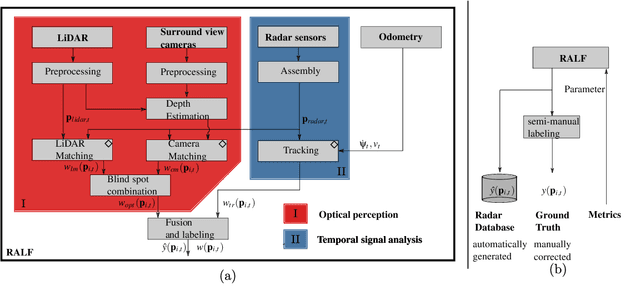
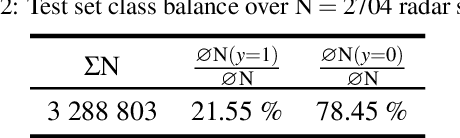
Research on localization and perception for Autonomous Driving is mainly focused on camera and LiDAR datasets, rarely on radar data. Manually labeling sparse radar point clouds is challenging. For a dataset generation, we propose the cross sensor Radar Artifact Labeling Framework (RALF). Automatically generated labels for automotive radar data help to cure radar shortcomings like artifacts for the application of artificial intelligence. RALF provides plausibility labels for radar raw detections, distinguishing between artifacts and targets. The optical evaluation backbone consists of a generalized monocular depth image estimation of surround view cameras plus LiDAR scans. Modern car sensor sets of cameras and LiDAR allow to calibrate image-based relative depth information in overlapping sensing areas. K-Nearest Neighbors matching relates the optical perception point cloud with raw radar detections. In parallel, a temporal tracking evaluation part considers the radar detections' transient behavior. Based on the distance between matches, respecting both sensor and model uncertainties, we propose a plausibility rating of every radar detection. We validate the results by evaluating error metrics on semi-manually labeled ground truth dataset of $3.28\cdot10^6$ points. Besides generating plausible radar detections, the framework enables further labeled low-level radar signal datasets for applications of perception and Autonomous Driving learning tasks.
Training Generative Adversarial Networks in One Stage
Feb 28, 2021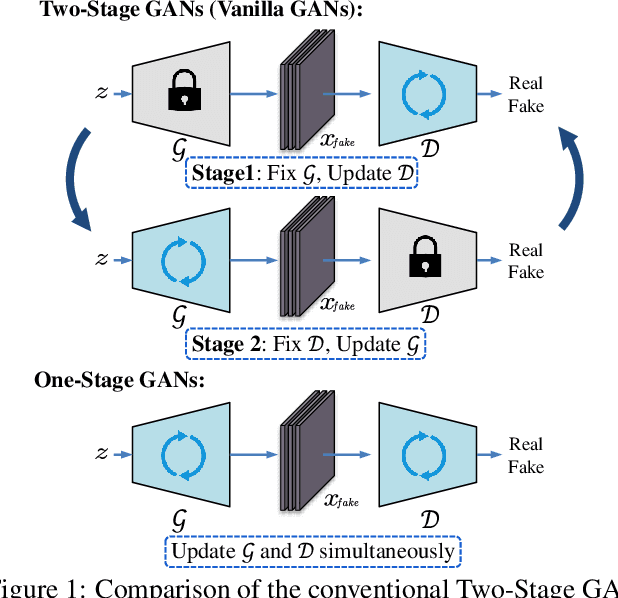
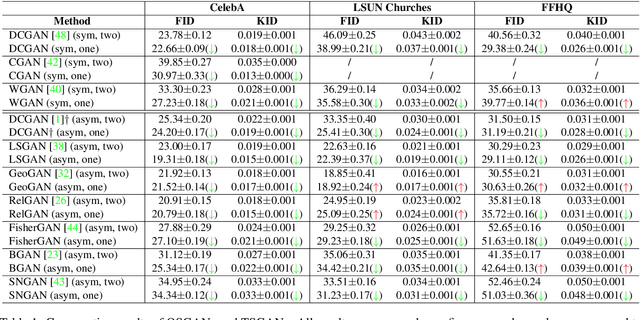
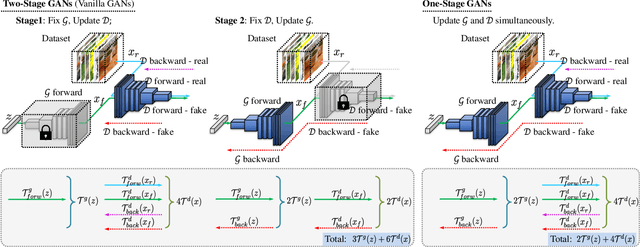
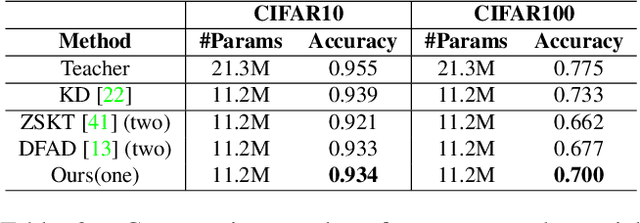
Generative Adversarial Networks (GANs) have demonstrated unprecedented success in various image generation tasks. The encouraging results, however, come at the price of a cumbersome training process, during which the generator and discriminator are alternately updated in two stages. In this paper, we investigate a general training scheme that enables training GANs efficiently in only one stage. Based on the adversarial losses of the generator and discriminator, we categorize GANs into two classes, Symmetric GANs and Asymmetric GANs, and introduce a novel gradient decomposition method to unify the two, allowing us to train both classes in one stage and hence alleviate the training effort. Computational analysis and experimental results on several datasets and various network architectures demonstrate that, the proposed one-stage training scheme yields a solid 1.5$\times$ acceleration over conventional training schemes, regardless of the network architectures of the generator and discriminator. Furthermore, we show that the proposed method is readily applicable to other adversarial-training scenarios, such as data-free knowledge distillation. Our source code will be published soon.
Co-mining: Self-Supervised Learning for Sparsely Annotated Object Detection
Dec 03, 2020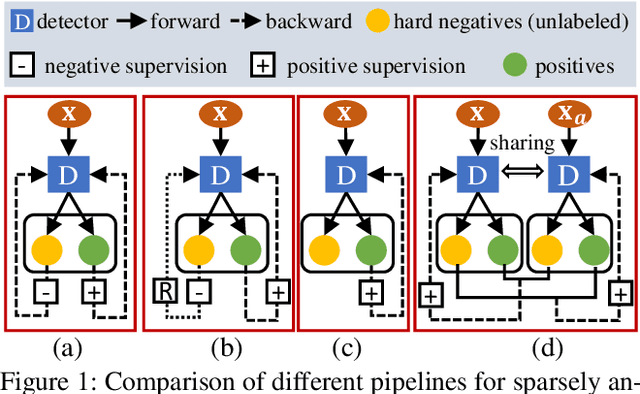

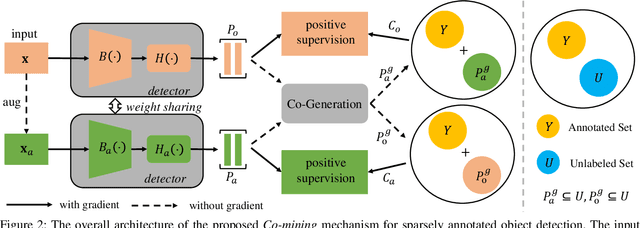

Object detectors usually achieve promising results with the supervision of complete instance annotations. However, their performance is far from satisfactory with sparse instance annotations. Most existing methods for sparsely annotated object detection either re-weight the loss of hard negative samples or convert the unlabeled instances into ignored regions to reduce the interference of false negatives. We argue that these strategies are insufficient since they can at most alleviate the negative effect caused by missing annotations. In this paper, we propose a simple but effective mechanism, called Co-mining, for sparsely annotated object detection. In our Co-mining, two branches of a Siamese network predict the pseudo-label sets for each other. To enhance multi-view learning and better mine unlabeled instances, the original image and corresponding augmented image are used as the inputs of two branches of the Siamese network, respectively. Co-mining can serve as a general training mechanism applied to most of modern object detectors. Experiments are performed on MS COCO dataset with three different sparsely annotated settings using two typical frameworks: anchor-based detector RetinaNet and anchor-free detector FCOS. Experimental results show that our Co-mining with RetinaNet achieves 1.4%~2.1% improvements compared with different baselines and surpasses existing methods under the same sparsely annotated setting.
Probabilistic Image Colorization
May 11, 2017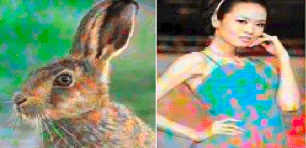
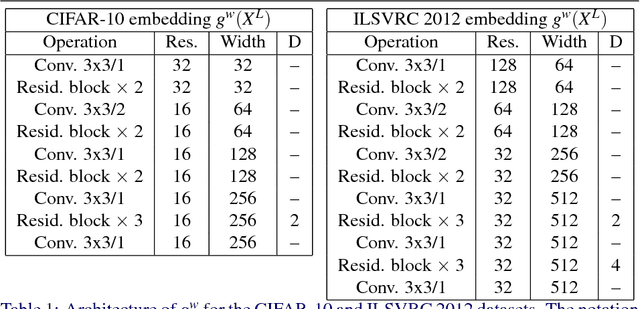
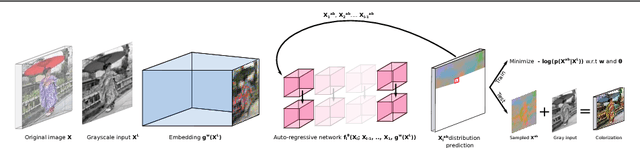

We develop a probabilistic technique for colorizing grayscale natural images. In light of the intrinsic uncertainty of this task, the proposed probabilistic framework has numerous desirable properties. In particular, our model is able to produce multiple plausible and vivid colorizations for a given grayscale image and is one of the first colorization models to provide a proper stochastic sampling scheme. Moreover, our training procedure is supported by a rigorous theoretical framework that does not require any ad hoc heuristics and allows for efficient modeling and learning of the joint pixel color distribution. We demonstrate strong quantitative and qualitative experimental results on the CIFAR-10 dataset and the challenging ILSVRC 2012 dataset.
Branched Generative Adversarial Networks for Multi-Scale Image Manifold Learning
Mar 22, 2018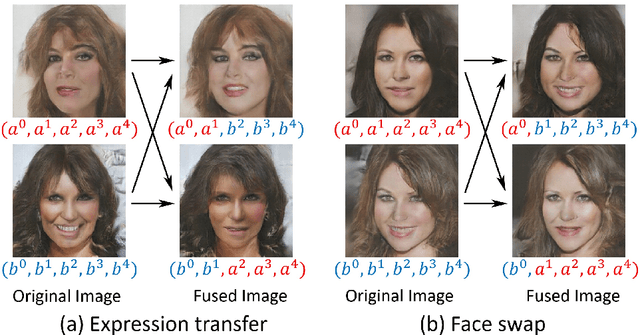
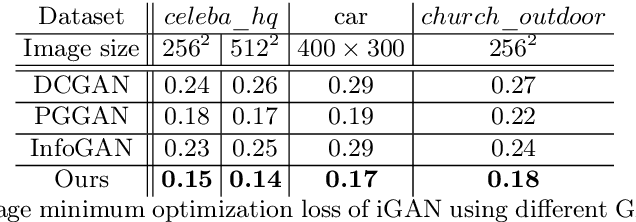
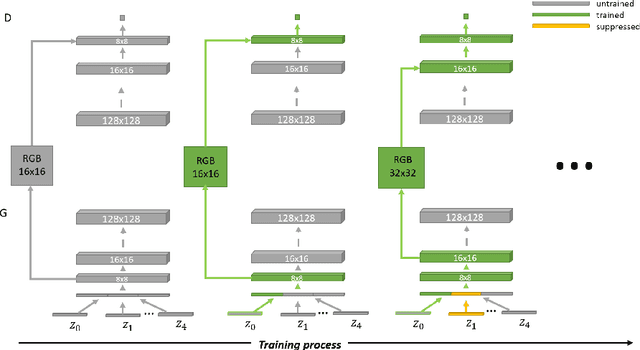
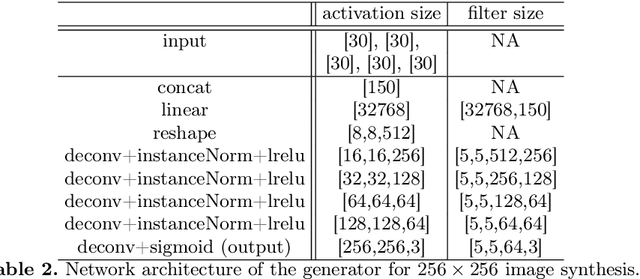
We introduce BranchGAN, a novel training method that enables unconditioned generative adversarial networks (GANs) to learn image manifolds at multiple scales. What is unique about BranchGAN is that it is trained in multiple branches, progressively covering both the breadth and depth of the network, as resolutions of the training images increase to reveal finer-scale features. Specifically, each noise vector, as input to the generator network, is explicitly split into several sub-vectors, each corresponding to and trained to learn image representations at a particular scale. During training, we progressively "de-freeze" the sub-vectors, one at a time, as a new set of higher-resolution images is employed for training and more network layers are added. A consequence of such an explicit sub-vector designation is that we can directly manipulate and even combine latent (sub-vector) codes that are associated with specific feature scales. Experiments demonstrate the effectiveness of our training method in multi-scale, disentangled learning of image manifolds and synthesis, without any extra labels and without compromising quality of the synthesized high-resolution images. We further demonstrate two new applications enabled by BranchGAN.
Model-based Reconstruction for Single Particle Cryo-Electron Microscopy
Mar 19, 2021
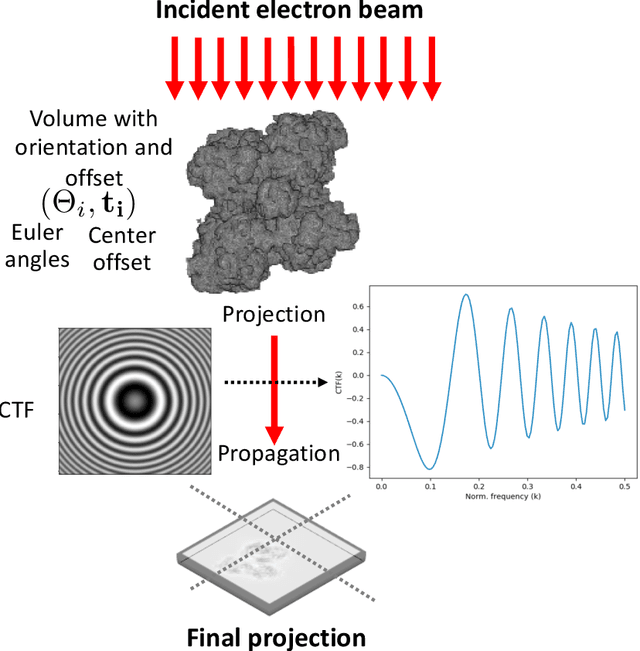

Single particle cryo-electron microscopy is a vital tool for 3D characterization of protein structures. A typical workflow involves acquiring projection images of a collection of randomly oriented particles, picking and classifying individual particle projections by orientation, and finally using the individual particle projections to reconstruct a 3D map of the electron density profile. The reconstruction is challenging because of the low signal-to-noise ratio of the data, the unknown orientation of the particles, and the sparsity of data especially when dealing with flexible proteins where there may not be sufficient data corresponding to each class to obtain an accurate reconstruction using standard algorithms. In this paper we present a model-based image reconstruction technique that uses a regularized cost function to reconstruct the 3D density map by assuming known orientations for the particles. Our method casts the reconstruction as minimizing a cost function involving a novel forward model term that accounts for the contrast transfer function of the microscope, the orientation of the particles and the center of rotation offsets. We combine the forward model term with a regularizer that enforces desirable properties in the volume to be reconstructed. Using simulated data, we demonstrate how our method can significantly improve upon the typically used approach.
Model-based Reconstruction for Enhanced X-ray CT of Tri-structural Isotropic (TRISO) Particles
Mar 19, 2021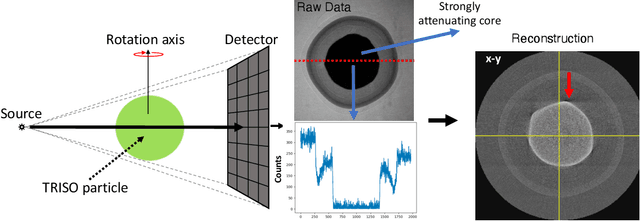
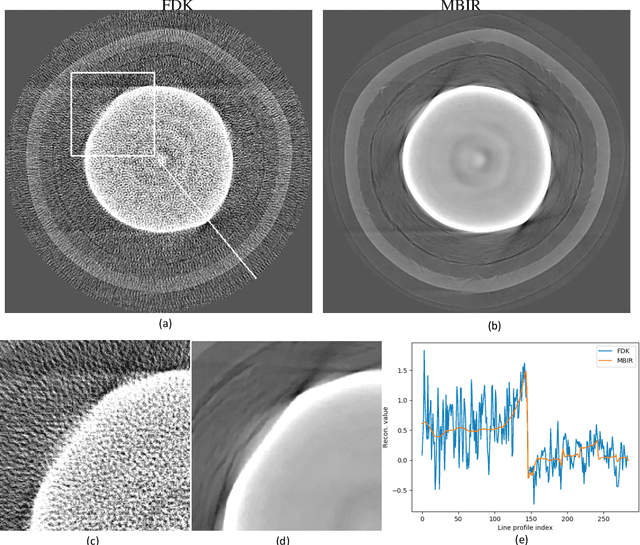
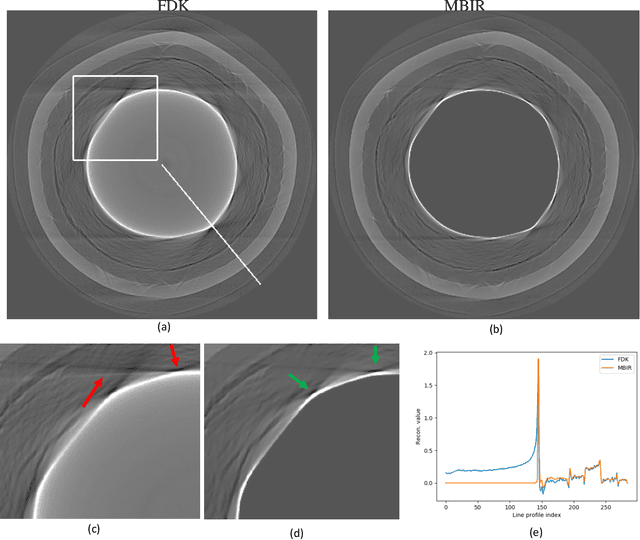

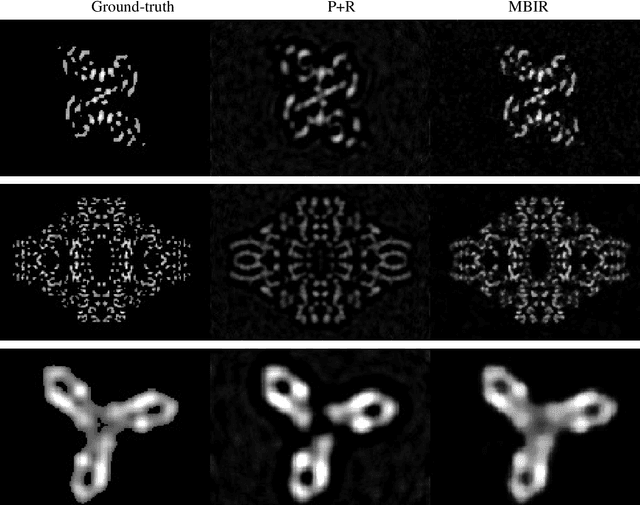
Tri-Structural Isotropic (TRISO) fuel particles are a key component of next generation nuclear fuels. Using X-ray computed tomography (CT) to characterize TRISO particles is challenging because of the strong attenuation of the X-ray beam by the uranium core leading to severe photon starvation in a substantial fraction of the measurements. Furthermore, the overall acquisition time for a high-resolution CT scan can be very long when using conventional lab-based X-ray systems and reconstruction algorithms. Specifically, when analytic methods like the Feldkamp-Davis-Kress (FDK) algorithm is used for reconstruction, it results in severe streaks artifacts and noise in the corresponding 3D volume which make subsequent analysis of the particles challenging. In this article, we develop and apply model-based image reconstruction (MBIR) algorithms for improving the quality of CT reconstructions for TRISO particles in order to facilitate better characterization. We demonstrate that the proposed MBIR algorithms can significantly suppress artifacts with minimal pre-processing compared to the conventional approaches. Furthermore, we demonstrate the proposed MBIR approach can obtain high-quality reconstruction compared to the FDK approach even when using a fraction of the typically acquired measurements, thereby enabling dramatically faster measurement times for TRISO particles.
Bilateral Asymmetry Guided Counterfactual Generating Network for Mammogram Classification
Sep 30, 2020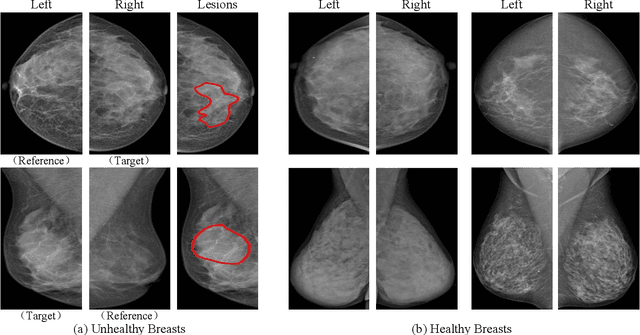
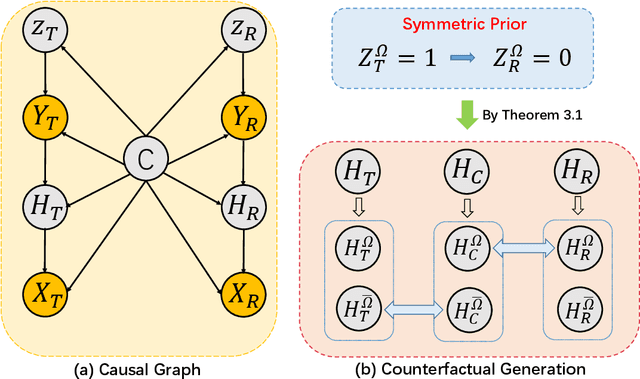
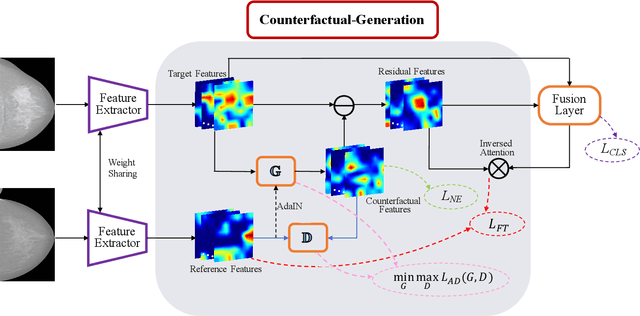
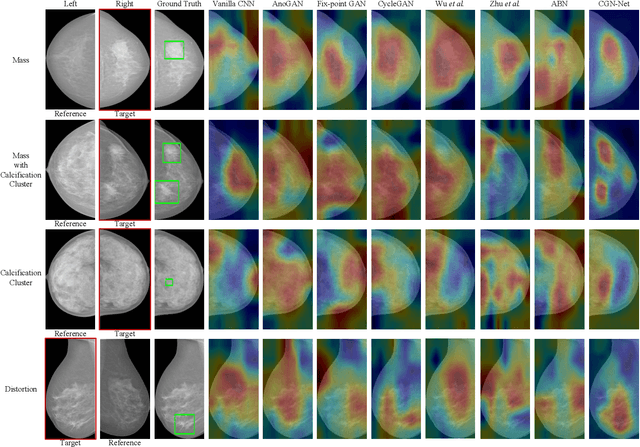
Mammogram benign or malignant classification with only image-level labels is challenging due to the absence of lesion annotations. Motivated by the symmetric prior that the lesions on one side of breasts rarely appear in the corresponding areas on the other side, given a diseased image, we can explore a counterfactual problem that how would the features have behaved if there were no lesions in the image, so as to identify the lesion areas. We derive a new theoretical result for counterfactual generation based on the symmetric prior. By building a causal model that entails such a prior for bilateral images, we obtain two optimization goals for counterfactual generation, which can be accomplished via our newly proposed counterfactual generative network. Our proposed model is mainly composed of Generator Adversarial Network and a \emph{prediction feedback mechanism}, they are optimized jointly and prompt each other. Specifically, the former can further improve the classification performance by generating counterfactual features to calculate lesion areas. On the other hand, the latter helps counterfactual generation by the supervision of classification loss. The utility of our method and the effectiveness of each module in our model can be verified by state-of-the-art performance on INBreast and an in-house dataset and ablation studies.
Multi-Scale Dense Networks for Resource Efficient Image Classification
Jun 07, 2018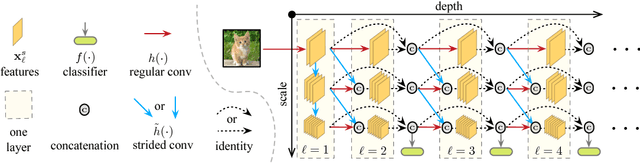
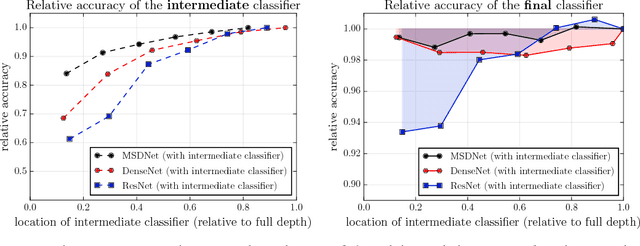

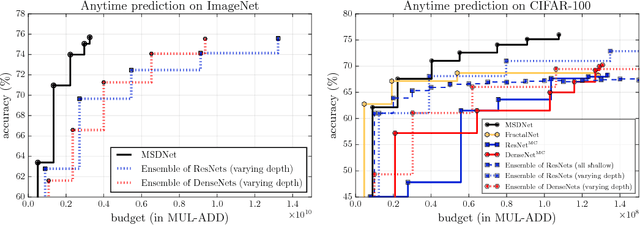
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network's prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across "easier" and "harder" inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.
AR Mapping: Accurate and Efficient Mapping for Augmented Reality
Mar 27, 2021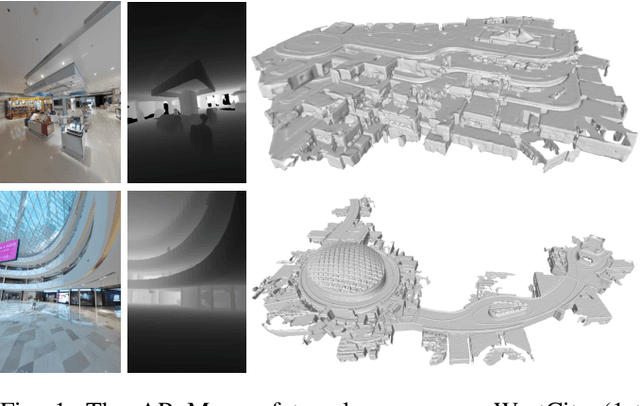

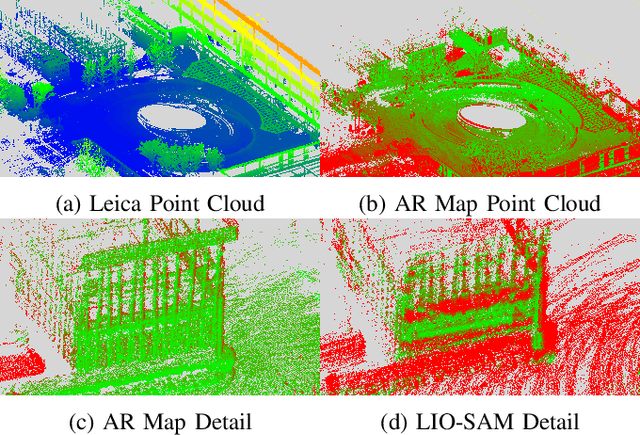

Augmented reality (AR) has gained increasingly attention from both research and industry communities. By overlaying digital information and content onto the physical world, AR enables users to experience the world in a more informative and efficient manner. As a major building block for AR systems, localization aims at determining the device's pose from a pre-built "map" consisting of visual and depth information in a known environment. While the localization problem has been widely studied in the literature, the "map" for AR systems is rarely discussed. In this paper, we introduce the AR Map for a specific scene to be composed of 1) color images with 6-DOF poses; 2) dense depth maps for each image and 3) a complete point cloud map. We then propose an efficient end-to-end solution to generating and evaluating AR Maps. Firstly, for efficient data capture, a backpack scanning device is presented with a unified calibration pipeline. Secondly, we propose an AR mapping pipeline which takes the input from the scanning device and produces accurate AR Maps. Finally, we present an approach to evaluating the accuracy of AR Maps with the help of the highly accurate reconstruction result from a high-end laser scanner. To the best of our knowledge, it is the first time to present an end-to-end solution to efficient and accurate mapping for AR applications.