 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Rank Estimation to Rank Approximation: Rank Residual Constraint for Image Denoising
Aug 14, 2018
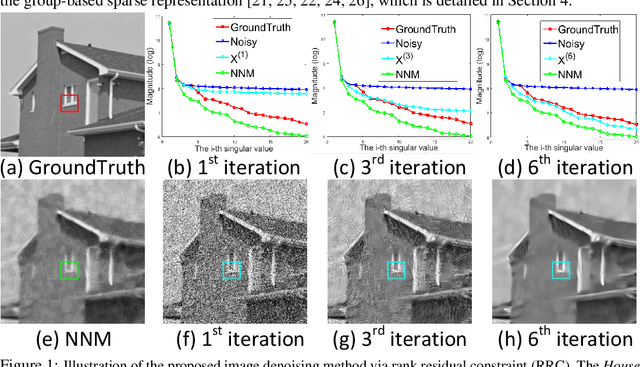

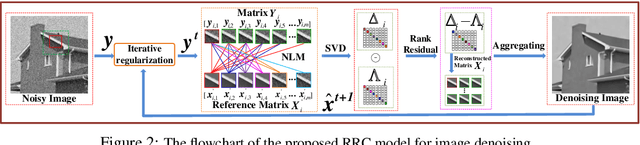

In this paper, we propose a novel approach for the rank minimization problem, termed rank residual constraint (RRC). Different from existing low-rank based approaches, such as the well-known weighted nuclear norm minimization (WNNM) and nuclear norm minimization (NNM), which aim to estimate the underlying low-rank matrix directly from the corrupted observation, we progressively approximate or approach the underlying low-rank matrix via minimizing the rank residual. By integrating the image nonlocal self-similarity (NSS) prior with the proposed RRC model, we develop an iterative algorithm for image denoising. To this end, we first present a recursive based nonlocal means method to obtain a good reference of the original image patch groups, and then the rank residual of the image patch groups between this reference and the noisy image is minimized to achieve a better estimate of the desired image. In this manner, both the reference and the estimated image in each iteration are improved gradually and jointly. Based on the group-based sparse representation model, we further provide a theoretical analysis on the feasibility of the proposed RRC model. Experimental results demonstrate that the proposed RRC model outperforms many state-of-the-art denoising methods in both the objective and perceptual qualities.
Efficient and Generic 1D Dilated Convolution Layer for Deep Learning
Apr 16, 2021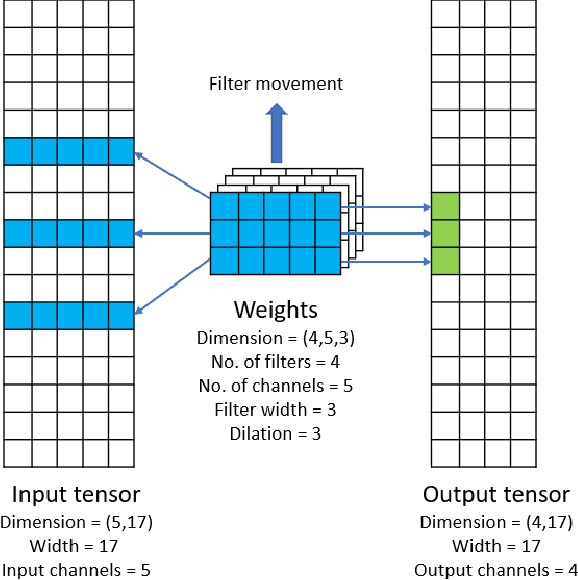
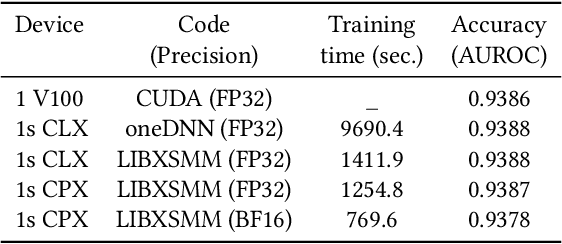
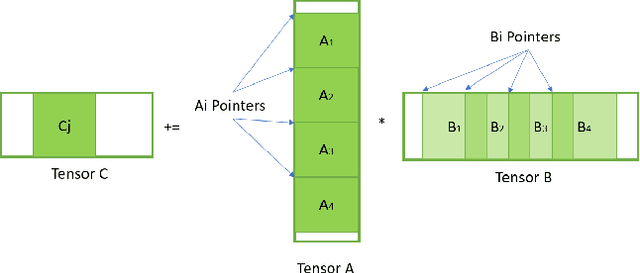
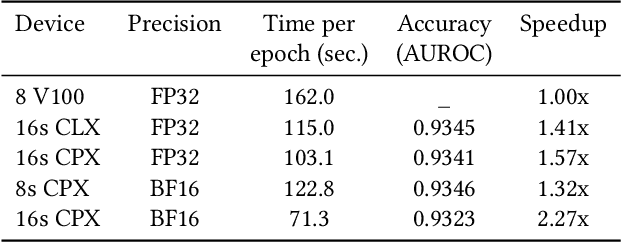
Convolutional neural networks (CNNs) have found many applications in tasks involving two-dimensional (2D) data, such as image classification and image processing. Therefore, 2D convolution layers have been heavily optimized on CPUs and GPUs. However, in many applications - for example genomics and speech recognition, the data can be one-dimensional (1D). Such applications can benefit from optimized 1D convolution layers. In this work, we introduce our efficient implementation of a generic 1D convolution layer covering a wide range of parameters. It is optimized for x86 CPU architectures, in particular, for architectures containing Intel AVX-512 and AVX-512 BFloat16 instructions. We use the LIBXSMM library's batch-reduce General Matrix Multiplication (BRGEMM) kernel for FP32 and BFloat16 precision. We demonstrate that our implementation can achieve up to 80% efficiency on Intel Xeon Cascade Lake and Cooper Lake CPUs. Additionally, we show the generalization capability of our BRGEMM based approach by achieving high efficiency across a range of parameters. We consistently achieve higher efficiency than the 1D convolution layer with Intel oneDNN library backend for varying input tensor widths, filter widths, number of channels, filters, and dilation parameters. Finally, we demonstrate the performance of our optimized 1D convolution layer by utilizing it in the end-to-end neural network training with real genomics datasets and achieve up to 6.86x speedup over the oneDNN library-based implementation on Cascade Lake CPUs. We also demonstrate the scaling with 16 sockets of Cascade/Cooper Lake CPUs and achieve significant speedup over eight V100 GPUs using a similar power envelop. In the end-to-end training, we get a speedup of 1.41x on Cascade Lake with FP32, 1.57x on Cooper Lake with FP32, and 2.27x on Cooper Lake with BFloat16 over eight V100 GPUs with FP32.
A 3D model-based approach for fitting masks to faces in the wild
Mar 01, 2021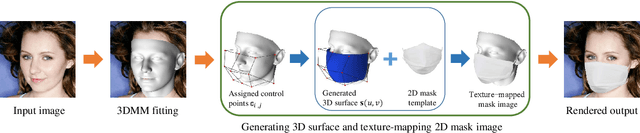
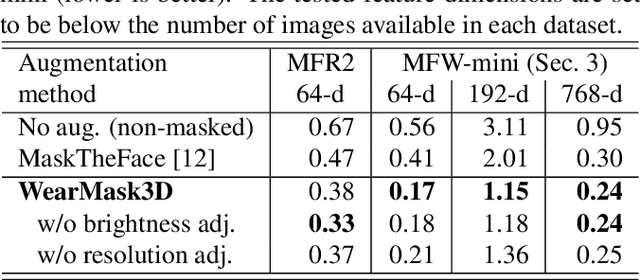

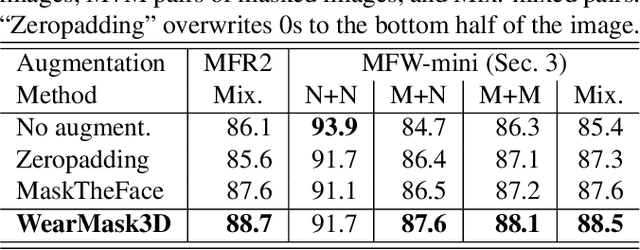
Face recognition research now requires a large number of labelled masked face images in the era of this unprecedented COVID-19 pandemic. Unfortunately, the rapid spread of the virus has left us little time to prepare for such dataset in the wild. To circumvent this issue, we present a 3D model-based approach called WearMask3D for augmenting face images of various poses to the masked face counterparts. Our method proceeds by first fitting a 3D morphable model on the input image, second overlaying the mask surface onto the face model and warping the respective mask texture, and last projecting the 3D mask back to 2D. The mask texture is adapted based on the brightness and resolution of the input image. By working in 3D, our method can produce more natural masked faces of diverse poses from a single mask texture. To compare precisely between different augmentation approaches, we have constructed a dataset comprising masked and unmasked faces with labels called MFW-mini. Experimental results demonstrate WearMask3D, which will be made publicly available, produces more realistic masked images, and utilizing these images for training leads to improved recognition accuracy of masked faces compared to the state-of-the-art.
Attention-guided Temporal Coherent Video Object Matting
May 24, 2021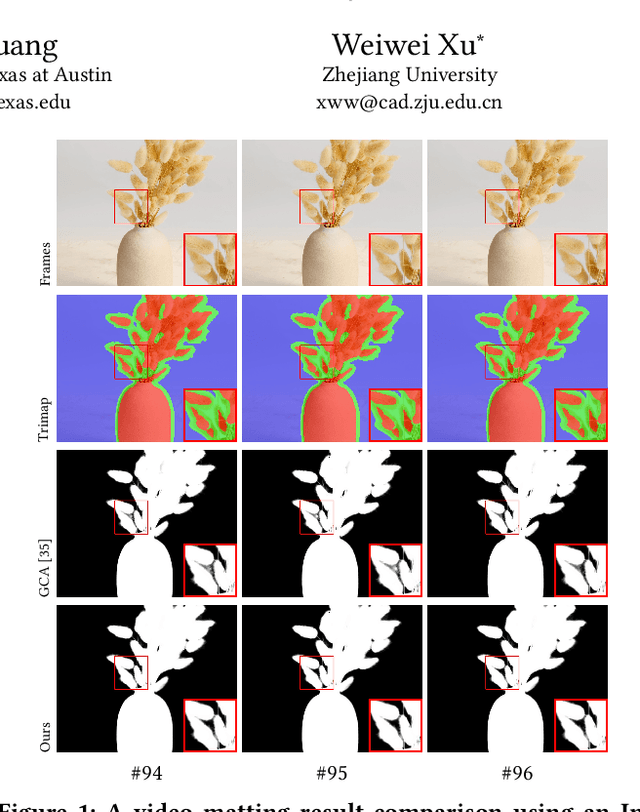
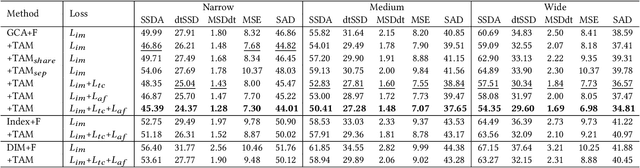
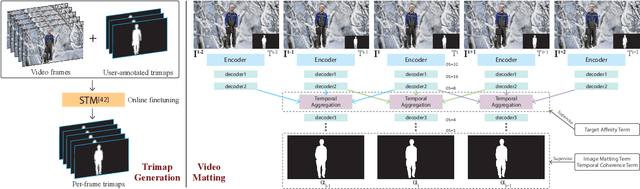
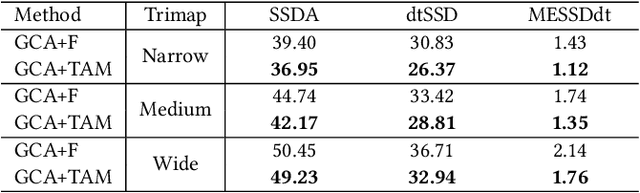
This paper proposes a novel deep learning-based video object matting method that can achieve temporally coherent matting results. Its key component is an attention-based temporal aggregation module that maximizes image matting networks' strength for video matting networks. This module computes temporal correlations for pixels adjacent to each other along the time axis in feature space to be robust against motion noises. We also design a novel loss term to train the attention weights, which drastically boosts the video matting performance. Besides, we show how to effectively solve the trimap generation problem by fine-tuning a state-of-the-art video object segmentation network with a sparse set of user-annotated keyframes. To facilitate video matting and trimap generation networks' training, we construct a large-scale video matting dataset with 80 training and 28 validation foreground video clips with ground-truth alpha mattes. Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion. Our code and dataset can be found at https://github.com/yunkezhang/TCVOM
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

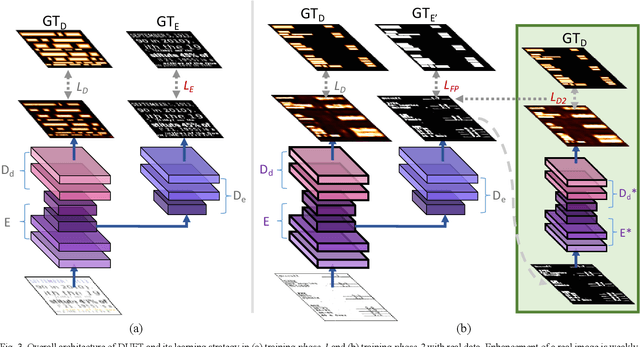

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
Jun 10, 2021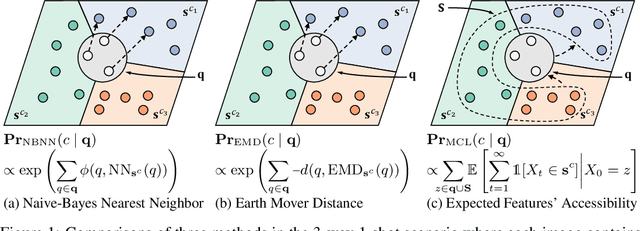
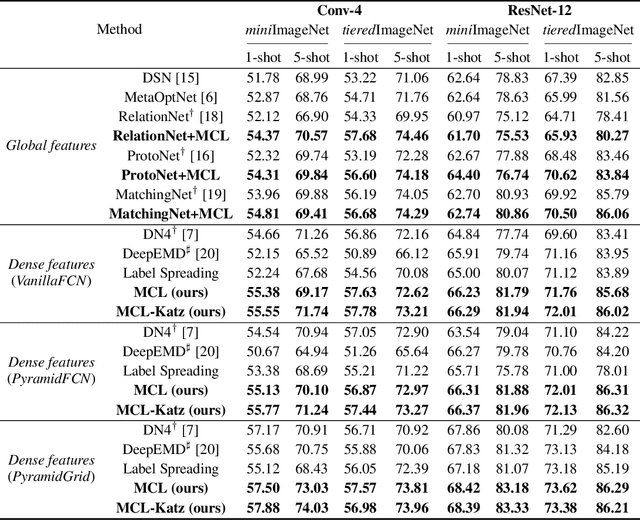
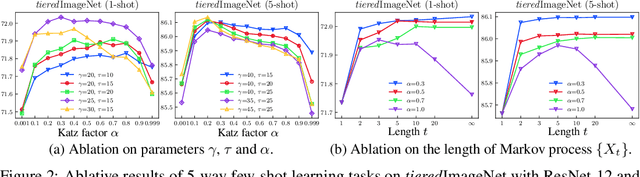
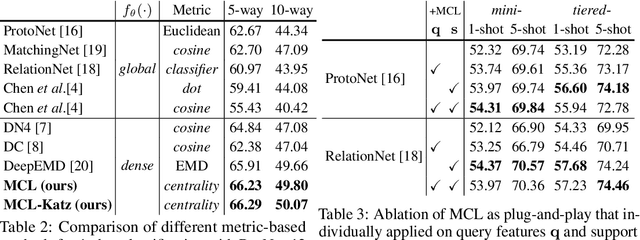
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to accommodate new tasks not seen during training, given only a few examples. To handle the limited-data problem in few-shot regimes, recent methods tend to collectively use a set of local features to densely represent an image instead of using a mixed global feature. They generally explore a unidirectional query-to-support paradigm in FSL, e.g., find the nearest/optimal support feature for each query feature and aggregate these local matches for a joint classification. In this paper, we propose a new method Mutual Centralized Learning (MCL) to fully affiliate the two disjoint sets of dense features in a bidirectional paradigm. We associate each local feature with a particle that can bidirectionally random walk in a discrete feature space by the affiliations. To estimate the class probability, we propose the features' accessibility that measures the expected number of visits to the support features of that class in a Markov process. We relate our method to learning a centrality on an affiliation network and demonstrate its capability to be plugged in existing methods by highlighting centralized local features. Experiments show that our method achieves the state-of-the-art on both miniImageNet and tieredImageNet.
FedScale: Benchmarking Model and System Performance of Federated Learning
May 24, 2021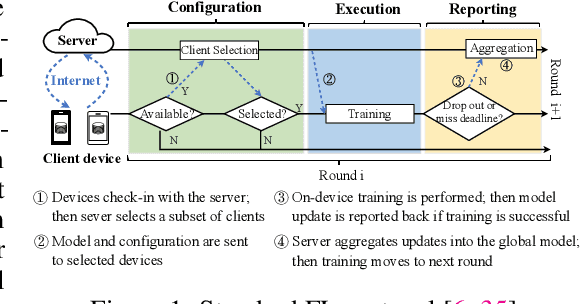
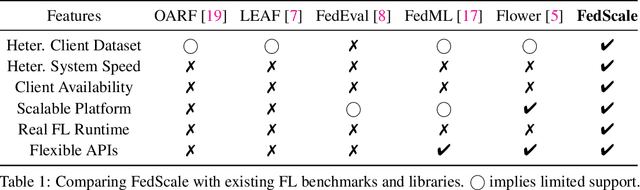
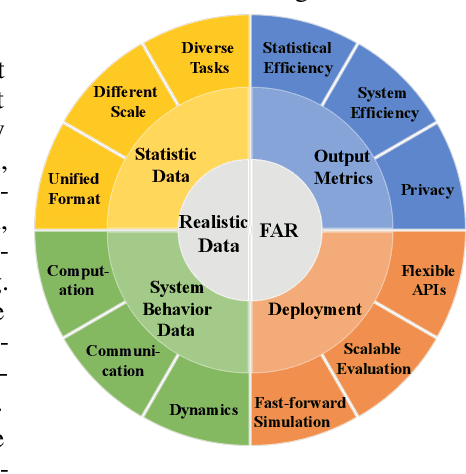
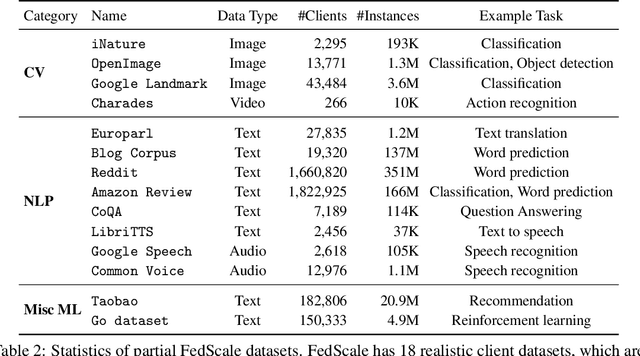
We present FedScale, a diverse set of challenging and realistic benchmark datasets to facilitate scalable, comprehensive, and reproducible federated learning (FL) research. FedScale datasets are large-scale, encompassing a diverse range of important FL tasks, such as image classification, object detection, language modeling, speech recognition, and reinforcement learning. For each dataset, we provide a unified evaluation protocol using realistic data splits and evaluation metrics. To meet the pressing need for reproducing realistic FL at scale, we have also built an efficient evaluation platform to simplify and standardize the process of FL experimental setup and model evaluation. Our evaluation platform provides flexible APIs to implement new FL algorithms and include new execution backends with minimal developer efforts. Finally, we perform indepth benchmark experiments on these datasets. Our experiments suggest that FedScale presents significant challenges of heterogeneity-aware co-optimizations of the system and statistical efficiency under realistic FL characteristics, indicating fruitful opportunities for future research. FedScale is open-source with permissive licenses and actively maintained, and we welcome feedback and contributions from the community.
OverlapNet: Loop Closing for LiDAR-based SLAM
May 24, 2021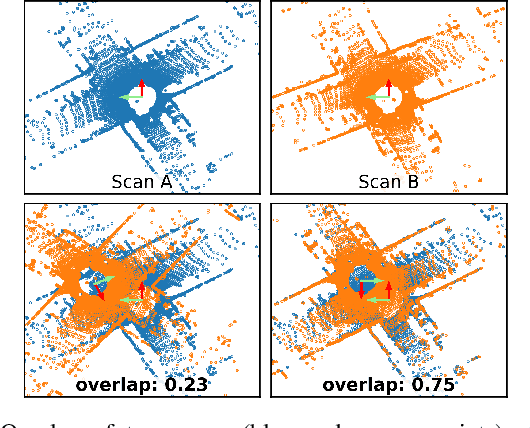
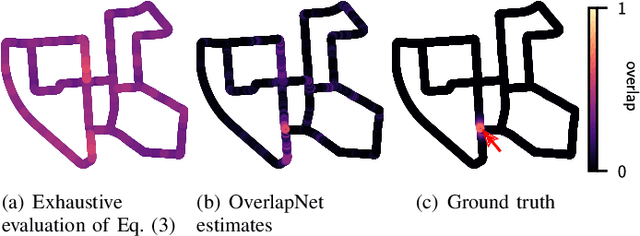
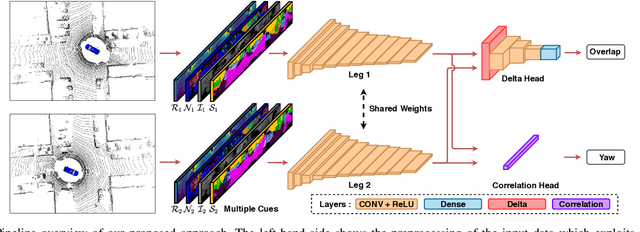
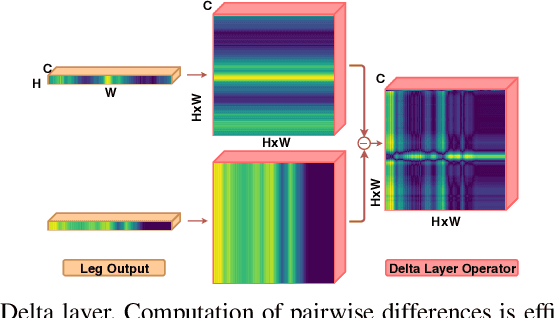
Simultaneous localization and mapping (SLAM) is a fundamental capability required by most autonomous systems. In this paper, we address the problem of loop closing for SLAM based on 3D laser scans recorded by autonomous cars. Our approach utilizes a deep neural network exploiting different cues generated from LiDAR data for finding loop closures. It estimates an image overlap generalized to range images and provides a relative yaw angle estimate between pairs of scans. Based on such predictions, we tackle loop closure detection and integrate our approach into an existing SLAM system to improve its mapping results. We evaluate our approach on sequences of the KITTI odometry benchmark and the Ford campus dataset. We show that our method can effectively detect loop closures surpassing the detection performance of state-of-the-art methods. To highlight the generalization capabilities of our approach, we evaluate our model on the Ford campus dataset while using only KITTI for training. The experiments show that the learned representation is able to provide reliable loop closure candidates, also in unseen environments.
Joint multi-field T$_1$ quantification for fast field-cycling MRI
Feb 19, 2021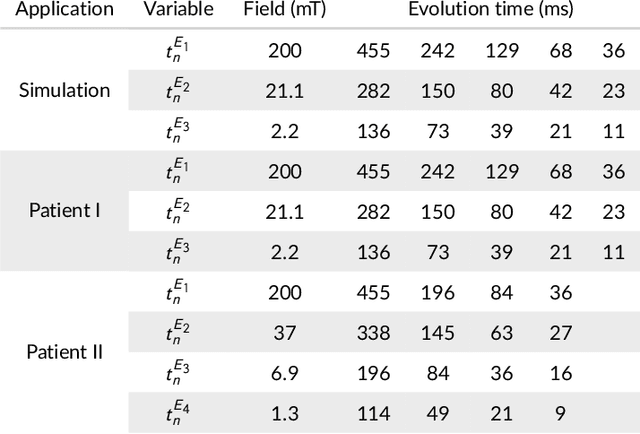
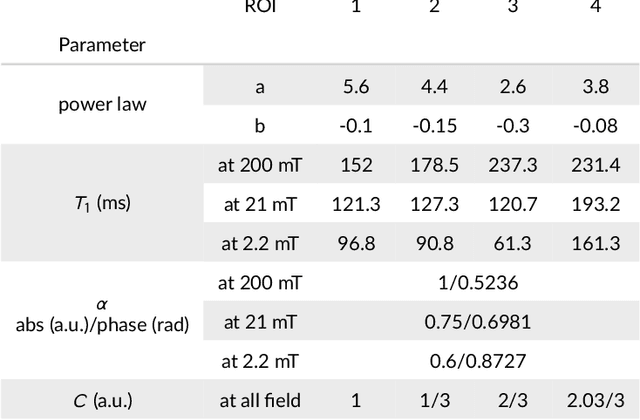
Recent developments in hardware design enable the use of Fast Field-Cycling (FFC) techniques in MRI to exploit the different relaxation rates at very low field strength, achieving novel contrast. The method opens new avenues for in vivo characterisations of pathologies but at the expense of longer acquisition times. To mitigate this we propose a model-based reconstruction method that fully exploits the high information redundancy offered by FFC methods. This is based on joining spatial information from all fields based on TGV regularization. The algorithm was tested on brain stroke images, both simulated and acquired from FFC patients scans using an FFC spin echo sequences. The results are compared to non-linear least squares combined with k-space filtering. The proposed method shows excellent abilities to remove noise while maintaining sharp image features with large SNR gains at low-field images, clearly outperforming the reference approach. Especially patient data shows huge improvements in visual appearance over all fields. The proposed reconstruction technique largely improves FFC image quality, further pushing this new technology towards clinical standards.
Super Resolution of Arterial Spin Labeling MR Imaging Using Unsupervised Multi-Scale Generative Adversarial Network
Sep 14, 2020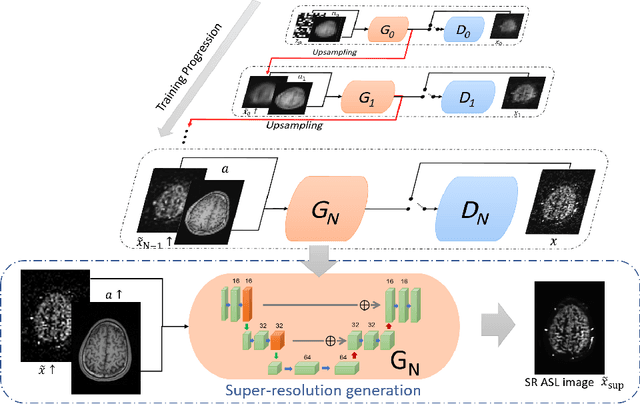
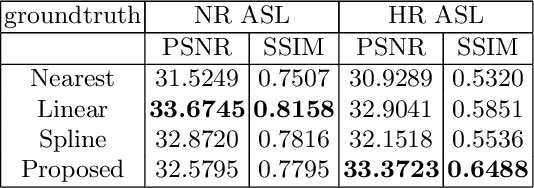
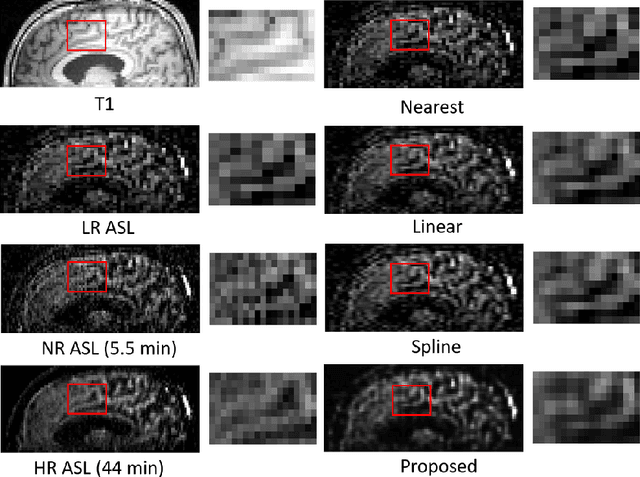
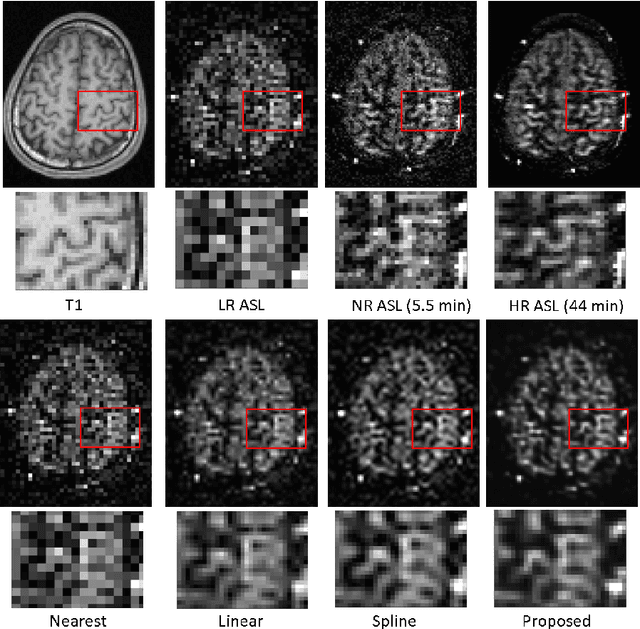
Arterial spin labeling (ASL) magnetic resonance imaging (MRI) is a powerful imaging technology that can measure cerebral blood flow (CBF) quantitatively. However, since only a small portion of blood is labeled compared to the whole tissue volume, conventional ASL suffers from low signal-to-noise ratio (SNR), poor spatial resolution, and long acquisition time. In this paper, we proposed a super-resolution method based on a multi-scale generative adversarial network (GAN) through unsupervised training. The network only needs the low-resolution (LR) ASL image itself for training and the T1-weighted image as the anatomical prior. No training pairs or pre-training are needed. A low-pass filter guided item was added as an additional loss to suppress the noise interference from the LR ASL image. After the network was trained, the super-resolution (SR) image was generated by supplying the upsampled LR ASL image and corresponding T1-weighted image to the generator of the last layer. Performance of the proposed method was evaluated by comparing the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) using normal-resolution (NR) ASL image (5.5 min acquisition) and high-resolution (HR) ASL image (44 min acquisition) as the ground truth. Compared to the nearest, linear, and spline interpolation methods, the proposed method recovers more detailed structure information, reduces the image noise visually, and achieves the highest PSNR and SSIM when using HR ASL image as the ground-truth.