 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Frame Interpolation with Transformer
May 15, 2022
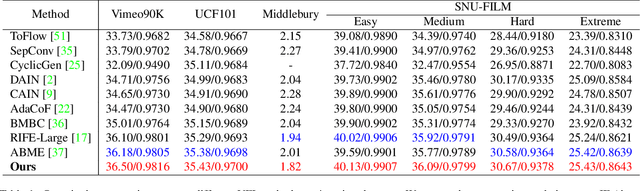
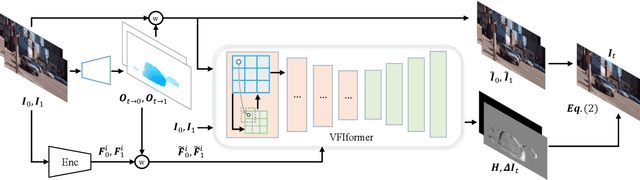

Video frame interpolation (VFI), which aims to synthesize intermediate frames of a video, has made remarkable progress with development of deep convolutional networks over past years. Existing methods built upon convolutional networks generally face challenges of handling large motion due to the locality of convolution operations. To overcome this limitation, we introduce a novel framework, which takes advantage of Transformer to model long-range pixel correlation among video frames. Further, our network is equipped with a novel cross-scale window-based attention mechanism, where cross-scale windows interact with each other. This design effectively enlarges the receptive field and aggregates multi-scale information. Extensive quantitative and qualitative experiments demonstrate that our method achieves new state-of-the-art results on various benchmarks.
Video Instance Segmentation with a Propose-Reduce Paradigm
Mar 25, 2021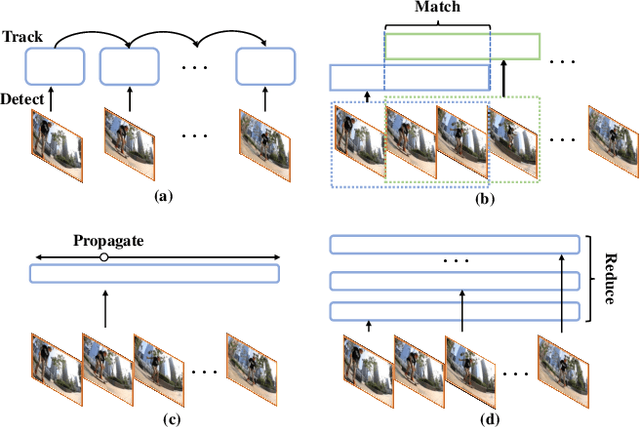
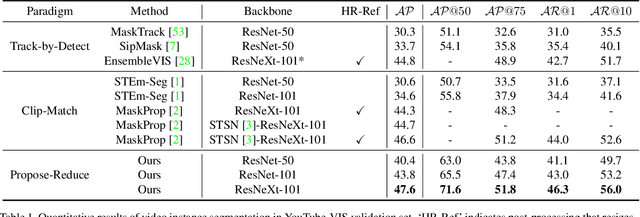
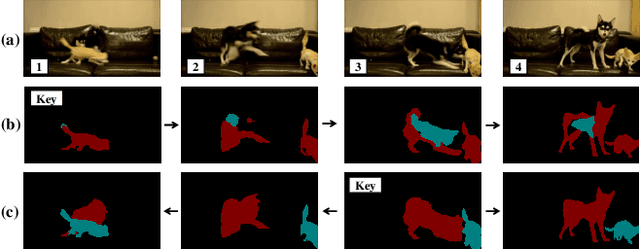
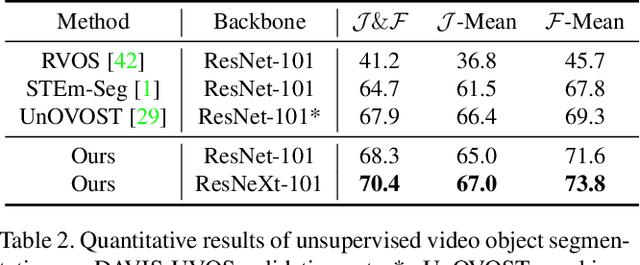
Video instance segmentation (VIS) aims to segment and associate all instances of predefined classes for each frame in videos. Prior methods usually obtain segmentation for a frame or clip first, and then merge the incomplete results by tracking or matching. These methods may cause error accumulation in the merging step. Contrarily, we propose a new paradigm -- Propose-Reduce, to generate complete sequences for input videos by a single step. We further build a sequence propagation head on the existing image-level instance segmentation network for long-term propagation. To ensure robustness and high recall of our proposed framework, multiple sequences are proposed where redundant sequences of the same instance are reduced. We achieve state-of-the-art performance on two representative benchmark datasets -- we obtain 47.6% in terms of AP on YouTube-VIS validation set and 70.4% for J&F on DAVIS-UVOS validation set.
Facelet-Bank for Fast Portrait Manipulation
Mar 30, 2018
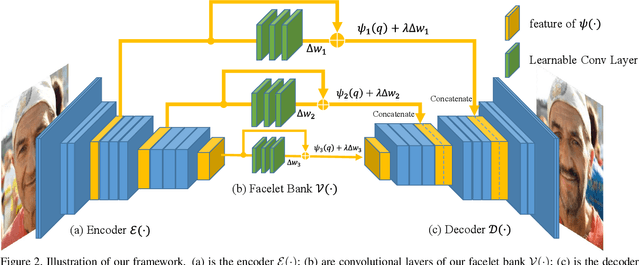


Digital face manipulation has become a popular and fascinating way to touch images with the prevalence of smartphones and social networks. With a wide variety of user preferences, facial expressions, and accessories, a general and flexible model is necessary to accommodate different types of facial editing. In this paper, we propose a model to achieve this goal based on an end-to-end convolutional neural network that supports fast inference, edit-effect control, and quick partial-model update. In addition, this model learns from unpaired image sets with different attributes. Experimental results show that our framework can handle a wide range of expressions, accessories, and makeup effects. It produces high-resolution and high-quality results in fast speed.