 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECTR-V2:Unified Relevance-CTR Framework with Cross-User Preference Mining, Exposure Bias Correction, and LLM-Distilled Encoder Optimization
Feb 24, 2026In search systems, effectively coordinating the two core objectives of search relevance matching and click-through rate (CTR) prediction is crucial for discovering users' interests and enhancing platform revenue. In our prior work PRECTR, we proposed a unified framework to integrate these two subtasks,thereby eliminating their inconsistency and leading to mutual benefit.However, our previous work still faces three main challenges. First, low-active users and new users have limited search behavioral data, making it difficult to achieve effective personalized relevance preference modeling. Second, training data for ranking models predominantly come from high-relevance exposures, creating a distribution mismatch with the broader candidate space in coarse-ranking, leading to generalization bias. Third, due to the latency constraint, the original model employs an Emb+MLP architecture with a frozen BERT encoder, which prevents joint optimization and creates misalignment between representation learning and CTR fine-tuning. To solve these issues, we further reinforce our method and propose PRECTR-V2. Specifically, we mitigate the low-activity users' sparse behavior problem by mining global relevance preferences under the specific query, which facilitates effective personalized relevance modeling for cold-start scenarios. Subsequently, we construct hard negative samples through embedding noise injection and relevance label reconstruction, and optimize their relative ranking against positive samples via pairwise loss, thereby correcting exposure bias. Finally, we pretrain a lightweight transformer-based encoder via knowledge distillation from LLM and SFT on the text relevance classification task. This encoder replaces the frozen BERT module, enabling better adaptation to CTR fine-tuning and advancing beyond the traditional Emb+MLP paradigm.
KunServe: Elastic and Efficient Large Language Model Serving with Parameter-centric Memory Management
Dec 24, 2024The stateful nature of large language model (LLM) servingcan easily throttle precious GPU memory under load burstor long-generation requests like chain-of-thought reasoning,causing latency spikes due to queuing incoming requests. However, state-of-the-art KVCache centric approaches handleload spikes by dropping, migrating, or swapping KVCache,which faces an essential tradeoff between the performance ofongoing vs. incoming requests and thus still severely violatesSLO.This paper makes a key observation such that model param-eters are independent of the requests and are replicated acrossGPUs, and thus proposes a parameter-centric approach byselectively dropping replicated parameters to leave preciousmemory for requests. However, LLM requires KVCache tobe saved in bound with model parameters and thus droppingparameters can cause either huge computation waste or longnetwork delay, affecting all ongoing requests. Based on the ob-servation that attention operators can be decoupled from otheroperators, this paper further proposes a novel remote attentionmechanism through pipeline parallelism so as to serve up-coming requests with the additional memory borrowed fromparameters on remote GPUs. This paper further addresses sev-eral other challenges including lively exchanging KVCachewith incomplete parameters, generating an appropriate planthat balances memory requirements with cooperative exe-cution overhead, and seamlessly restoring parameters whenthe throttling has gone. Evaluations show thatKUNSERVEreduces the tail TTFT of requests under throttling by up to 27.3x compared to the state-of-the-art.
ProMoE: Fast MoE-based LLM Serving using Proactive Caching
Oct 29, 2024The promising applications of large language models are often constrained by the limited GPU memory capacity available on edge devices. Mixture-of-Experts (MoE) models help mitigate this issue by activating only a subset of the model's parameters during computation, allowing the unused parameters to be offloaded to host memory and reducing overall GPU memory demand. However, existing cache-based offloading solutions handle cache misses reactively and significantly impact system performance. In this paper, we propose ProMoE, a novel proactive caching system that leverages intermediate model results to predict subsequent parameter usage. By proactively fetching experts in advance, ProMoE removes the loading time from the critical path and diminishes the performance overhead of offloading. Our evaluations demonstrate that ProMoE achieves an average speedup of 2.13x and 2.84x in the prefill and decode stages respectively, compared to existing offloading solutions.
Deep Learning of Dynamic Systems using System Identification Toolbox(TM)
Sep 11, 2024MATLAB(R) releases over the last 3 years have witnessed a continuing growth in the dynamic modeling capabilities offered by the System Identification Toolbox(TM). The emphasis has been on integrating deep learning architectures and training techniques that facilitate the use of deep neural networks as building blocks of nonlinear models. The toolbox offers neural state-space models which can be extended with auto-encoding features that are particularly suited for reduced-order modeling of large systems. The toolbox contains several other enhancements that deepen its integration with the state-of-art machine learning techniques, leverage auto-differentiation features for state estimation, and enable a direct use of raw numeric matrices and timetables for training models.
Characterizing the Dilemma of Performance and Index Size in Billion-Scale Vector Search and Breaking It with Second-Tier Memory
May 07, 2024



Vector searches on large-scale datasets are critical to modern online services like web search and RAG, which necessity storing the datasets and their index on the secondary storage like SSD. In this paper, we are the first to characterize the trade-off of performance and index size in existing SSD-based graph and cluster indexes: to improve throughput by 5.7$\times$ and 1.7$\times$, these indexes have to pay a 5.8$\times$ storage amplification and 7.7$\times$ with respect to the dataset size, respectively. The root cause is that the coarse-grained access of SSD mismatches the fine-grained random read required by vector indexes with small amplification. This paper argues that second-tier memory, such as remote DRAM/NVM connected via RDMA or CXL, is a powerful storage for addressing the problem from a system's perspective, thanks to its fine-grained access granularity. However, putting existing indexes -- primarily designed for SSD -- directly on second-tier memory cannot fully utilize its power. Meanwhile, second-tier memory still behaves more like storage, so using it as DRAM is also inefficient. To this end, we build a graph and cluster index that centers around the performance features of second-tier memory. With careful execution engine and index layout designs, we show that vector indexes can achieve optimal performance with orders of magnitude smaller index amplification, on a variety of second-tier memory devices. Based on our improved graph and vector indexes on second-tier memory, we further conduct a systematic study between them to facilitate developers choosing the right index for their workloads. Interestingly, the findings on the second-tier memory contradict the ones on SSDs.
Cross-target Stance Detection by Exploiting Target Analytical Perspectives
Jan 04, 2024



Cross-target stance detection (CTSD) is an important task, which infers the attitude of the destination target by utilizing annotated data derived from the source target. One important approach in CTSD is to extract domain-invariant features to bridge the knowledge gap between multiple targets. However, the analysis of informal and short text structure, and implicit expressions, complicate the extraction of domain-invariant knowledge. In this paper, we propose a Multi-Perspective Prompt-Tuning (MPPT) model for CTSD that uses the analysis perspective as a bridge to transfer knowledge. First, we develop a two-stage instruct-based chain-of-thought method (TsCoT) to elicit target analysis perspectives and provide natural language explanations (NLEs) from multiple viewpoints by formulating instructions based on large language model (LLM). Second, we propose a multi-perspective prompt-tuning framework (MultiPLN) to fuse the NLEs into the stance predictor. Extensive experiments results demonstrate the superiority of MPPT against the state-of-the-art baseline methods.
LSCD: A Large-Scale Screen Content Dataset for Video Compression
Aug 18, 2023Multimedia compression allows us to watch videos, see pictures and hear sounds within a limited bandwidth, which helps the flourish of the internet. During the past decades, multimedia compression has achieved great success using hand-craft features and systems. With the development of artificial intelligence and video compression, there emerges a lot of research work related to using the neural network on the video compression task to get rid of the complicated system. Not only producing the advanced algorithms, but researchers also spread the compression to different content, such as User Generated Content(UGC). With the rapid development of mobile devices, screen content videos become an important part of multimedia data. In contrast, we find community lacks a large-scale dataset for screen content video compression, which impedes the fast development of the corresponding learning-based algorithms. In order to fulfill this blank and accelerate the research of this special type of videos, we propose the Large-scale Screen Content Dataset(LSCD), which contains 714 source sequences. Meanwhile, we provide the analysis of the proposed dataset to show some features of screen content videos, which will help researchers have a better understanding of how to explore new algorithms. Besides collecting and post-processing the data to organize the dataset, we also provide a benchmark containing the performance of both traditional codec and learning-based methods.
Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021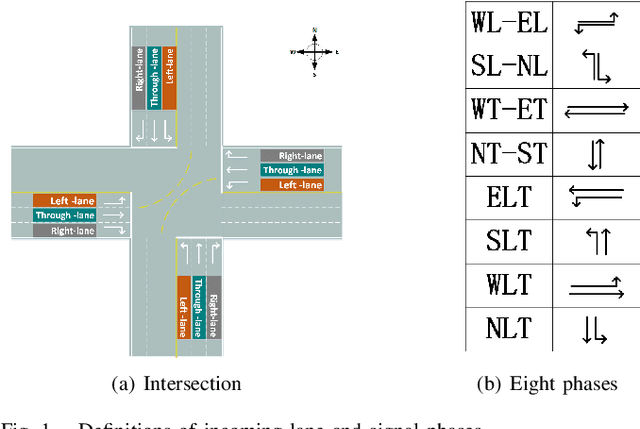

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.
Distributed Learning with Low Communication Cost via Gradient Boosting Untrained Neural Network
Nov 10, 2020
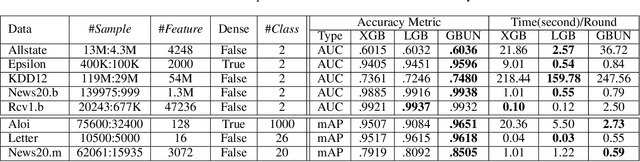
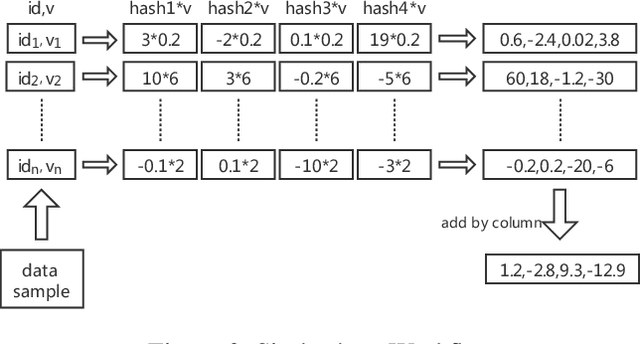
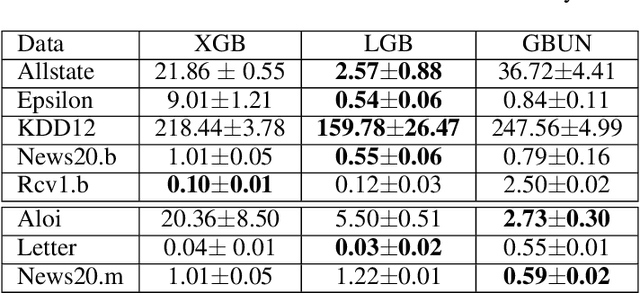
For high-dimensional data, there are huge communication costs for distributed GBDT because the communication volume of GBDT is related to the number of features. To overcome this problem, we propose a novel gradient boosting algorithm, the Gradient Boosting Untrained Neural Network(GBUN). GBUN ensembles the untrained randomly generated neural network that softly distributes data samples to multiple neuron outputs and dramatically reduces the communication costs for distributed learning. To avoid creating huge neural networks for high-dimensional data, we extend Simhash algorithm to mimic forward calculation of the neural network. Our experiments on multiple public datasets show that GBUN is as good as conventional GBDT in terms of prediction accuracy and much better than it in scaling property for distributed learning. Comparing to conventional GBDT varieties, GBUN speeds up the training process up to 13 times on the cluster with 64 machines, and up to 4614 times on the cluster with 100KB/s network bandwidth. Therefore, GBUN is not only an efficient distributed learning algorithm but also has great potentials for federated learning.
Multi-Task Learning Enhanced Single Image De-Raining
Mar 21, 2020
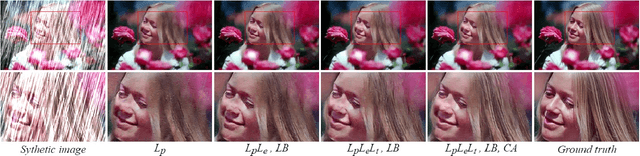


Rain removal in images is an important task in computer vision filed and attracting attentions of more and more people. In this paper, we address a non-trivial issue of removing visual effect of rain streak from a single image. Differing from existing work, our method combines various semantic constraint task in a proposed multi-task regression model for rain removal. These tasks reinforce the model's capabilities from the content, edge-aware, and local texture similarity respectively. To further improve the performance of multi-task learning, we also present two simple but powerful dynamic weighting algorithms. The proposed multi-task enhanced network (MENET) is a powerful convolutional neural network based on U-Net for rain removal research, with a specific focus on utilize multiple tasks constraints and exploit the synergy among them to facilitate the model's rain removal capacity. It is noteworthy that the adaptive weighting scheme has further resulted in improved network capability. We conduct several experiments on synthetic and real rain images, and achieve superior rain removal performance over several selected state-of-the-art (SOTA) approaches. The overall effect of our method is impressive, even in the decomposition of heavy rain and rain streak accumulation.The source code and some results can be found at:https://github.com/SumiHui/MENET.