 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines
Apr 15, 2026Generative information retrieval (GenIR) formulates the retrieval process as a text-to-text generation task, leveraging the vast knowledge of large language models. However, existing works primarily optimize for relevance while often overlooking document trustworthiness. This is critical in high-stakes domains like healthcare and finance, where relying solely on semantic relevance risks retrieving unreliable information. To address this, we propose an Authority-aware Generative Retriever (AuthGR), the first framework that incorporates authority into GenIR. AuthGR consists of three key components: (i) Multimodal Authority Scoring, which employs a vision-language model to quantify authority from textual and visual cues; (ii) a Three-stage Training Pipeline to progressively instill authority awareness into the retriever; and (iii) a Hybrid Ensemble Pipeline for robust deployment. Offline evaluations demonstrate that AuthGR successfully enhances both authority and accuracy, with our 3B model matching a 14B baseline. Crucially, large-scale online A/B tests and human evaluations conducted on the commercial web search platform confirm significant improvements in real-world user engagement and reliability.
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

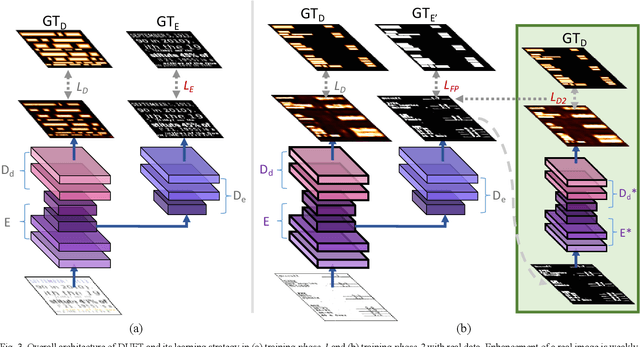

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.