 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-BT-Terms: Back-Translation as a Framework for Terminology Standardization and Dynamic Semantic Embedding
Jun 11, 2025The rapid expansion of English technical terminology presents a significant challenge to traditional expert-based standardization, particularly in rapidly developing areas such as artificial intelligence and quantum computing. Manual approaches face difficulties in maintaining consistent multilingual terminology. To address this, we introduce LLM-BT, a back-translation framework powered by large language models (LLMs) designed to automate terminology verification and standardization through cross-lingual semantic alignment. Our key contributions include: (1) term-level consistency validation: by performing English -> intermediate language -> English back-translation, LLM-BT achieves high term consistency across different models (such as GPT-4, DeepSeek, and Grok). Case studies demonstrate over 90 percent of terms are preserved either exactly or semantically; (2) multi-path verification workflow: we develop a novel pipeline described as Retrieve -> Generate -> Verify -> Optimize, which supports both serial paths (e.g., English -> Simplified Chinese -> Traditional Chinese -> English) and parallel paths (e.g., English -> Chinese / Portuguese -> English). BLEU scores and term-level accuracy indicate strong cross-lingual robustness, with BLEU scores exceeding 0.45 and Portuguese term accuracy reaching 100 percent; (3) back-translation as semantic embedding: we reinterpret back-translation as a form of dynamic semantic embedding that uncovers latent trajectories of meaning. In contrast to static embeddings, LLM-BT offers transparent, path-based embeddings shaped by the evolution of the models. This reframing positions back-translation as an active mechanism for multilingual terminology standardization, fostering collaboration between machines and humans - machines preserve semantic integrity, while humans provide cultural interpretation.
The Paradox of Poetic Intent in Back-Translation: Evaluating the Quality of Large Language Models in Chinese Translation
Apr 22, 2025The rapid advancement of large language models (LLMs) has reshaped the landscape of machine translation, yet challenges persist in preserving poetic intent, cultural heritage, and handling specialized terminology in Chinese-English translation. This study constructs a diverse corpus encompassing Chinese scientific terminology, historical translation paradoxes, and literary metaphors. Utilizing a back-translation and Friedman test-based evaluation system (BT-Fried), we evaluate BLEU, CHRF, TER, and semantic similarity metrics across six major LLMs (e.g., GPT-4.5, DeepSeek V3) and three traditional translation tools. Key findings include: (1) Scientific abstracts often benefit from back-translation, while traditional tools outperform LLMs in linguistically distinct texts; (2) LLMs struggle with cultural and literary retention, exemplifying the "paradox of poetic intent"; (3) Some models exhibit "verbatim back-translation", reflecting emergent memory behavior; (4) A novel BLEU variant using Jieba segmentation and n-gram weighting is proposed. The study contributes to the empirical evaluation of Chinese NLP performance and advances understanding of cultural fidelity in AI-mediated translation.
LLMQuoter: Enhancing RAG Capabilities Through Efficient Quote Extraction From Large Contexts
Jan 09, 2025



We introduce LLMQuoter, a lightweight, distillation-based model designed to enhance Retrieval Augmented Generation (RAG) by extracting the most relevant textual evidence for downstream reasoning tasks. Built on the LLaMA-3B architecture and fine-tuned with Low-Rank Adaptation (LoRA) on a 15,000-sample subset of HotpotQA, LLMQuoter adopts a "quote-first-then-answer" strategy, efficiently identifying key quotes before passing curated snippets to reasoning models. This workflow reduces cognitive overhead and outperforms full-context approaches like Retrieval-Augmented Fine-Tuning (RAFT), achieving over 20-point accuracy gains across both small and large language models. By leveraging knowledge distillation from a high-performing teacher model, LLMQuoter achieves competitive results in a resource-efficient fine-tuning setup. It democratizes advanced RAG capabilities, delivering significant performance improvements without requiring extensive model retraining. Our results highlight the potential of distilled quote-based reasoning to streamline complex workflows, offering a scalable and practical solution for researchers and practitioners alike.
SLIM-RAFT: A Novel Fine-Tuning Approach to Improve Cross-Linguistic Performance for Mercosur Common Nomenclature
Aug 07, 2024Natural language processing (NLP) has seen significant advancements with the advent of large language models (LLMs). However, substantial improvements are still needed for languages other than English, especially for specific domains like the applications of Mercosur Common Nomenclature (NCM), a Brazilian Harmonized System (HS). To address this gap, this study uses TeenyTineLLaMA, a foundational Portuguese LLM, as an LLM source to implement the NCM application processing. Additionally, a simplified Retrieval-Augmented Fine-Tuning (RAFT) technique, termed SLIM-RAFT, is proposed for task-specific fine-tuning of LLMs. This approach retains the chain-of-thought (CoT) methodology for prompt development in a more concise and streamlined manner, utilizing brief and focused documents for training. The proposed model demonstrates an efficient and cost-effective alternative for fine-tuning smaller LLMs, significantly outperforming TeenyTineLLaMA and ChatGPT-4 in the same task. Although the research focuses on NCM applications, the methodology can be easily adapted for HS applications worldwide.
A comprehensive review of automatic text summarization techniques: method, data, evaluation and coding
Jan 11, 2023We provide a literature review about Automatic Text Summarization (ATS) systems. We consider a citation-based approach. We start with some popular and well-known papers that we have in hand about each topic we want to cover and we have tracked the "backward citations" (papers that are cited by the set of papers we knew beforehand) and the "forward citations" (newer papers that cite the set of papers we knew beforehand). In order to organize the different methods, we present the diverse approaches to ATS guided by the mechanisms they use to generate a summary. Besides presenting the methods, we also present an extensive review of the datasets available for summarization tasks and the methods used to evaluate the quality of the summaries. Finally, we present an empirical exploration of these methods using the CNN Corpus dataset that provides golden summaries for extractive and abstractive methods.
Watershed of Artificial Intelligence: Human Intelligence, Machine Intelligence, and Biological Intelligence
May 07, 2021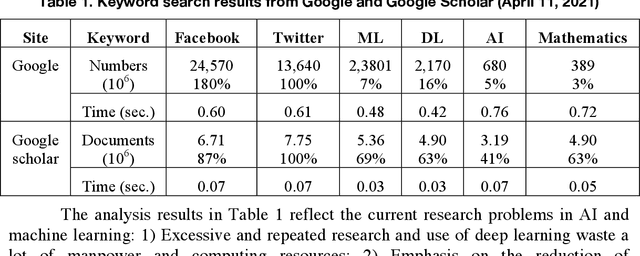
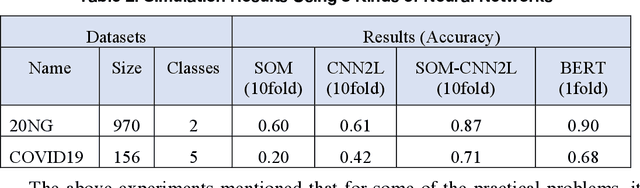
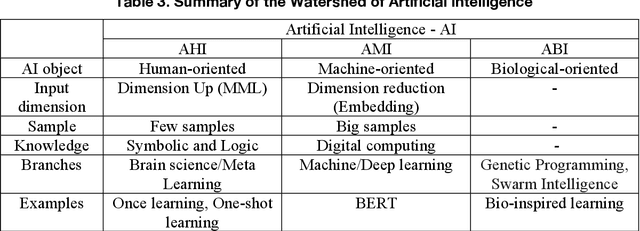
This article reviews the "Once learning" mechanism that was proposed 23 years ago and the subsequent successes of "One-shot learning" in image classification and "You Only Look Once - YOLO" in objective detection. Analyzing the current development of Artificial Intelligence (AI), the proposal is that AI should be clearly divided into the following categories: Artificial Human Intelligence (AHI), Artificial Machine Intelligence (AMI), and Artificial Biological Intelligence (ABI), which will also be the main directions of theory and application development for AI. As a watershed for the branches of AI, some classification standards and methods are discussed: 1) Human-oriented, machine-oriented, and biological-oriented AI R&D; 2) Information input processed by Dimensionality-up or Dimensionality-reduction; 3) The use of one/few or large samples for knowledge learning.
Domain adaptation for holistic skin detection
Mar 16, 2019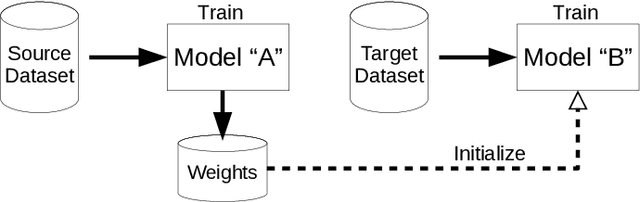
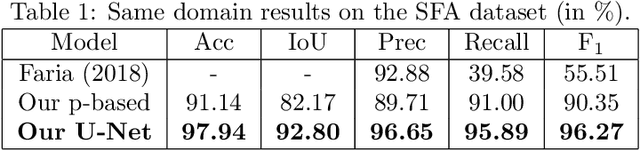
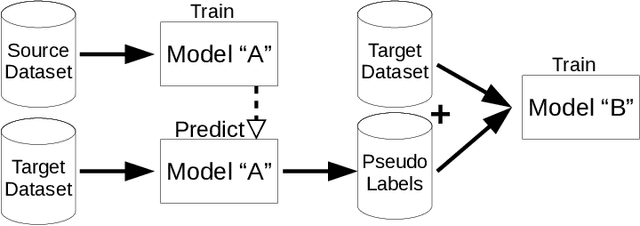
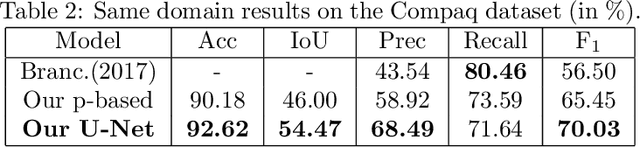
Human skin detection in images is a widely studied topic of Computer Vision for which it is commonly accepted that analysis of pixel color or local patches may suffice. This is because skin regions appear to be relatively uniform and many argue that there is a small chromatic variation among different samples. However, we found that there are strong biases in the datasets commonly used to train or tune skin detection methods. Furthermore, the lack of contextual information may hinder the performance of local approaches. In this paper we present a comprehensive evaluation of holistic and local Convolutional Neural Network (CNN) approaches on in-domain and cross-domain experiments and compare with state-of-the-art pixel-based approaches. We also propose a combination of inductive transfer learning and unsupervised domain adaptation methods, which are evaluated on different domains under several amounts of labelled data availability. We show a clear superiority of CNN over pixel-based approaches even without labelled training samples on the target domain. Furthermore, we provide experimental support for the counter-intuitive superiority of holistic over local approaches for human skin detection.