 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Continual Learning Framework for Multivariate Time Series Prediction Tasks with Application to Vehicle State Estimation
Mar 03, 2025In continual time series analysis using neural networks, catastrophic forgetting (CF) of previously learned models when training on new data domains has always been a significant challenge. This problem is especially challenging in vehicle estimation and control, where new information is sequentially introduced to the model. Unfortunately, existing work on continual learning has not sufficiently addressed the adverse effects of catastrophic forgetting in time series analysis, particularly in multivariate output environments. In this paper, we present EM-ReSeleCT (Efficient Multivariate Representative Selection for Continual Learning in Time Series Tasks), an enhanced approach designed to handle continual learning in multivariate environments. Our approach strategically selects representative subsets from old and historical data and incorporates memory-based continual learning techniques with an improved optimization algorithm to adapt the pre-trained model on new information while preserving previously acquired information. Additionally, we develop a sequence-to-sequence transformer model (autoregressive model) specifically designed for vehicle state estimation. Moreover, we propose an uncertainty quantification framework using conformal prediction to assess the sensitivity of the memory size and to showcase the robustness of the proposed method. Experimental results from tests on an electric Equinox vehicle highlight the superiority of our method in continually learning new information while retaining prior knowledge, outperforming state-of-the-art continual learning methods. Furthermore, EM-ReSeleCT significantly reduces training time, a critical advantage in continual learning applications.
A non-alternating graph hashing algorithm for large scale image search
Dec 24, 2020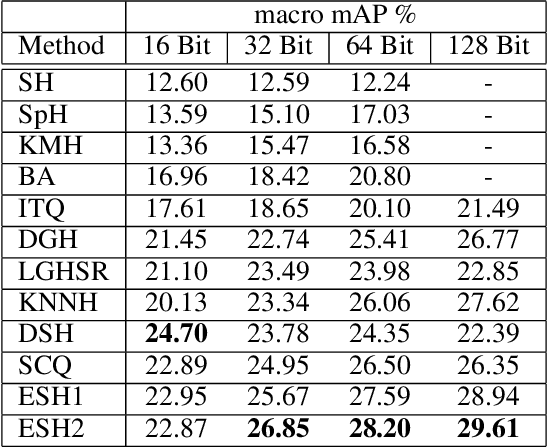
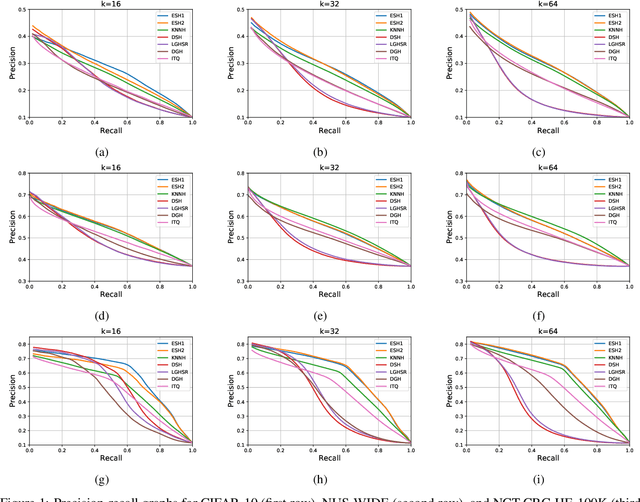
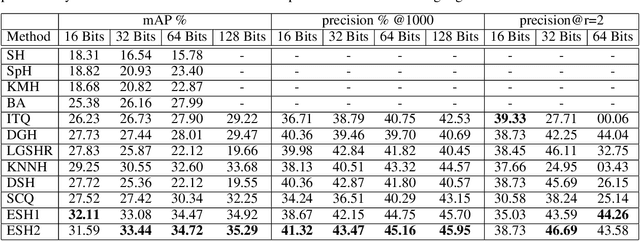
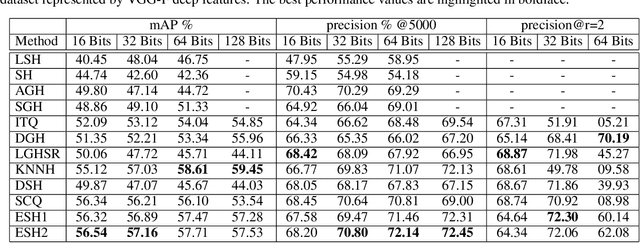
In the era of big data, methods for improving memory and computational efficiency have become crucial for successful deployment of technologies. Hashing is one of the most effective approaches to deal with computational limitations that come with big data. One natural way for formulating this problem is spectral hashing that directly incorporates affinity to learn binary codes. However, due to binary constraints, the optimization becomes intractable. To mitigate this challenge, different relaxation approaches have been proposed to reduce the computational load of obtaining binary codes and still attain a good solution. The problem with all existing relaxation methods is resorting to one or more additional auxiliary variables to attain high quality binary codes while relaxing the problem. The existence of auxiliary variables leads to coordinate descent approach which increases the computational complexity. We argue that introducing these variables is unnecessary. To this end, we propose a novel relaxed formulation for spectral hashing that adds no additional variables to the problem. Furthermore, instead of solving the problem in original space where number of variables is equal to the data points, we solve the problem in a much smaller space and retrieve the binary codes from this solution. This trick reduces both the memory and computational complexity at the same time. We apply two optimization techniques, namely projected gradient and optimization on manifold, to obtain the solution. Using comprehensive experiments on four public datasets, we show that the proposed efficient spectral hashing (ESH) algorithm achieves highly competitive retrieval performance compared with state of the art at low complexity.
A New Method for Performance Analysis in Nonlinear Dimensionality Reduction
Nov 16, 2017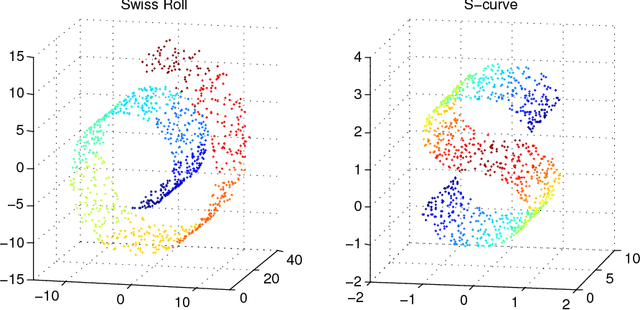
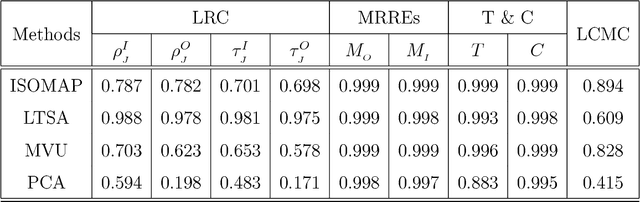
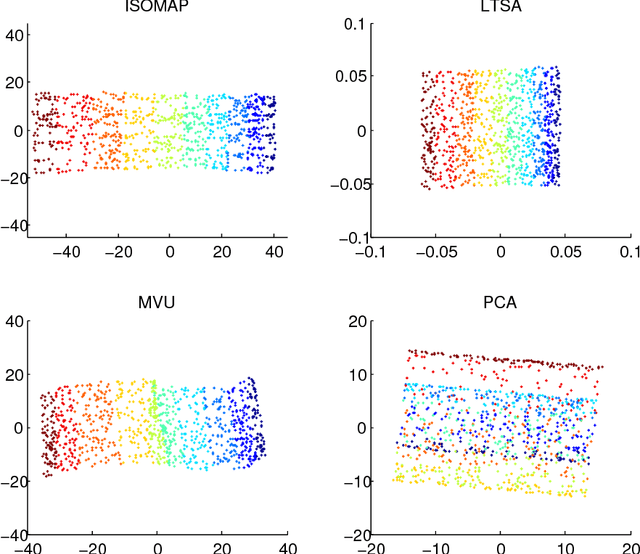
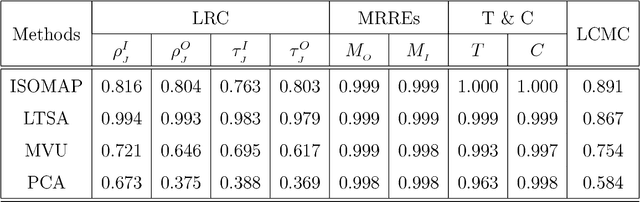
In this paper, we develop a local rank correlation measure which quantifies the performance of dimension reduction methods. The local rank correlation is easily interpretable, and robust against the extreme skewness of nearest neighbor distributions in high dimensions. Some benchmark datasets are studied. We find that the local rank correlation closely corresponds to our visual interpretation of the quality of the output. In addition, we demonstrate that the local rank correlation is useful in estimating the intrinsic dimensionality of the original data, and in selecting a suitable value of tuning parameters used in some algorithms.