 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterroGate: Learning to Share, Specialize, and Prune Representations for Multi-task Learning
Feb 26, 2024



Jointly learning multiple tasks with a unified model can improve accuracy and data efficiency, but it faces the challenge of task interference, where optimizing one task objective may inadvertently compromise the performance of another. A solution to mitigate this issue is to allocate task-specific parameters, free from interference, on top of shared features. However, manually designing such architectures is cumbersome, as practitioners need to balance between the overall performance across all tasks and the higher computational cost induced by the newly added parameters. In this work, we propose \textit{InterroGate}, a novel multi-task learning (MTL) architecture designed to mitigate task interference while optimizing inference computational efficiency. We employ a learnable gating mechanism to automatically balance the shared and task-specific representations while preserving the performance of all tasks. Crucially, the patterns of parameter sharing and specialization dynamically learned during training, become fixed at inference, resulting in a static, optimized MTL architecture. Through extensive empirical evaluations, we demonstrate SoTA results on three MTL benchmarks using convolutional as well as transformer-based backbones on CelebA, NYUD-v2, and PASCAL-Context.
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Feb 26, 2024



Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4\times$, with minor performance penalties of $1-2\%$ for translation and summarization tasks compared to the LLM.
Scalarization for Multi-Task and Multi-Domain Learning at Scale
Oct 13, 2023Training a single model on multiple input domains and/or output tasks allows for compressing information from multiple sources into a unified backbone hence improves model efficiency. It also enables potential positive knowledge transfer across tasks/domains, leading to improved accuracy and data-efficient training. However, optimizing such networks is a challenge, in particular due to discrepancies between the different tasks or domains: Despite several hypotheses and solutions proposed over the years, recent work has shown that uniform scalarization training, i.e., simply minimizing the average of the task losses, yields on-par performance with more costly SotA optimization methods. This raises the issue of how well we understand the training dynamics of multi-task and multi-domain networks. In this work, we first devise a large-scale unified analysis of multi-domain and multi-task learning to better understand the dynamics of scalarization across varied task/domain combinations and model sizes. Following these insights, we then propose to leverage population-based training to efficiently search for the optimal scalarization weights when dealing with a large number of tasks or domains.
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
Jul 05, 2023



The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs (e.g., 20 epochs on ImageNet) with little training overhead. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.
Revisiting Single-gated Mixtures of Experts
Apr 11, 2023



Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.
A Flexible Selection Scheme for Minimum-Effort Transfer Learning
Aug 27, 2020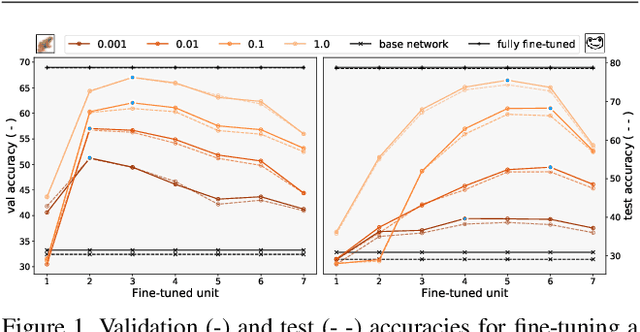

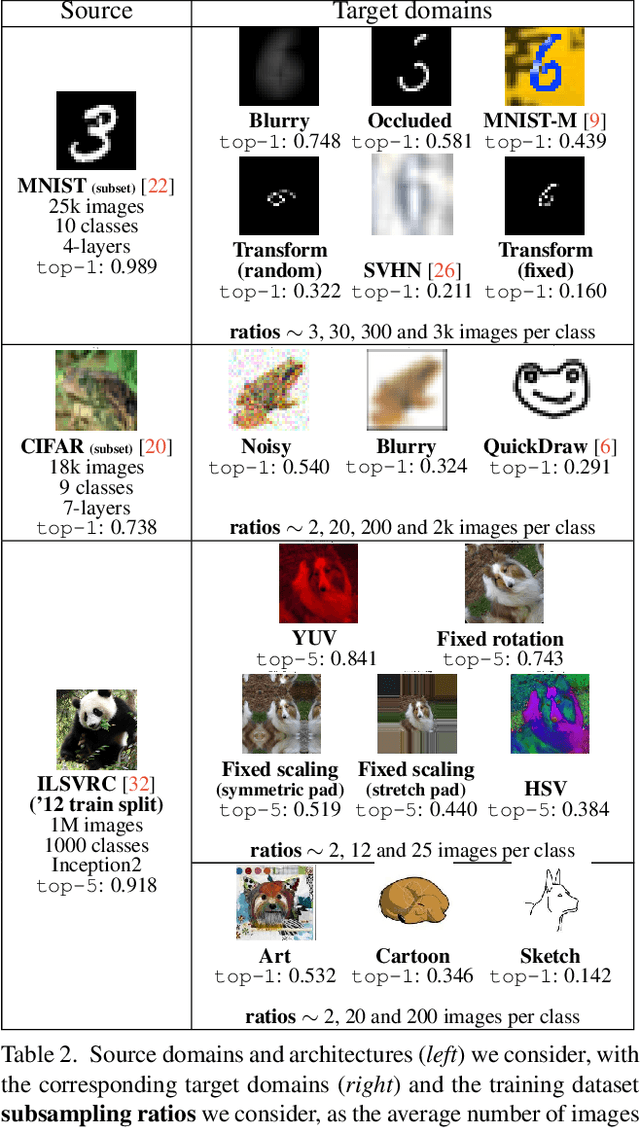
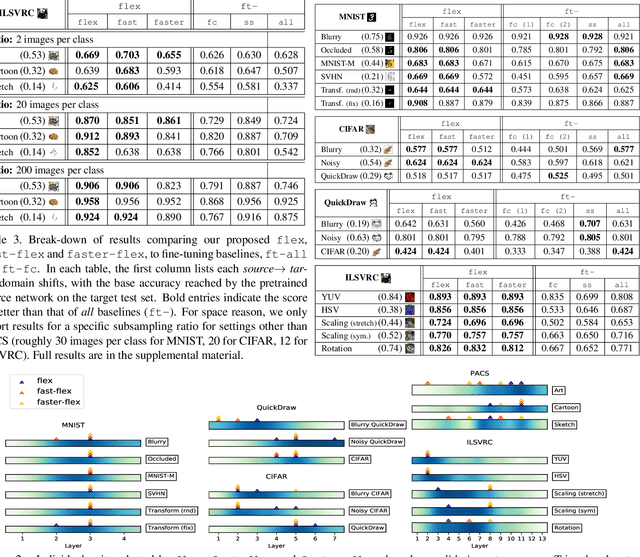
Fine-tuning is a popular way of exploiting knowledge contained in a pre-trained convolutional network for a new visual recognition task. However, the orthogonal setting of transferring knowledge from a pretrained network to a visually different yet semantically close source is rarely considered: This commonly happens with real-life data, which is not necessarily as clean as the training source (noise, geometric transformations, different modalities, etc.). To tackle such scenarios, we introduce a new, generalized form of fine-tuning, called flex-tuning, in which any individual unit (e.g. layer) of a network can be tuned, and the most promising one is chosen automatically. In order to make the method appealing for practical use, we propose two lightweight and faster selection procedures that prove to be good approximations in practice. We study these selection criteria empirically across a variety of domain shifts and data scarcity scenarios, and show that fine-tuning individual units, despite its simplicity, yields very good results as an adaptation technique. As it turns out, in contrast to common practice, rather than the last fully-connected unit it is best to tune an intermediate or early one in many domain-shift scenarios, which is accurately detected by flex-tuning.
Localizing Grouped Instances for Efficient Detection in Low-Resource Scenarios
Apr 27, 2020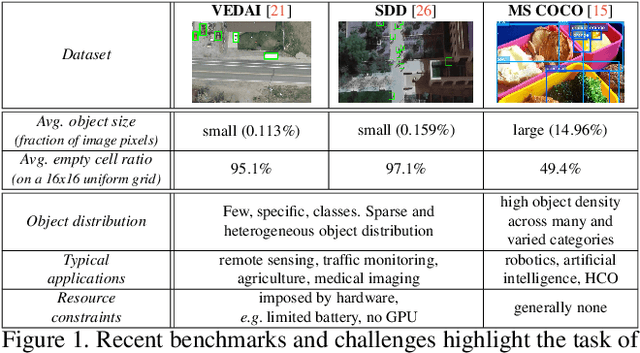
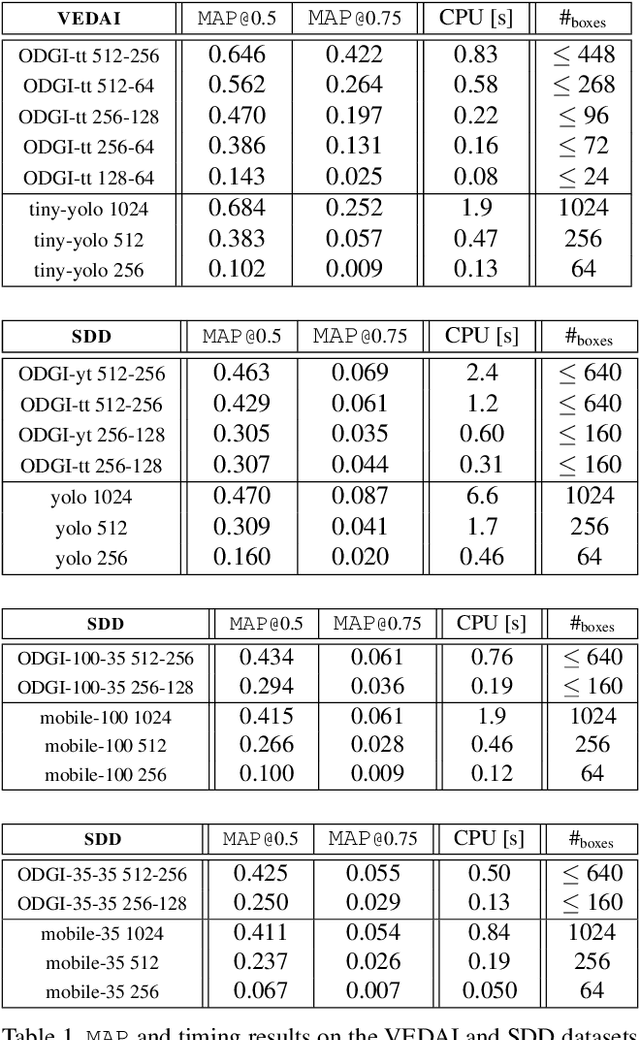
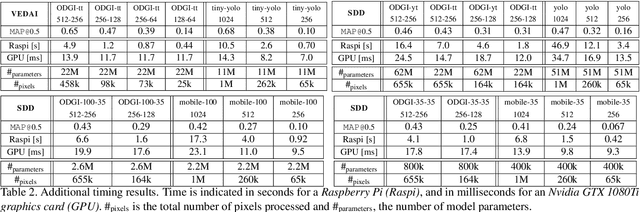
State-of-the-art detection systems are generally evaluated on their ability to exhaustively retrieve objects densely distributed in the image, across a wide variety of appearances and semantic categories. Orthogonal to this, many real-life object detection applications, for example in remote sensing, instead require dealing with large images that contain only a few small objects of a single class, scattered heterogeneously across the space. In addition, they are often subject to strict computational constraints, such as limited battery capacity and computing power. To tackle these more practical scenarios, we propose a novel flexible detection scheme that efficiently adapts to variable object sizes and densities: We rely on a sequence of detection stages, each of which has the ability to predict groups of objects as well as individuals. Similar to a detection cascade, this multi-stage architecture spares computational effort by discarding large irrelevant regions of the image early during the detection process. The ability to group objects provides further computational and memory savings, as it allows working with lower image resolutions in early stages, where groups are more easily detected than individuals, as they are more salient. We report experimental results on two aerial image datasets, and show that the proposed method is as accurate yet computationally more efficient than standard single-shot detectors, consistently across three different backbone architectures.
Probabilistic Image Colorization
May 11, 2017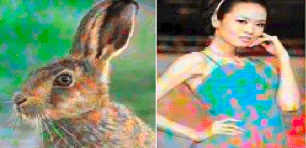
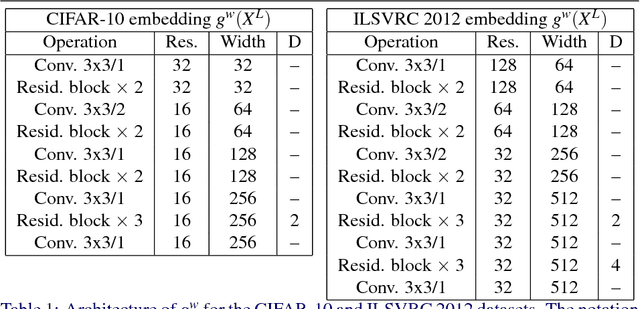
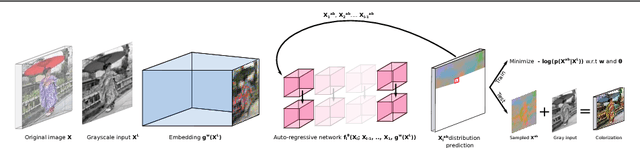

We develop a probabilistic technique for colorizing grayscale natural images. In light of the intrinsic uncertainty of this task, the proposed probabilistic framework has numerous desirable properties. In particular, our model is able to produce multiple plausible and vivid colorizations for a given grayscale image and is one of the first colorization models to provide a proper stochastic sampling scheme. Moreover, our training procedure is supported by a rigorous theoretical framework that does not require any ad hoc heuristics and allows for efficient modeling and learning of the joint pixel color distribution. We demonstrate strong quantitative and qualitative experimental results on the CIFAR-10 dataset and the challenging ILSVRC 2012 dataset.