 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network
Apr 06, 2018




This paper presents a novel method to deal with the challenging task of generating photographic images conditioned on semantic image descriptions. Our method introduces accompanying hierarchical-nested adversarial objectives inside the network hierarchies, which regularize mid-level representations and assist generator training to capture the complex image statistics. We present an extensile single-stream generator architecture to better adapt the jointed discriminators and push generated images up to high resolutions. We adopt a multi-purpose adversarial loss to encourage more effective image and text information usage in order to improve the semantic consistency and image fidelity simultaneously. Furthermore, we introduce a new visual-semantic similarity measure to evaluate the semantic consistency of generated images. With extensive experimental validation on three public datasets, our method significantly improves previous state of the arts on all datasets over different evaluation metrics.
An Assessment of GANs for Identity-related Applications
Dec 18, 2020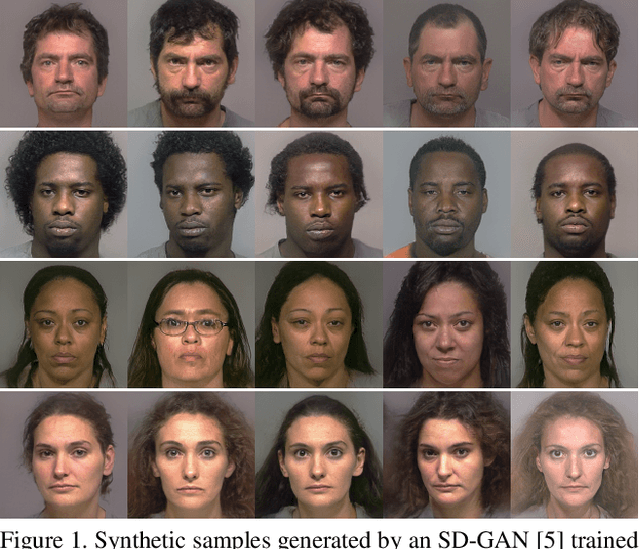

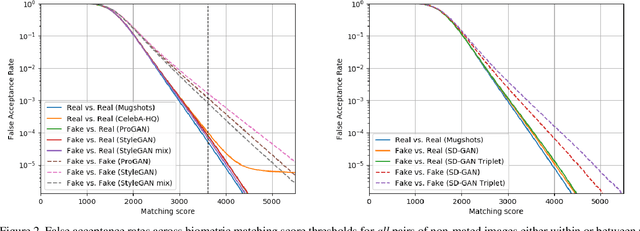

Generative Adversarial Networks (GANs) are now capable of producing synthetic face images of exceptionally high visual quality. In parallel to the development of GANs themselves, efforts have been made to develop metrics to objectively assess the characteristics of the synthetic images, mainly focusing on visual quality and the variety of images. Little work has been done, however, to assess overfitting of GANs and their ability to generate new identities. In this paper we apply a state of the art biometric network to various datasets of synthetic images and perform a thorough assessment of their identity-related characteristics. We conclude that GANs can indeed be used to generate new, imagined identities meaning that applications such as anonymisation of image sets and augmentation of training datasets with distractor images are viable applications. We also assess the ability of GANs to disentangle identity from other image characteristics and propose a novel GAN triplet loss that we show to improve this disentanglement.
Deep learning using Havrda-Charvat entropy for classification of pulmonary endomicroscopy
Apr 19, 2021
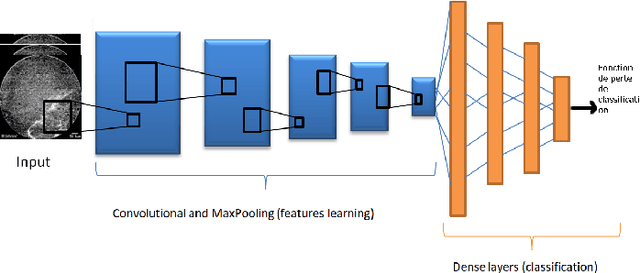
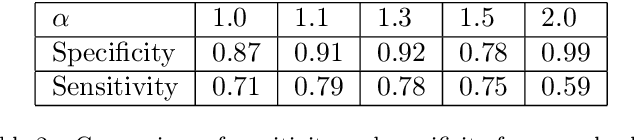
Pulmonary optical endomicroscopy (POE) is an imaging technology in real time. It allows to examine pulmonary alveoli at a microscopic level. Acquired in clinical settings, a POE image sequence can have as much as 25% of the sequence being uninformative frames (i.e. pure-noise and motion artefacts). For future data analysis, these uninformative frames must be first removed from the sequence. Therefore, the objective of our work is to develop an automatic detection method of uninformative images in endomicroscopy images. We propose to take the detection problem as a classification one. Considering advantages of deep learning methods, a classifier based on CNN (Convolutional Neural Network) is designed with a new loss function based on Havrda-Charvat entropy which is a parametrical generalization of the Shannon entropy. We propose to use this formula to get a better hold on all sorts of data since it provides a model more stable than the Shannon entropy. Our method is tested on one POE dataset including 2947 distinct images, is showing better results than using Shannon entropy and behaves better with regard to the problem of overfitting. Keywords: Deep Learning, CNN, Shannon entropy, Havrda-Charvat entropy, Pulmonary optical endomicroscopy.
Towards Automatic Construction of Diverse, High-quality Image Dataset
Aug 22, 2017
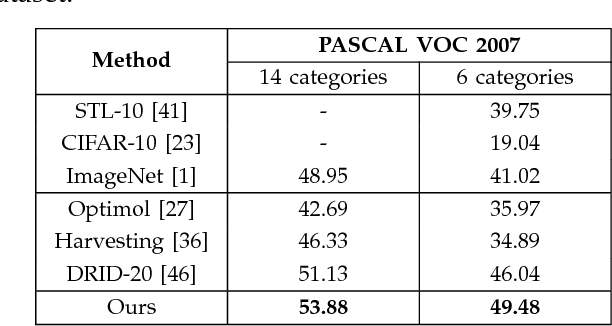
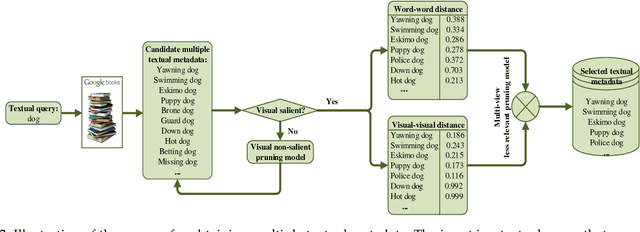
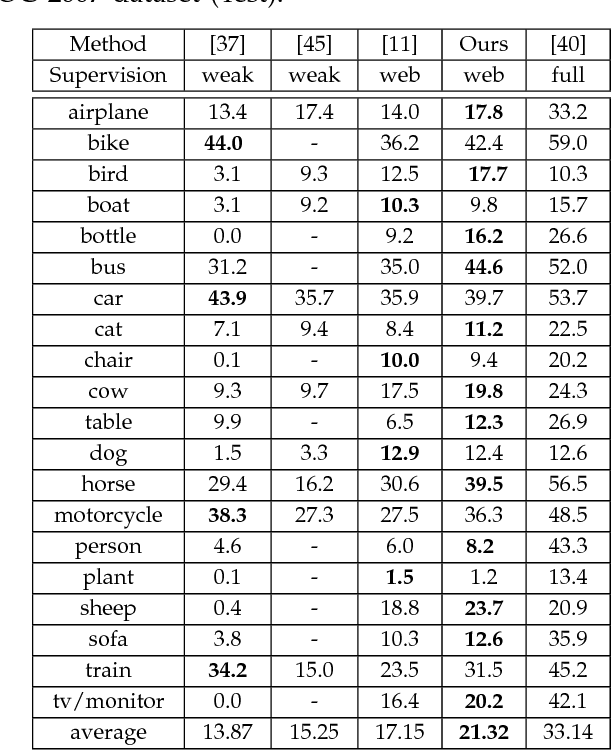
The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual metadata. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual metadata removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.
Video Instance Segmentation with a Propose-Reduce Paradigm
Mar 25, 2021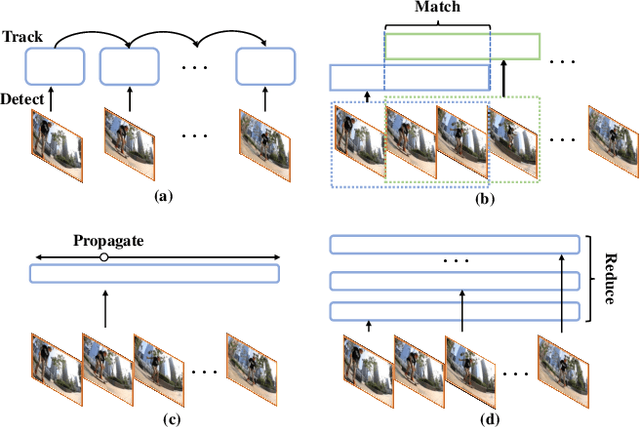
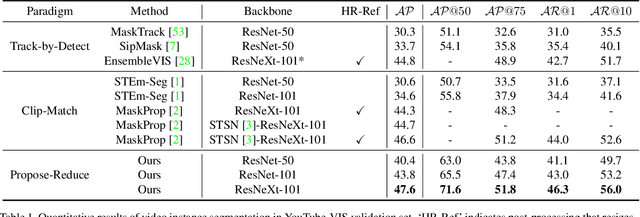
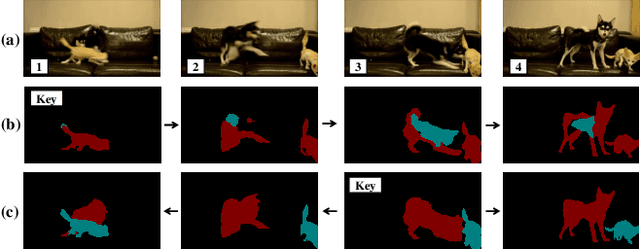
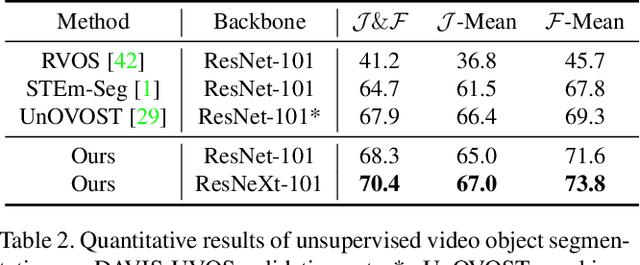
Video instance segmentation (VIS) aims to segment and associate all instances of predefined classes for each frame in videos. Prior methods usually obtain segmentation for a frame or clip first, and then merge the incomplete results by tracking or matching. These methods may cause error accumulation in the merging step. Contrarily, we propose a new paradigm -- Propose-Reduce, to generate complete sequences for input videos by a single step. We further build a sequence propagation head on the existing image-level instance segmentation network for long-term propagation. To ensure robustness and high recall of our proposed framework, multiple sequences are proposed where redundant sequences of the same instance are reduced. We achieve state-of-the-art performance on two representative benchmark datasets -- we obtain 47.6% in terms of AP on YouTube-VIS validation set and 70.4% for J&F on DAVIS-UVOS validation set.
Unveiling personnel movement in a larger indoor area with a non-overlapping multi-camera system
Apr 10, 2021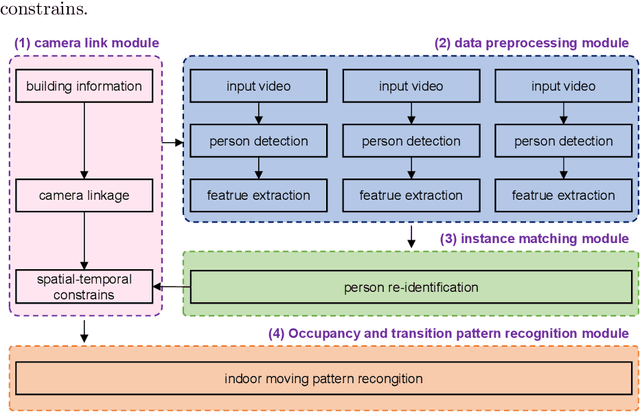
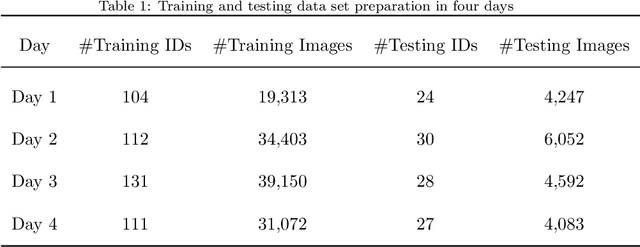
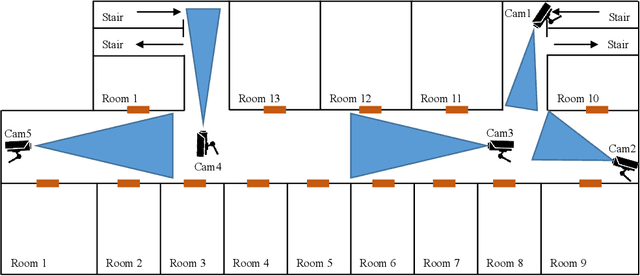

Surveillance cameras are widely applied for indoor occupancy measurement and human movement perception, which benefit for building energy management and social security. To address the challenges of limited view angle of single camera as well as lacking of inter-camera collaboration, this study presents a non-overlapping multi-camera system to enlarge the surveillance area and devotes to retrieve the same person appeared from different camera views. The system is deployed in an office building and four-day videos are collected. By training a deep convolutional neural network, the proposed system first extracts the appearance feature embeddings of each personal image, which detected from different cameras, for similarity comparison. Then, a stochastic inter-camera transition matrix is associated with appearance feature for further improving the person re-identification ranking results. Finally, a noise-suppression explanation is given for analyzing the matching improvements. This paper expands the scope of indoor movement perception based on non-overlapping multiple cameras and improves the accuracy of pedestrian re-identification without introducing additional types of sensors.
GyroFlow: Gyroscope-Guided Unsupervised Optical Flow Learning
Mar 25, 2021
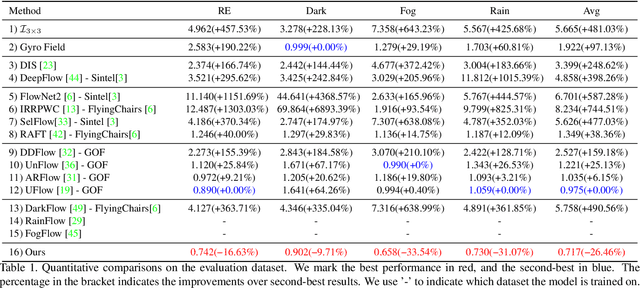
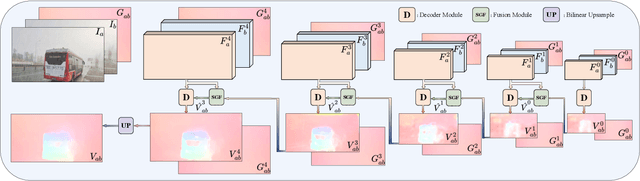
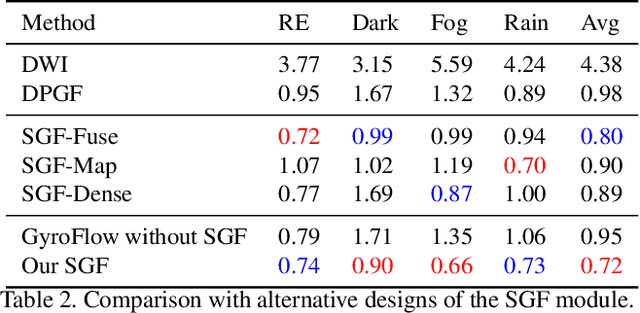
Existing optical flow methods are erroneous in challenging scenes, such as fog, rain, and night because the basic optical flow assumptions such as brightness and gradient constancy are broken. To address this problem, we present an unsupervised learning approach that fuses gyroscope into optical flow learning. Specifically, we first convert gyroscope readings into motion fields named gyro field. Then, we design a self-guided fusion module to fuse the background motion extracted from the gyro field with the optical flow and guide the network to focus on motion details. To the best of our knowledge, this is the first deep learning-based framework that fuses gyroscope data and image content for optical flow learning. To validate our method, we propose a new dataset that covers regular and challenging scenes. Experiments show that our method outperforms the state-of-art methods in both regular and challenging scenes.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 19, 2021

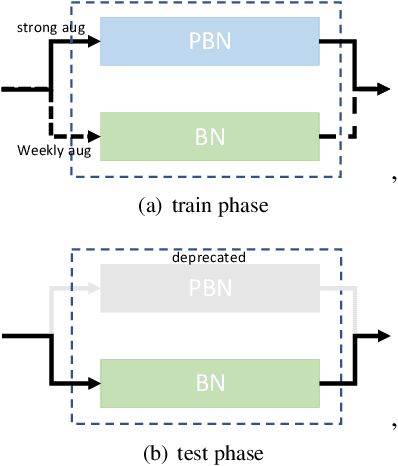

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
Can Image Retrieval help Visual Saliency Detection?
Sep 24, 2017

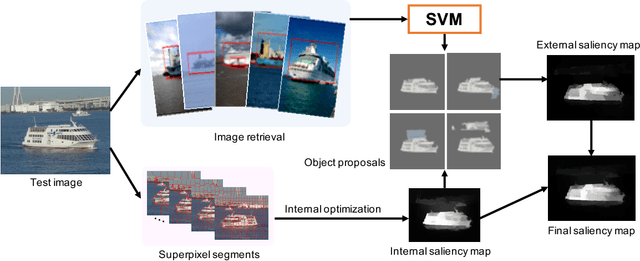

We propose a novel image retrieval framework for visual saliency detection using information about salient objects contained within bounding box annotations for similar images. For each test image, we train a customized SVM from similar example images to predict the saliency values of its object proposals and generate an external saliency map (ES) by aggregating the regional scores. To overcome limitations caused by the size of the training dataset, we also propose an internal optimization module which computes an internal saliency map (IS) by measuring the low-level contrast information of the test image. The two maps, ES and IS, have complementary properties so we take a weighted combination to further improve the detection performance. Experimental results on several challenging datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods.
Bandwidth-Agile Image Transmission with Deep Joint Source-Channel Coding
Sep 26, 2020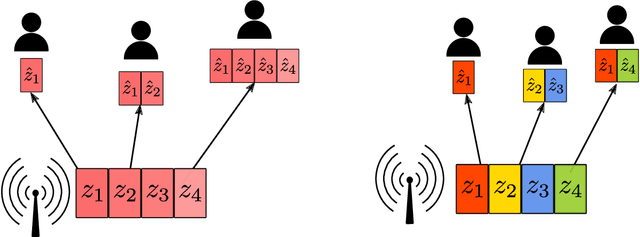
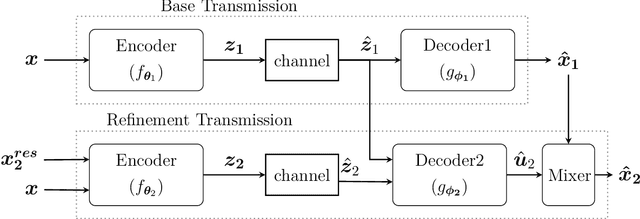
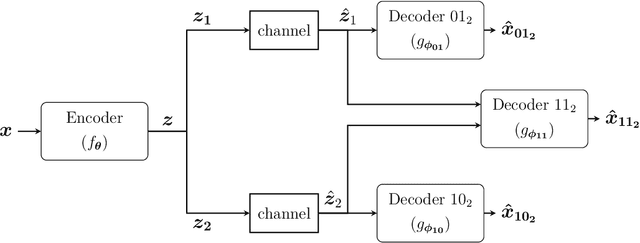
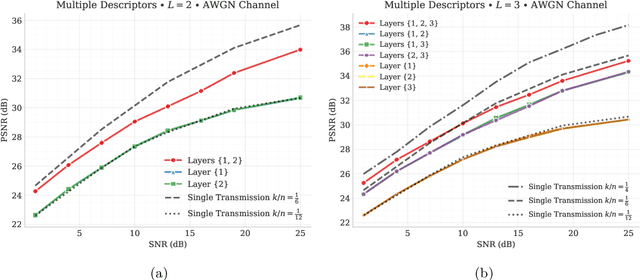
We introduce deep learning based communication methods for adaptive-bandwidth transmission of images over wireless channels. We consider the scenario in which images are transmitted progressively in discrete layers over time or frequency, and such layers can be aggregated by receivers in order to increase the quality of their reconstructions. We investigate two scenarios, one in which the layers are sent sequentially, and incrementally contribute to the refinement of a reconstruction, and another in which the layers are independent and can be retrieved in any order. Those scenarios correspond to the well known problems of successive refinement and multiple descriptions, respectively, in the context of joint source-channel coding (JSCC). We propose DeepJSCC-$l$, an innovative solution that uses convolutional autoencoders, and present three different architectures with different complexity trade-offs. To the best of our knowledge, this is the first practical multiple-description JSCC scheme developed and tested for practical information sources and channels. Numerical results show that DeepJSCC-$l$ can learn different strategies to divide the sources into a layered representation with negligible losses to the end-to-end performance when compared to a single transmission. Moreover, compared to state-of-the-art digital communication schemes, DeepJSCC-$l$ performs well in the challenging low signal-to-noise ratio (SNR) and small bandwidth regimes, and provides graceful degradation with channel SNR.