 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPath: Multimodal Pathology Report Generation from Whole Slide Images
Dec 10, 2025Automated generation of diagnostic pathology reports directly from whole slide images (WSIs) is an emerging direction in computational pathology. Translating high-resolution tissue patterns into clinically coherent text remains difficult due to large morphological variability and the complex structure of pathology narratives. We introduce MPath, a lightweight multimodal framework that conditions a pretrained biomedical language model (BioBART) on WSI-derived visual embeddings through a learned visual-prefix prompting mechanism. Instead of end-to-end vision-language pretraining, MPath leverages foundation-model WSI features (CONCH + Titan) and injects them into BioBART via a compact projection module, keeping the language backbone frozen for stability and data efficiency. MPath was developed and evaluated on the RED 2025 Grand Challenge dataset and ranked 4th in Test Phase 2, despite limited submission opportunities. The results highlight the potential of prompt-based multimodal conditioning as a scalable and interpretable strategy for pathology report generation.
A Deep Learning Framework for Thyroid Nodule Segmentation and Malignancy Classification from Ultrasound Images
Nov 14, 2025



Ultrasound-based risk stratification of thyroid nodules is a critical clinical task, but it suffers from high inter-observer variability. While many deep learning (DL) models function as "black boxes," we propose a fully automated, two-stage framework for interpretable malignancy prediction. Our method achieves interpretability by forcing the model to focus only on clinically relevant regions. First, a TransUNet model automatically segments the thyroid nodule. The resulting mask is then used to create a region of interest around the nodule, and this localised image is fed directly into a ResNet-18 classifier. We evaluated our framework using 5-fold cross-validation on a clinical dataset of 349 images, where it achieved a high F1-score of 0.852 for predicting malignancy. To validate its performance, we compared it against a strong baseline using a Random Forest classifier with hand-crafted morphological features, which achieved an F1-score of 0.829. The superior performance of our DL framework suggests that the implicit visual features learned from the localised nodule are more predictive than explicit shape features alone. This is the first fully automated end-to-end pipeline for both detecting thyroid nodules on ultrasound images and predicting their malignancy.
Synergy vs. Noise: Performance-Guided Multimodal Fusion For Biochemical Recurrence-Free Survival in Prostate Cancer
Nov 14, 2025



Multimodal deep learning (MDL) has emerged as a transformative approach in computational pathology. By integrating complementary information from multiple data sources, MDL models have demonstrated superior predictive performance across diverse clinical tasks compared to unimodal models. However, the assumption that combining modalities inherently improves performance remains largely unexamined. We hypothesise that multimodal gains depend critically on the predictive quality of individual modalities, and that integrating weak modalities may introduce noise rather than complementary information. We test this hypothesis on a prostate cancer dataset with histopathology, radiology, and clinical data to predict time-to-biochemical recurrence. Our results confirm that combining high-performing modalities yield superior performance compared to unimodal approaches. However, integrating a poor-performing modality with other higher-performing modalities degrades predictive accuracy. These findings demonstrate that multimodal benefit requires selective, performance-guided integration rather than indiscriminate modality combination, with implications for MDL design across computational pathology and medical imaging.
MultiSurv: A Multimodal Deep Survival Framework for Prostrate and Bladder Cancer
Sep 05, 2025Accurate prediction of time-to-event outcomes is a central challenge in oncology, with significant implications for treatment planning and patient management. In this work, we present MultiSurv, a multimodal deep survival model utilising DeepHit with a projection layer and inter-modality cross-attention, which integrates heterogeneous patient data, including clinical, MRI, RNA-seq and whole-slide pathology features. The model is designed to capture complementary prognostic signals across modalities and estimate individualised time-to-biochemical recurrence in prostate cancer and time-to-cancer recurrence in bladder cancer. Our approach was evaluated in the context of the CHIMERA Grand Challenge, across two of the three provided tasks. For Task 1 (prostate cancer bio-chemical recurrence prediction), the proposed framework achieved a concordance index (C-index) of 0.843 on 5-folds cross-validation and 0.818 on CHIMERA development set, demonstrating robust discriminatory ability. For Task 3 (bladder cancer recurrence prediction), the model obtained a C-index of 0.662 on 5-folds cross-validation and 0.457 on development set, highlighting its adaptability and potential for clinical translation. These results suggest that leveraging multimodal integration with deep survival learning provides a promising pathway toward personalised risk stratification in prostate and bladder cancer. Beyond the challenge setting, our framework is broadly applicable to survival prediction tasks involving heterogeneous biomedical data.
Lizard: A Large-Scale Dataset for Colonic Nuclear Instance Segmentation and Classification
Aug 25, 2021
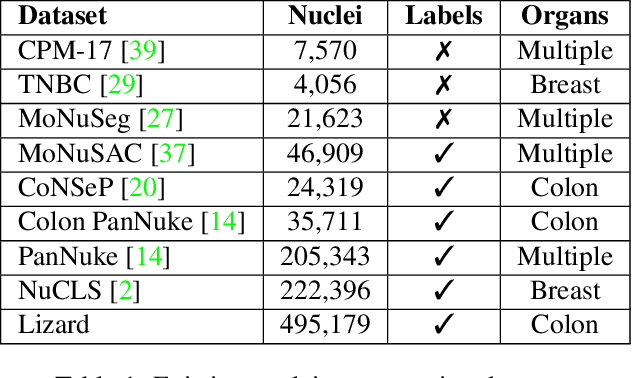
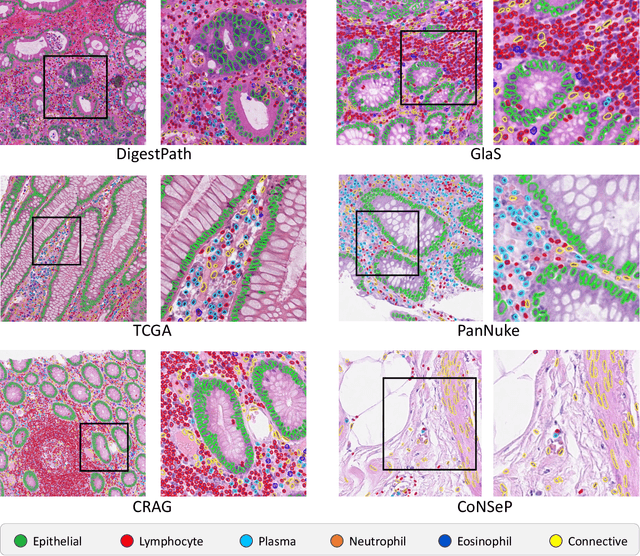
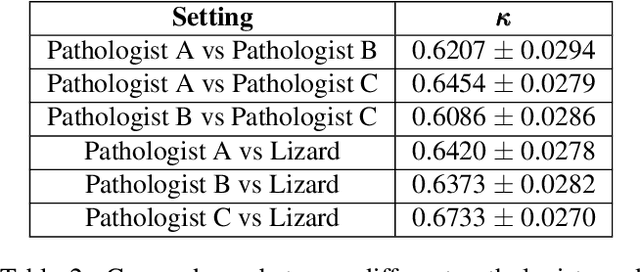
The development of deep segmentation models for computational pathology (CPath) can help foster the investigation of interpretable morphological biomarkers. Yet, there is a major bottleneck in the success of such approaches because supervised deep learning models require an abundance of accurately labelled data. This issue is exacerbated in the field of CPath because the generation of detailed annotations usually demands the input of a pathologist to be able to distinguish between different tissue constructs and nuclei. Manually labelling nuclei may not be a feasible approach for collecting large-scale annotated datasets, especially when a single image region can contain thousands of different cells. However, solely relying on automatic generation of annotations will limit the accuracy and reliability of ground truth. Therefore, to help overcome the above challenges, we propose a multi-stage annotation pipeline to enable the collection of large-scale datasets for histology image analysis, with pathologist-in-the-loop refinement steps. Using this pipeline, we generate the largest known nuclear instance segmentation and classification dataset, containing nearly half a million labelled nuclei in H&E stained colon tissue. We have released the dataset and encourage the research community to utilise it to drive forward the development of downstream cell-based models in CPath.
Semantic annotation for computational pathology: Multidisciplinary experience and best practice recommendations
Jun 25, 2021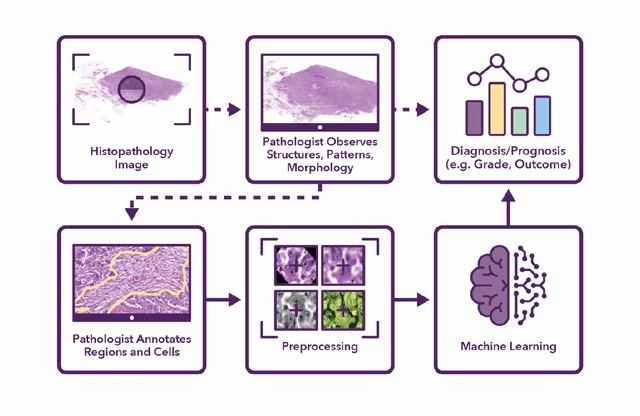

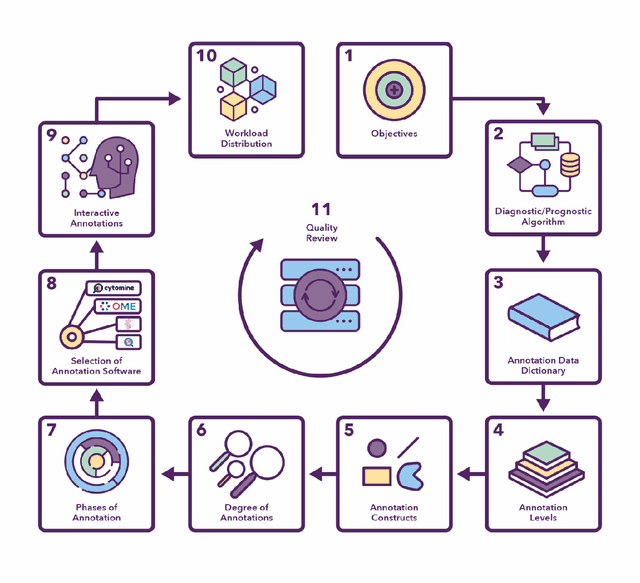
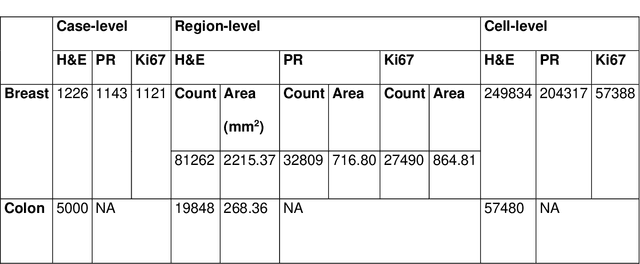
Recent advances in whole slide imaging (WSI) technology have led to the development of a myriad of computer vision and artificial intelligence (AI) based diagnostic, prognostic, and predictive algorithms. Computational Pathology (CPath) offers an integrated solution to utilize information embedded in pathology WSIs beyond what we obtain through visual assessment. For automated analysis of WSIs and validation of machine learning (ML) models, annotations at the slide, tissue and cellular levels are required. The annotation of important visual constructs in pathology images is an important component of CPath projects. Improper annotations can result in algorithms which are hard to interpret and can potentially produce inaccurate and inconsistent results. Despite the crucial role of annotations in CPath projects, there are no well-defined guidelines or best practices on how annotations should be carried out. In this paper, we address this shortcoming by presenting the experience and best practices acquired during the execution of a large-scale annotation exercise involving a multidisciplinary team of pathologists, ML experts and researchers as part of the Pathology image data Lake for Analytics, Knowledge and Education (PathLAKE) consortium. We present a real-world case study along with examples of different types of annotations, diagnostic algorithm, annotation data dictionary and annotation constructs. The analyses reported in this work highlight best practice recommendations that can be used as annotation guidelines over the lifecycle of a CPath project.