 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Conversational Behavior Reasoning Capabilities in Full-Duplex Speech
Dec 25, 2025



Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this causal pathway is key to building natural full-duplex interactive systems. We introduce a framework that enables reasoning over conversational behaviors by modeling this process as causal inference within a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a hybrid corpus that pairs controllable, event-rich simulations with human-annotated rationales and real conversational speech. The GoT framework structures streaming predictions as an evolving graph, enabling a multimodal transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
RT-VC: Real-Time Zero-Shot Voice Conversion with Speech Articulatory Coding
Jun 12, 2025



Voice conversion has emerged as a pivotal technology in numerous applications ranging from assistive communication to entertainment. In this paper, we present RT-VC, a zero-shot real-time voice conversion system that delivers ultra-low latency and high-quality performance. Our approach leverages an articulatory feature space to naturally disentangle content and speaker characteristics, facilitating more robust and interpretable voice transformations. Additionally, the integration of differentiable digital signal processing (DDSP) enables efficient vocoding directly from articulatory features, significantly reducing conversion latency. Experimental evaluations demonstrate that, while maintaining synthesis quality comparable to the current state-of-the-art (SOTA) method, RT-VC achieves a CPU latency of 61.4 ms, representing a 13.3\% reduction in latency.
A 3D model-based approach for fitting masks to faces in the wild
Mar 01, 2021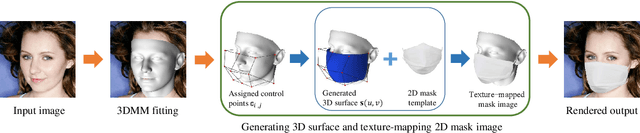
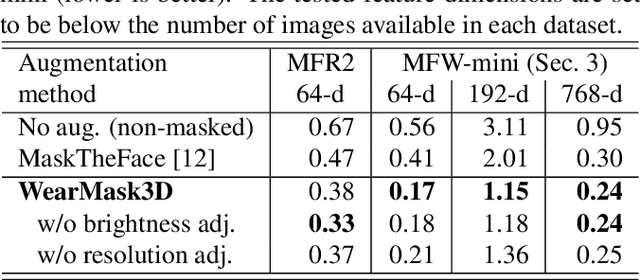

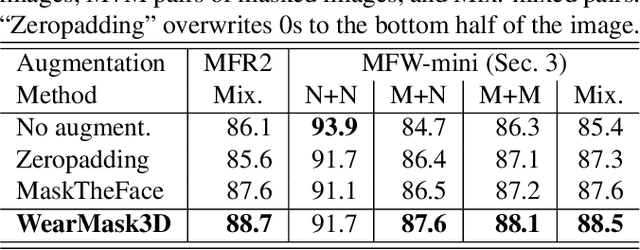
Face recognition research now requires a large number of labelled masked face images in the era of this unprecedented COVID-19 pandemic. Unfortunately, the rapid spread of the virus has left us little time to prepare for such dataset in the wild. To circumvent this issue, we present a 3D model-based approach called WearMask3D for augmenting face images of various poses to the masked face counterparts. Our method proceeds by first fitting a 3D morphable model on the input image, second overlaying the mask surface onto the face model and warping the respective mask texture, and last projecting the 3D mask back to 2D. The mask texture is adapted based on the brightness and resolution of the input image. By working in 3D, our method can produce more natural masked faces of diverse poses from a single mask texture. To compare precisely between different augmentation approaches, we have constructed a dataset comprising masked and unmasked faces with labels called MFW-mini. Experimental results demonstrate WearMask3D, which will be made publicly available, produces more realistic masked images, and utilizing these images for training leads to improved recognition accuracy of masked faces compared to the state-of-the-art.