 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Panoramic Panoptic Segmentation: Towards Complete Surrounding Understanding via Unsupervised Contrastive Learning
Mar 01, 2021
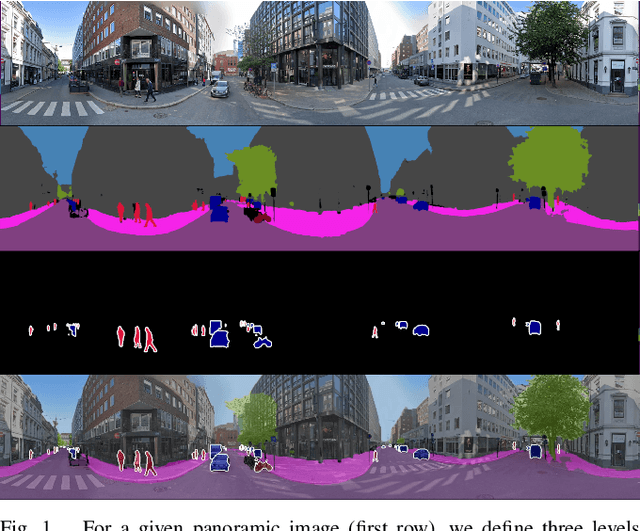
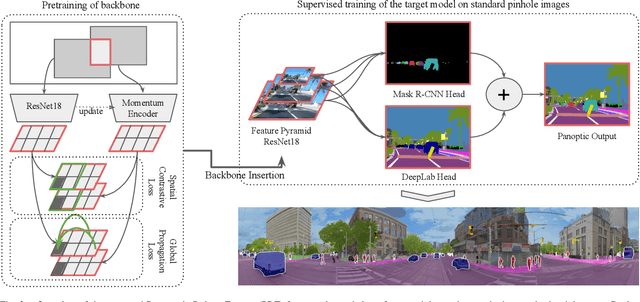

In this work, we introduce panoramic panoptic segmentation as the most holistic scene understanding both in terms of field of view and image level understanding. A complete surrounding understanding provides a maximum of information to the agent, which is essential for any intelligent vehicle in order to make informed decisions in a safety-critical dynamic environment such as real-world traffic. In order to overcome the lack of annotated panoramic images, we propose a framework which allows model training on standard pinhole images and transfers the learned features to a different domain. Using our proposed method, we manage to achieve significant improvements of over 5\% measured in PQ over non-adapted models on our Wild Panoramic Panoptic Segmentation (WildPPS) dataset. We show that our proposed Panoramic Robust Feature (PRF) framework is not only suitable to improve performance on panoramic images but can be beneficial whenever model training and deployment are executed on data taken from different distributions. As an additional contribution, we publish WildPPS: The first panoramic panoptic image dataset to foster progress in surrounding perception.
Chitrakar: Robotic System for Drawing Jordan Curve of Facial Portrait
Nov 21, 2020

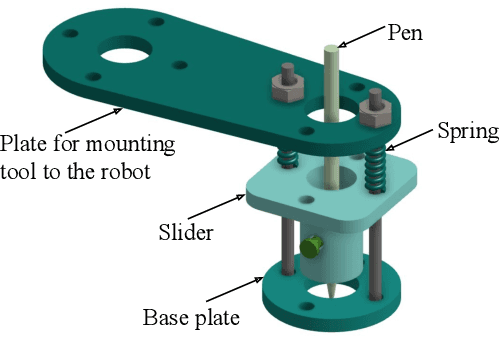
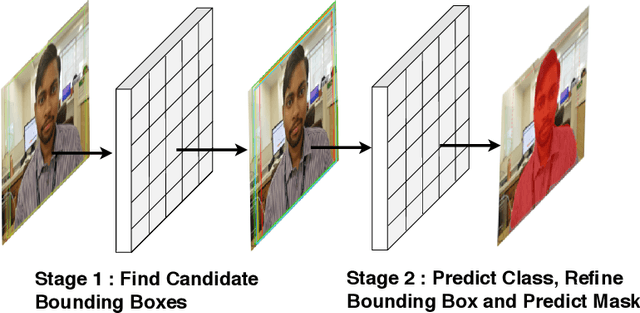
This paper presents a robotic system (\textit{Chitrakar}) which autonomously converts any image of a human face to a recognizable non-self-intersecting loop (Jordan Curve) and draws it on any planar surface. The image is processed using Mask R-CNN for instance segmentation, Laplacian of Gaussian (LoG) for feature enhancement and intensity-based probabilistic stippling for the image to points conversion. These points are treated as a destination for a travelling salesman and are connected with an optimal path which is calculated heuristically by minimizing the total distance to be travelled. This path is converted to a Jordan Curve in feasible time by removing intersections using a combination of image processing, 2-opt, and Bresenham's Algorithm. The robotic system generates $n$ instances of each image for human aesthetic judgement, out of which the most appealing instance is selected for the final drawing. The drawing is executed carefully by the robot's arm using trapezoidal velocity profiles for jerk-free and fast motion. The drawing, with a decent resolution, can be completed in less than 30 minutes which is impossible to do by hand. This work demonstrates the use of robotics to augment humans in executing difficult craft-work instead of replacing them altogether.
Semantic annotation for computational pathology: Multidisciplinary experience and best practice recommendations
Jun 25, 2021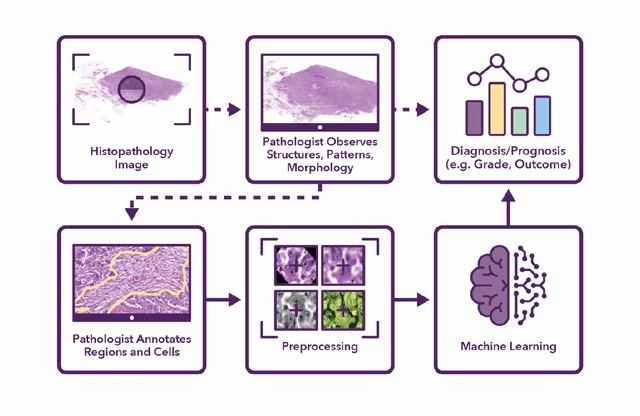

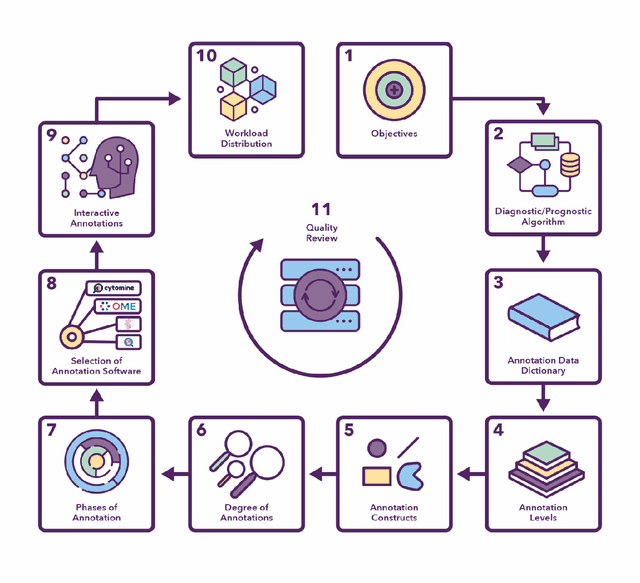
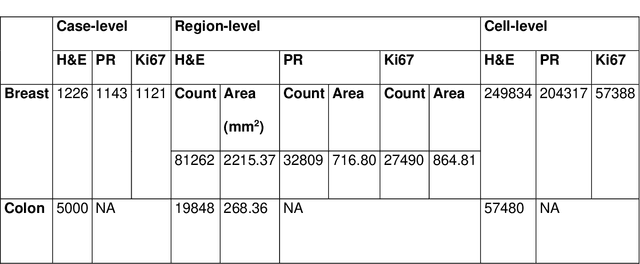
Recent advances in whole slide imaging (WSI) technology have led to the development of a myriad of computer vision and artificial intelligence (AI) based diagnostic, prognostic, and predictive algorithms. Computational Pathology (CPath) offers an integrated solution to utilize information embedded in pathology WSIs beyond what we obtain through visual assessment. For automated analysis of WSIs and validation of machine learning (ML) models, annotations at the slide, tissue and cellular levels are required. The annotation of important visual constructs in pathology images is an important component of CPath projects. Improper annotations can result in algorithms which are hard to interpret and can potentially produce inaccurate and inconsistent results. Despite the crucial role of annotations in CPath projects, there are no well-defined guidelines or best practices on how annotations should be carried out. In this paper, we address this shortcoming by presenting the experience and best practices acquired during the execution of a large-scale annotation exercise involving a multidisciplinary team of pathologists, ML experts and researchers as part of the Pathology image data Lake for Analytics, Knowledge and Education (PathLAKE) consortium. We present a real-world case study along with examples of different types of annotations, diagnostic algorithm, annotation data dictionary and annotation constructs. The analyses reported in this work highlight best practice recommendations that can be used as annotation guidelines over the lifecycle of a CPath project.
Watershed of Artificial Intelligence: Human Intelligence, Machine Intelligence, and Biological Intelligence
May 07, 2021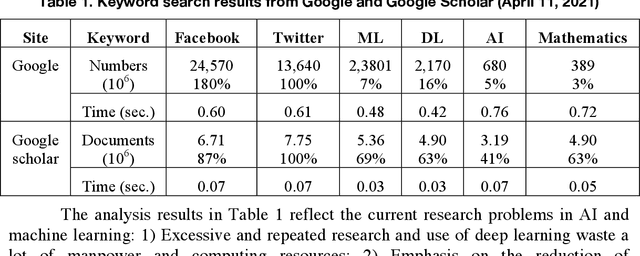
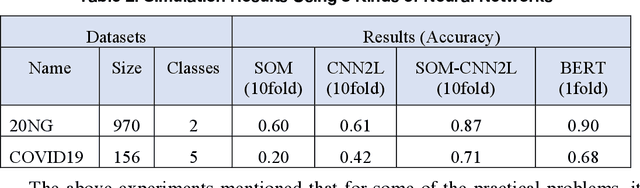
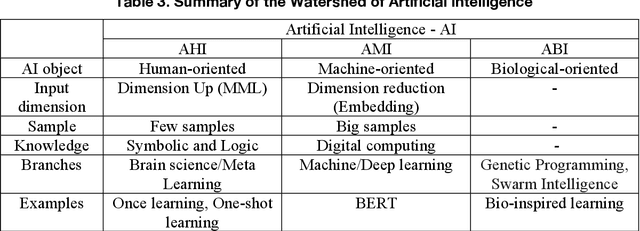
This article reviews the "Once learning" mechanism that was proposed 23 years ago and the subsequent successes of "One-shot learning" in image classification and "You Only Look Once - YOLO" in objective detection. Analyzing the current development of Artificial Intelligence (AI), the proposal is that AI should be clearly divided into the following categories: Artificial Human Intelligence (AHI), Artificial Machine Intelligence (AMI), and Artificial Biological Intelligence (ABI), which will also be the main directions of theory and application development for AI. As a watershed for the branches of AI, some classification standards and methods are discussed: 1) Human-oriented, machine-oriented, and biological-oriented AI R&D; 2) Information input processed by Dimensionality-up or Dimensionality-reduction; 3) The use of one/few or large samples for knowledge learning.
Novelty Detection via Contrastive Learning with Negative Data Augmentation
Jun 18, 2021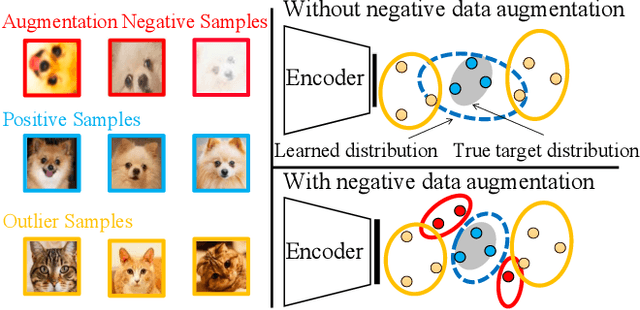

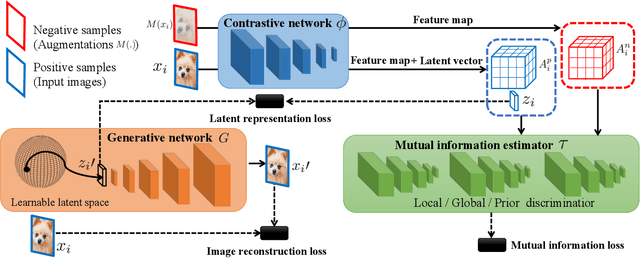
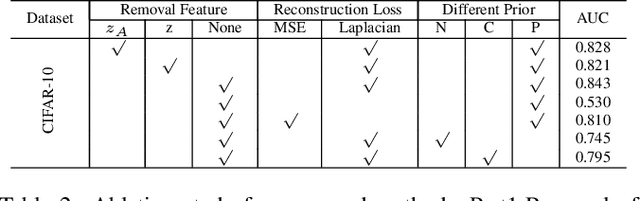
Novelty detection is the process of determining whether a query example differs from the learned training distribution. Previous methods attempt to learn the representation of the normal samples via generative adversarial networks (GANs). However, they will suffer from instability training, mode dropping, and low discriminative ability. Recently, various pretext tasks (e.g. rotation prediction and clustering) have been proposed for self-supervised learning in novelty detection. However, the learned latent features are still low discriminative. We overcome such problems by introducing a novel decoder-encoder framework. Firstly, a generative network (a.k.a. decoder) learns the representation by mapping the initialized latent vector to an image. In particular, this vector is initialized by considering the entire distribution of training data to avoid the problem of mode-dropping. Secondly, a contrastive network (a.k.a. encoder) aims to ``learn to compare'' through mutual information estimation, which directly helps the generative network to obtain a more discriminative representation by using a negative data augmentation strategy. Extensive experiments show that our model has significant superiority over cutting-edge novelty detectors and achieves new state-of-the-art results on some novelty detection benchmarks, e.g. CIFAR10 and DCASE. Moreover, our model is more stable for training in a non-adversarial manner, compared to other adversarial based novelty detection methods.
Self-Supervised Monocular Depth Estimation of Untextured Indoor Rotated Scenes
Jun 25, 2021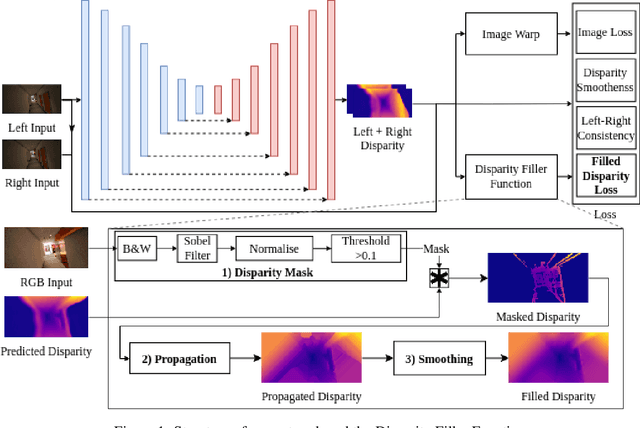

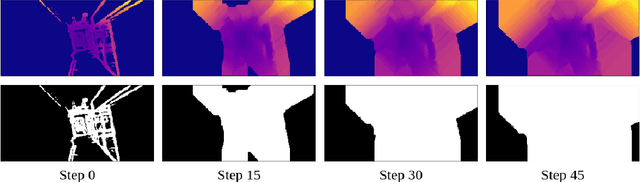
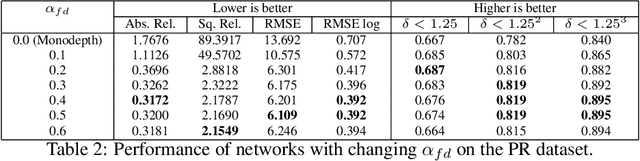
Self-supervised deep learning methods have leveraged stereo images for training monocular depth estimation. Although these methods show strong results on outdoor datasets such as KITTI, they do not match performance of supervised methods on indoor environments with camera rotation. Indoor, rotated scenes are common for less constrained applications and pose problems for two reasons: abundance of low texture regions and increased complexity of depth cues for images under rotation. In an effort to extend self-supervised learning to more generalised environments we propose two additions. First, we propose a novel Filled Disparity Loss term that corrects for ambiguity of image reconstruction error loss in textureless regions. Specifically, we interpolate disparity in untextured regions, using the estimated disparity from surrounding textured areas, and use L1 loss to correct the original estimation. Our experiments show that depth estimation is substantially improved on low-texture scenes, without any loss on textured scenes, when compared to Monodepth by Godard et al. Secondly, we show that training with an application's representative rotations, in both pitch and roll, is sufficient to significantly improve performance over the entire range of expected rotation. We demonstrate that depth estimation is successfully generalised as performance is not lost when evaluated on test sets with no camera rotation. Together these developments enable a broader use of self-supervised learning of monocular depth estimation for complex environments.
Changing the Image Memorability: From Basic Photo Editing to GANs
Nov 15, 2018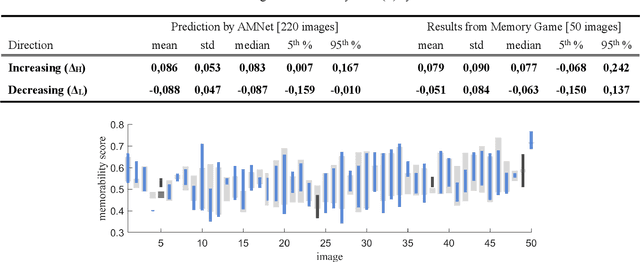

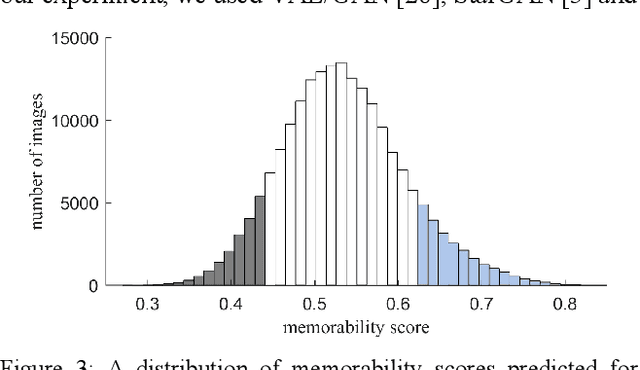
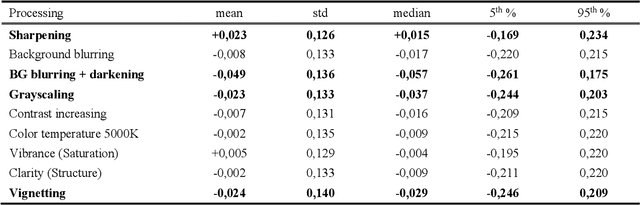
Memorability is considered to be an important characteristic of visual content, whereas for advertisement and educational purposes it is the most important one. Despite numerous studies on understanding and predicting image memorability, there are almost no achievements in memorability modification. In this work, we study two possible approaches to image modification which likely may influence memorability. The visual features which influence memorability directly stay unknown till now, hence it is impossible to control it manually. As a solution, we let GAN learn it deeply using labeled data, and then use it for conditional generation of new images. By analogy with algorithms which edit facial attributes, we consider memorability as yet another attribute and operate with it in the same way. Obtained data is also interesting for analysis, simply because there are no real-world examples of successful change of image memorability while preserving its other attributes. We believe this may give many new answers to the question "what makes an image memorable?" Apart from that we also study the influence of conventional photo-editing tools (Photoshop, Instagram, etc.) used daily by a wide audience on memorability. In this case, we start from real practical methods and study it using statistics and recent advances in memorability prediction. Photographers, designers, and advertisers will benefit from the results of this study directly.
Bi-GANs-ST for Perceptual Image Super-resolution
Nov 01, 2018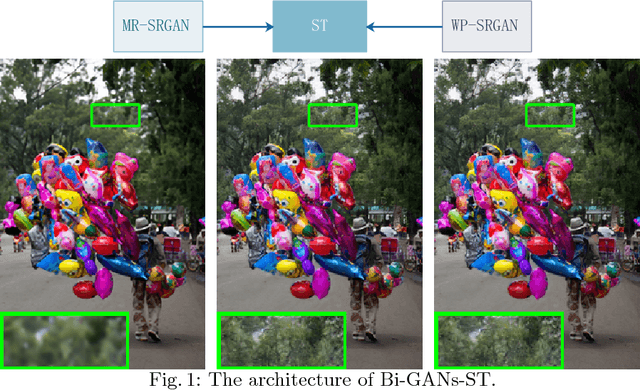
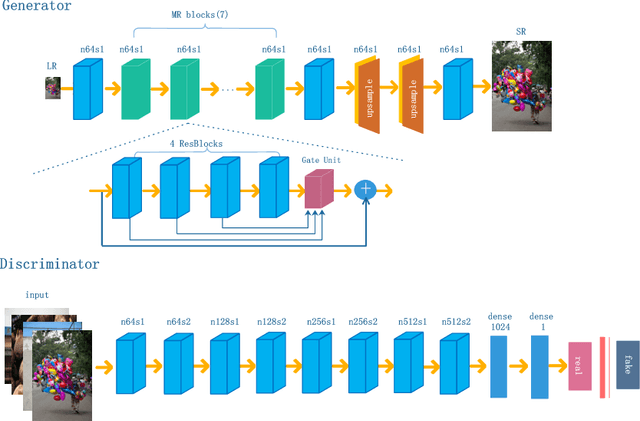
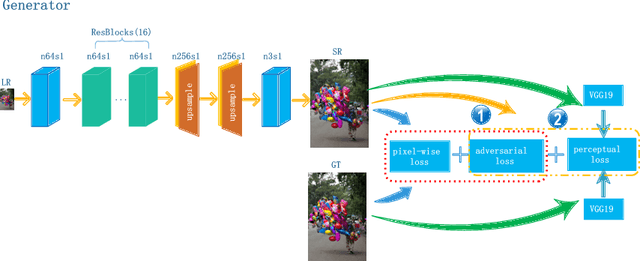
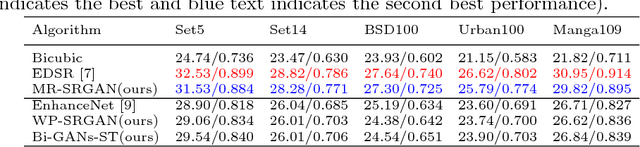
Image quality measurement is a critical problem for image super-resolution (SR) algorithms. Usually, they are evaluated by some well-known objective metrics, e.g., PSNR and SSIM, but these indices cannot provide suitable results in accordance with the perception of human being. Recently, a more reasonable perception measurement has been proposed in [1], which is also adopted by the PIRM-SR 2018 challenge. In this paper, motivated by [1], we aim to generate a high-quality SR result which balances between the two indices, i.e., the perception index and root-mean-square error (RMSE). To do so, we design a new deep SR framework, dubbed Bi-GANs-ST, by integrating two complementary generative adversarial networks (GAN) branches. One is memory residual SRGAN (MR-SRGAN), which emphasizes on improving the objective performance, such as reducing the RMSE. The other is weight perception SRGAN (WP-SRGAN), which obtains the result that favors better subjective perception via a two-stage adversarial training mechanism. Then, to produce final result with excellent perception scores and RMSE, we use soft-thresholding method to merge the results generated by the two GANs. Our method performs well on the perceptual image super-resolution task of the PIRM 2018 challenge. Experimental results on five benchmarks show that our proposal achieves highly competent performance compared with other state-of-the-art methods.
Multiscale Principle of Relevant Information for Hyperspectral Image Classification
Jul 13, 2019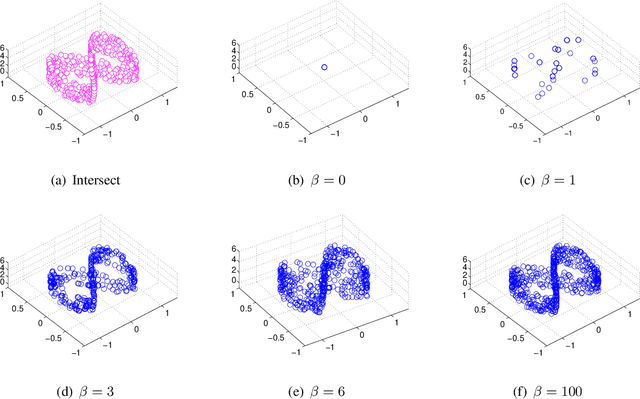
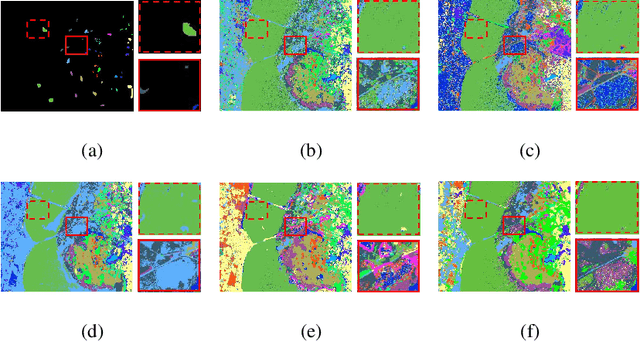
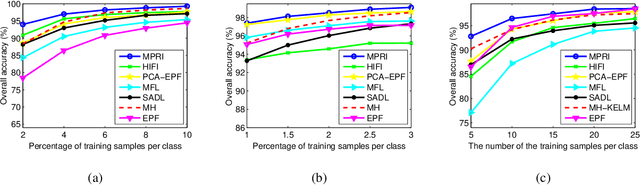
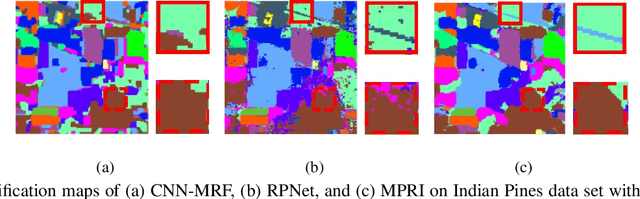
This paper proposes a novel architecture, termed multiscale principle of relevant information (MPRI), to learn discriminative spectral-spatial features for hyperspectral image (HSI) classification. MPRI inherits the merits of the principle of relevant information (PRI) to effectively extract multiscale information embedded in the given data, and also takes advantage of the multilayer structure to learn representations in a coarse-to-fine manner. Specifically, MPRI performs spectral-spatial pixel characterization (using PRI) and feature dimensionality reduction (using regularized linear discriminant analysis) iteratively and successively. Extensive experiments on four benchmark data sets demonstrate that MPRI outperforms existing state-of-the-art HSI classification methods (including deep learning based ones) qualitatively and quantitatively, especially in the scenario of limited training samples.
A non-alternating graph hashing algorithm for large scale image search
Dec 24, 2020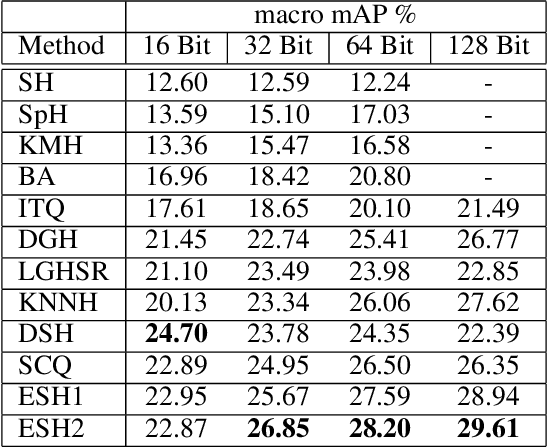
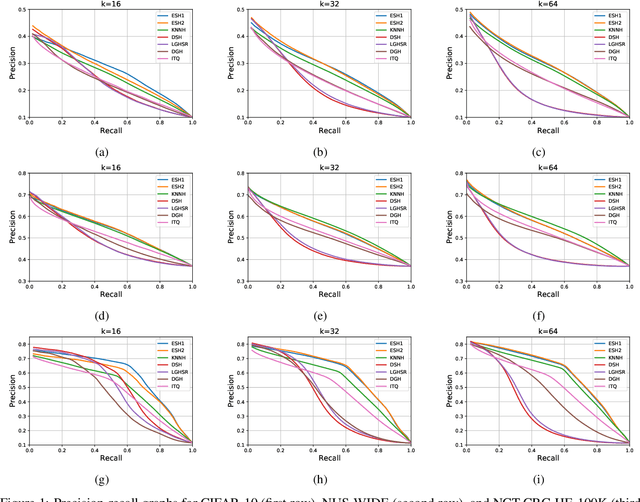
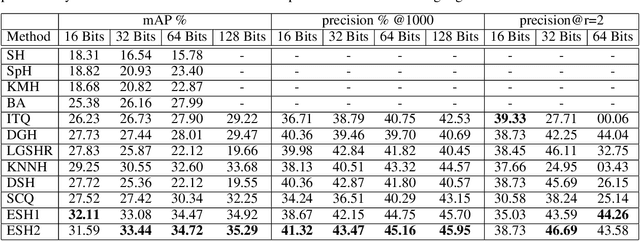
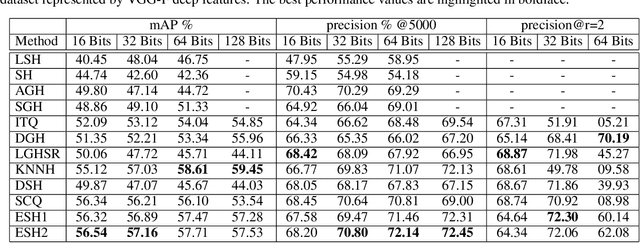
In the era of big data, methods for improving memory and computational efficiency have become crucial for successful deployment of technologies. Hashing is one of the most effective approaches to deal with computational limitations that come with big data. One natural way for formulating this problem is spectral hashing that directly incorporates affinity to learn binary codes. However, due to binary constraints, the optimization becomes intractable. To mitigate this challenge, different relaxation approaches have been proposed to reduce the computational load of obtaining binary codes and still attain a good solution. The problem with all existing relaxation methods is resorting to one or more additional auxiliary variables to attain high quality binary codes while relaxing the problem. The existence of auxiliary variables leads to coordinate descent approach which increases the computational complexity. We argue that introducing these variables is unnecessary. To this end, we propose a novel relaxed formulation for spectral hashing that adds no additional variables to the problem. Furthermore, instead of solving the problem in original space where number of variables is equal to the data points, we solve the problem in a much smaller space and retrieve the binary codes from this solution. This trick reduces both the memory and computational complexity at the same time. We apply two optimization techniques, namely projected gradient and optimization on manifold, to obtain the solution. Using comprehensive experiments on four public datasets, we show that the proposed efficient spectral hashing (ESH) algorithm achieves highly competitive retrieval performance compared with state of the art at low complexity.