 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transferable Adversarial Attacks for Image and Video Object Detection
Dec 13, 2018

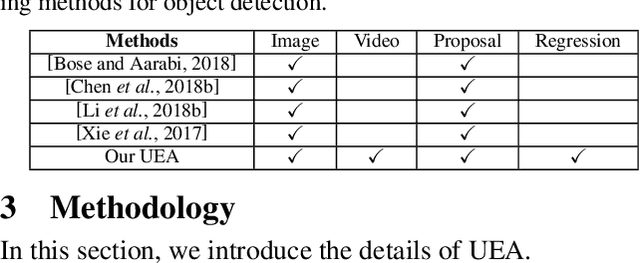
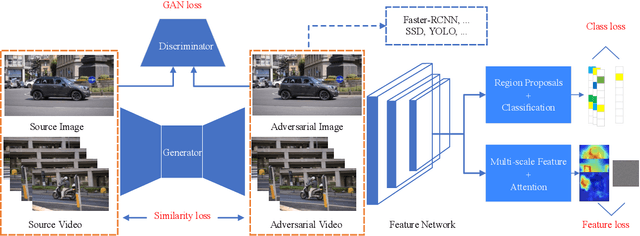
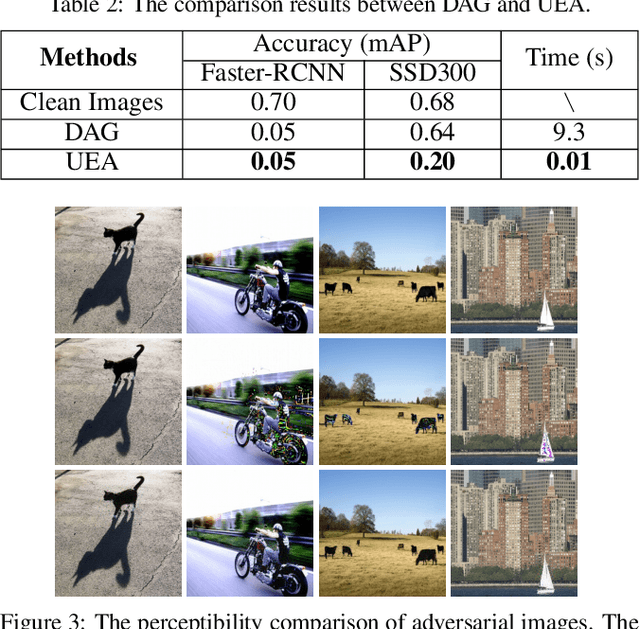
Adversarial examples have been demonstrated to threaten many computer vision tasks including object detection. However, the existing attacking methods for object detection have two limitations: poor transferability, which denotes that the generated adversarial examples have low success rate to attack other kinds of detection methods, and high computation cost, which means that they need more time to generate an adversarial image, and therefore are difficult to deal with the video data. To address these issues, we utilize a generative mechanism to obtain the adversarial image and video. In this way, the processing time is reduced. To enhance the transferability, we destroy the feature maps extracted from the feature network, which usually constitutes the basis of object detectors. The proposed method is based on the Generative Adversarial Network (GAN) framework, where we combine the high-level class loss and low-level feature loss to jointly train the adversarial example generator. A series of experiments conducted on PASCAL VOC and ImageNet VID datasets show that our method can efficiently generate image and video adversarial examples, and more importantly, these adversarial examples have better transferability, and thus, are able to simultaneously attack two kinds of representative object detection models: proposal based models like Faster-RCNN, and regression based models like SSD.
Practical Assessment of Generalization Performance Robustness for Deep Networks via Contrastive Examples
Jun 20, 2021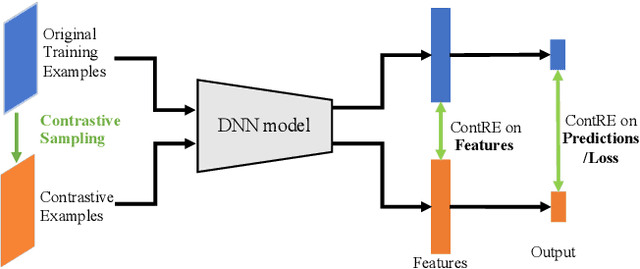
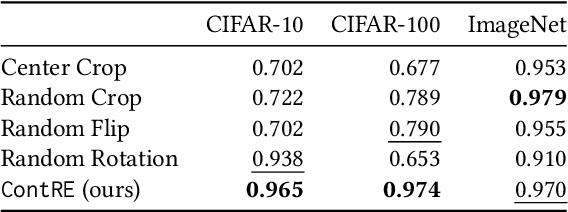
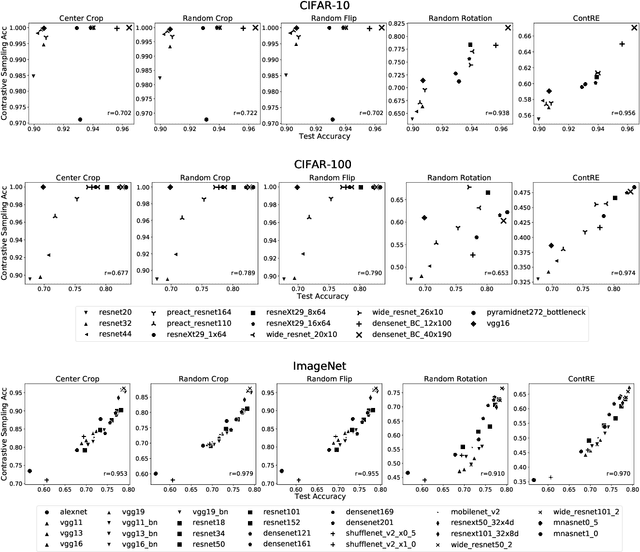
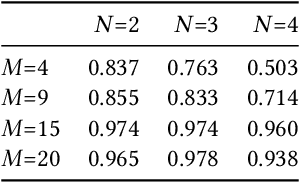
Training images with data transformations have been suggested as contrastive examples to complement the testing set for generalization performance evaluation of deep neural networks (DNNs). In this work, we propose a practical framework ContRE (The word "contre" means "against" or "versus" in French.) that uses Contrastive examples for DNN geneRalization performance Estimation. Specifically, ContRE follows the assumption in contrastive learning that robust DNN models with good generalization performance are capable of extracting a consistent set of features and making consistent predictions from the same image under varying data transformations. Incorporating with a set of randomized strategies for well-designed data transformations over the training set, ContRE adopts classification errors and Fisher ratios on the generated contrastive examples to assess and analyze the generalization performance of deep models in complement with a testing set. To show the effectiveness and the efficiency of ContRE, extensive experiments have been done using various DNN models on three open source benchmark datasets with thorough ablation studies and applicability analyses. Our experiment results confirm that (1) behaviors of deep models on contrastive examples are strongly correlated to what on the testing set, and (2) ContRE is a robust measure of generalization performance complementing to the testing set in various settings.
SIFT Matching by Context Exposed
Jun 20, 2021
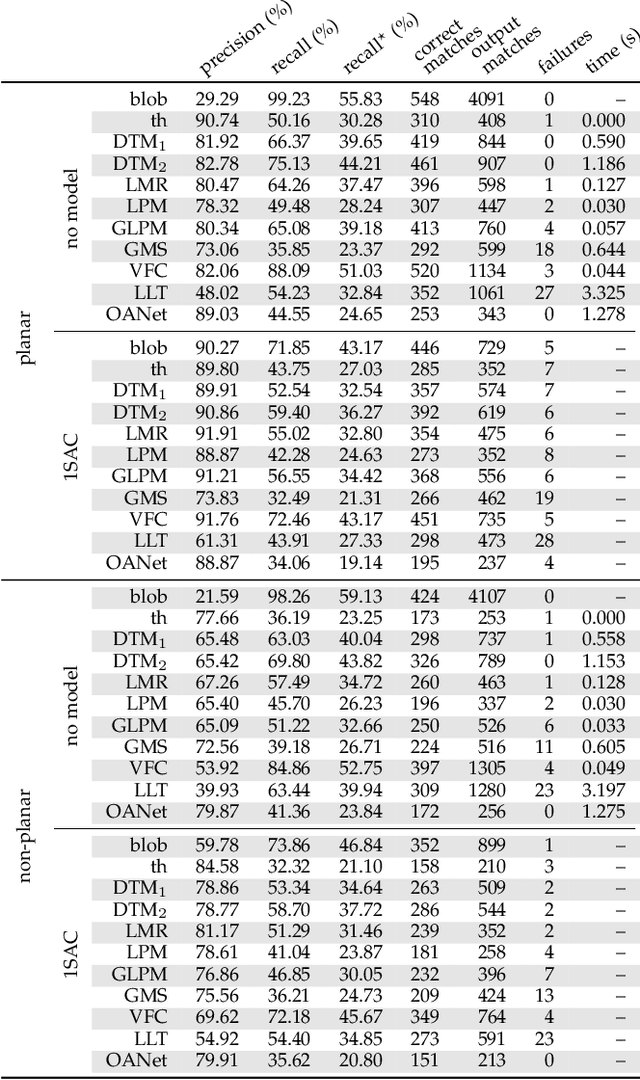
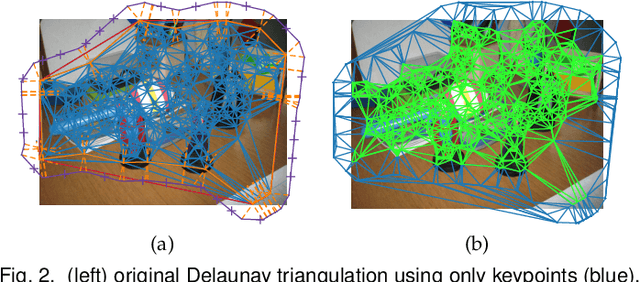
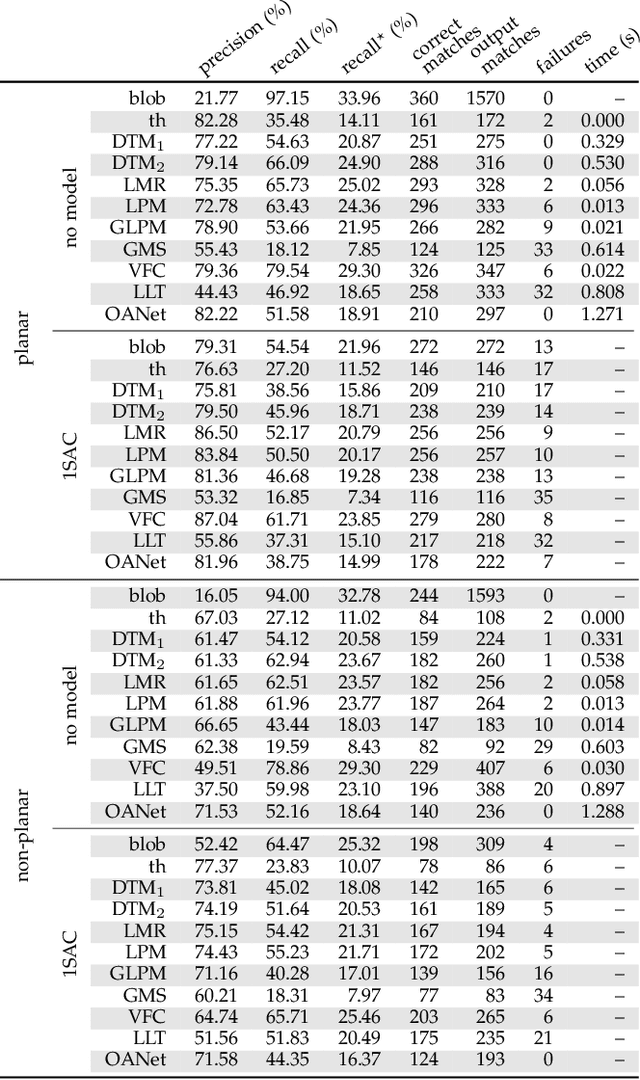
This paper investigates how to step up local image descriptor matching by exploiting matching context information. Two main contexts are identified, originated respectively from the descriptor space and from the keypoint space. The former is generally used to design the actual matching strategy while the latter to filter matches according to the local spatial consistency. On this basis, a new matching strategy and a novel local spatial filter, named respectively blob matching and Delaunay Triangulation Matching (DTM) are devised. Blob matching provides a general matching framework by merging together several strategies, including pre-filtering as well as many-to-many and symmetric matching, enabling to achieve a global improvement upon each individual strategy. DTM alternates between Delaunay triangulation contractions and expansions to figure out and adjust keypoint neighborhood consistency. Experimental evaluation shows that DTM is comparable or better than the state-of-the-art in terms of matching accuracy and robustness, especially for non-planar scenes. Evaluation is carried out according to a new benchmark devised for analyzing the matching pipeline in terms of correct correspondences on both planar and non-planar scenes, including state-of-the-art methods as well as the common SIFT matching approach for reference. This evaluation can be of assistance for future research in this field.
Cycle-Consistent Generative Rendering for 2D-3D Modality Translation
Nov 16, 2020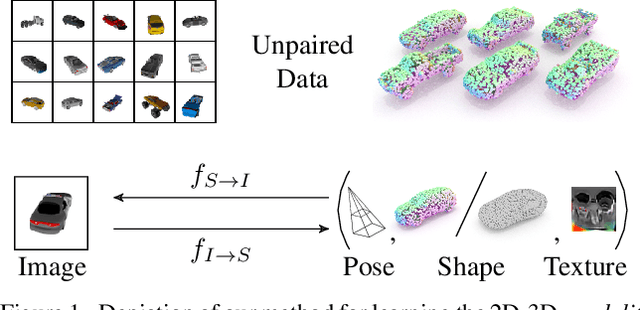
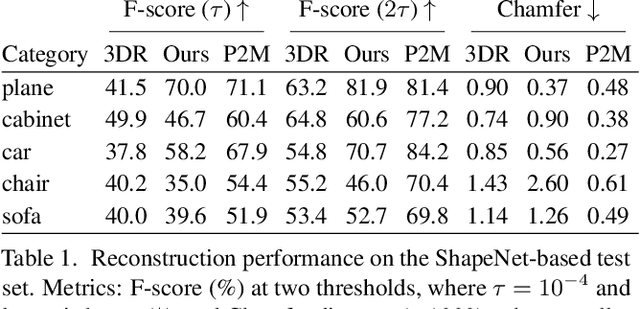

For humans, visual understanding is inherently generative: given a 3D shape, we can postulate how it would look in the world; given a 2D image, we can infer the 3D structure that likely gave rise to it. We can thus translate between the 2D visual and 3D structural modalities of a given object. In the context of computer vision, this corresponds to a learnable module that serves two purposes: (i) generate a realistic rendering of a 3D object (shape-to-image translation) and (ii) infer a realistic 3D shape from an image (image-to-shape translation). In this paper, we learn such a module while being conscious of the difficulties in obtaining large paired 2D-3D datasets. By leveraging generative domain translation methods, we are able to define a learning algorithm that requires only weak supervision, with unpaired data. The resulting model is not only able to perform 3D shape, pose, and texture inference from 2D images, but can also generate novel textured 3D shapes and renders, similar to a graphics pipeline. More specifically, our method (i) infers an explicit 3D mesh representation, (ii) utilizes example shapes to regularize inference, (iii) requires only an image mask (no keypoints or camera extrinsics), and (iv) has generative capabilities. While prior work explores subsets of these properties, their combination is novel. We demonstrate the utility of our learned representation, as well as its performance on image generation and unpaired 3D shape inference tasks.
Stochastic Whitening Batch Normalization
Jun 03, 2021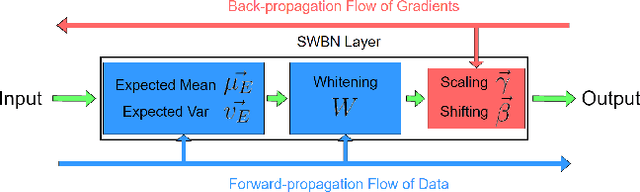
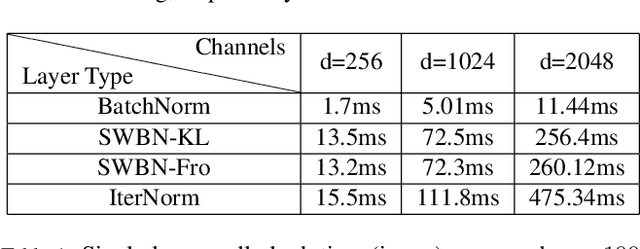
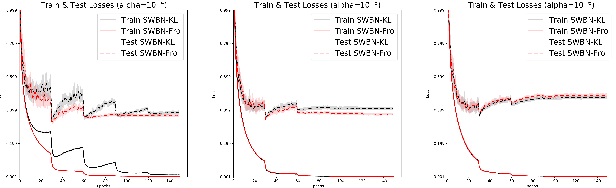
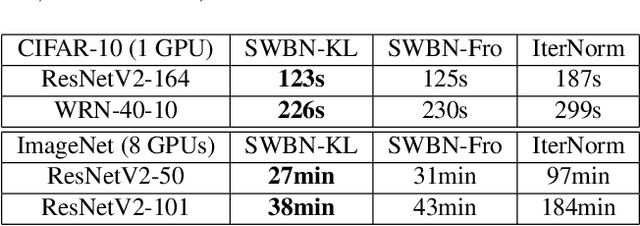
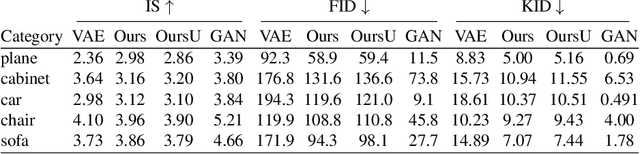
Batch Normalization (BN) is a popular technique for training Deep Neural Networks (DNNs). BN uses scaling and shifting to normalize activations of mini-batches to accelerate convergence and improve generalization. The recently proposed Iterative Normalization (IterNorm) method improves these properties by whitening the activations iteratively using Newton's method. However, since Newton's method initializes the whitening matrix independently at each training step, no information is shared between consecutive steps. In this work, instead of exact computation of whitening matrix at each time step, we estimate it gradually during training in an online fashion, using our proposed Stochastic Whitening Batch Normalization (SWBN) algorithm. We show that while SWBN improves the convergence rate and generalization of DNNs, its computational overhead is less than that of IterNorm. Due to the high efficiency of the proposed method, it can be easily employed in most DNN architectures with a large number of layers. We provide comprehensive experiments and comparisons between BN, IterNorm, and SWBN layers to demonstrate the effectiveness of the proposed technique in conventional (many-shot) image classification and few-shot classification tasks.
Few-Shot Learning with Part Discovery and Augmentation from Unlabeled Images
May 25, 2021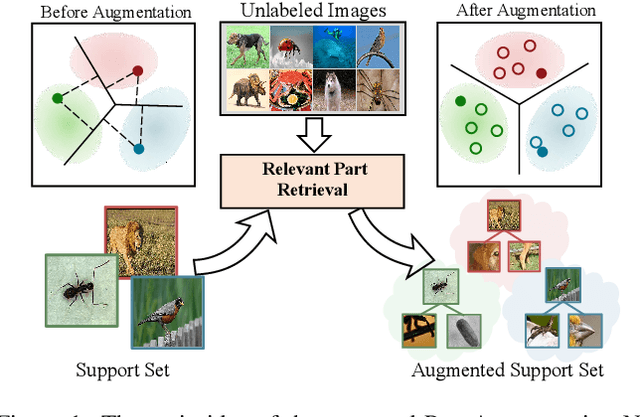
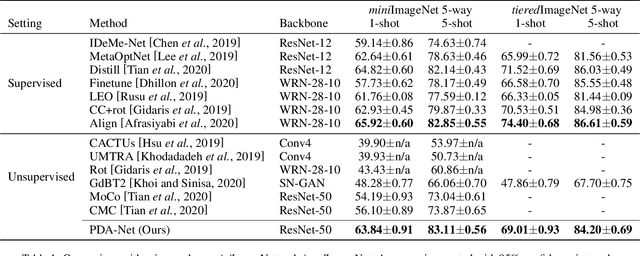
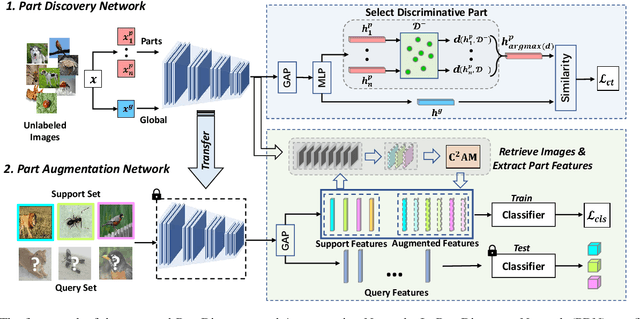

Few-shot learning is a challenging task since only few instances are given for recognizing an unseen class. One way to alleviate this problem is to acquire a strong inductive bias via meta-learning on similar tasks. In this paper, we show that such inductive bias can be learned from a flat collection of unlabeled images, and instantiated as transferable representations among seen and unseen classes. Specifically, we propose a novel part-based self-supervised representation learning scheme to learn transferable representations by maximizing the similarity of an image to its discriminative part. To mitigate the overfitting in few-shot classification caused by data scarcity, we further propose a part augmentation strategy by retrieving extra images from a base dataset. We conduct systematic studies on miniImageNet and tieredImageNet benchmarks. Remarkably, our method yields impressive results, outperforming the previous best unsupervised methods by 7.74% and 9.24% under 5-way 1-shot and 5-way 5-shot settings, which are comparable with state-of-the-art supervised methods.
Discriminative Region Suppression for Weakly-Supervised Semantic Segmentation
Mar 12, 2021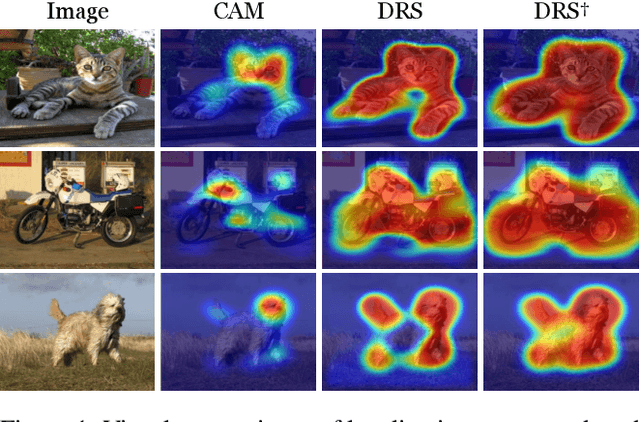
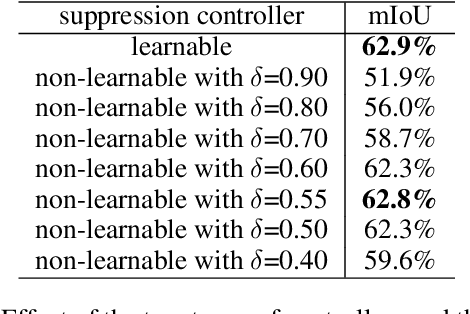
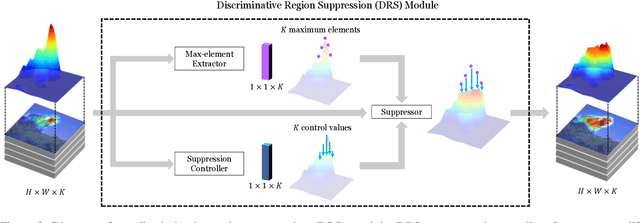

Weakly-supervised semantic segmentation (WSSS) using image-level labels has recently attracted much attention for reducing annotation costs. Existing WSSS methods utilize localization maps from the classification network to generate pseudo segmentation labels. However, since localization maps obtained from the classifier focus only on sparse discriminative object regions, it is difficult to generate high-quality segmentation labels. To address this issue, we introduce discriminative region suppression (DRS) module that is a simple yet effective method to expand object activation regions. DRS suppresses the attention on discriminative regions and spreads it to adjacent non-discriminative regions, generating dense localization maps. DRS requires few or no additional parameters and can be plugged into any network. Furthermore, we introduce an additional learning strategy to give a self-enhancement of localization maps, named localization map refinement learning. Benefiting from this refinement learning, localization maps are refined and enhanced by recovering some missing parts or removing noise itself. Due to its simplicity and effectiveness, our approach achieves mIoU 71.4% on the PASCAL VOC 2012 segmentation benchmark using only image-level labels. Extensive experiments demonstrate the effectiveness of our approach. The code is available at https://github.com/qjadud1994/DRS.
Fighting Fake News: Image Splice Detection via Learned Self-Consistency
Sep 05, 2018
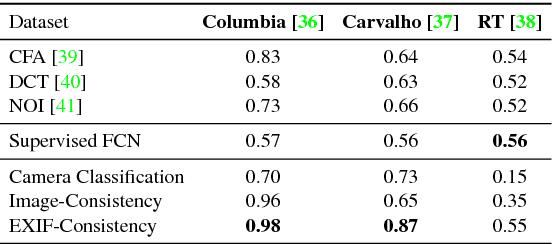

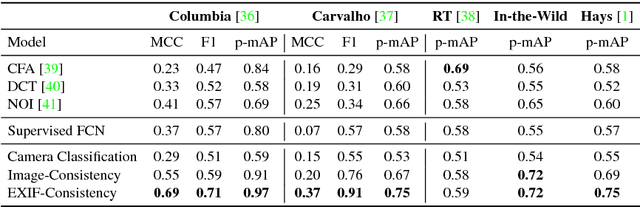
Advances in photo editing and manipulation tools have made it significantly easier to create fake imagery. Learning to detect such manipulations, however, remains a challenging problem due to the lack of sufficient amounts of manipulated training data. In this paper, we propose a learning algorithm for detecting visual image manipulations that is trained only using a large dataset of real photographs. The algorithm uses the automatically recorded photo EXIF metadata as supervisory signal for training a model to determine whether an image is self-consistent -- that is, whether its content could have been produced by a single imaging pipeline. We apply this self-consistency model to the task of detecting and localizing image splices. The proposed method obtains state-of-the-art performance on several image forensics benchmarks, despite never seeing any manipulated images at training. That said, it is merely a step in the long quest for a truly general purpose visual forensics tool.
Unsupervised 3D Human Mesh Recovery from Noisy Point Clouds
Jul 15, 2021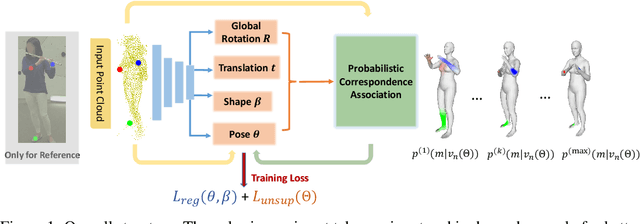
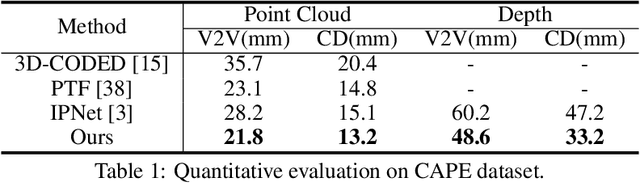
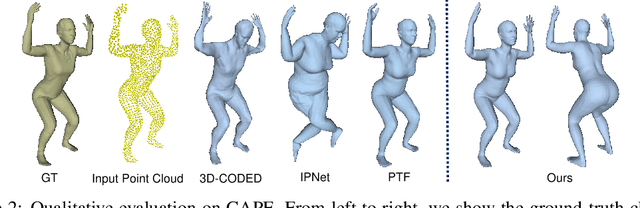
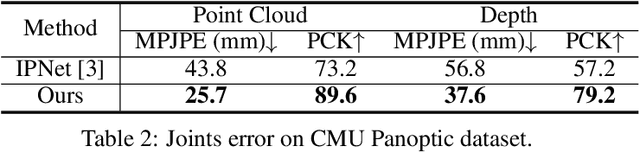
This paper presents a novel unsupervised approach to reconstruct human shape and pose from noisy point cloud. Traditional approaches search for correspondences and conduct model fitting iteratively where a good initialization is critical. Relying on large amount of dataset with ground-truth annotations, recent learning-based approaches predict correspondences for every vertice on the point cloud; Chamfer distance is usually used to minimize the distance between a deformed template model and the input point cloud. However, Chamfer distance is quite sensitive to noise and outliers, thus could be unreliable to assign correspondences. To address these issues, we model the probability distribution of the input point cloud as generated from a parametric human model under a Gaussian Mixture Model. Instead of explicitly aligning correspondences, we treat the process of correspondence search as an implicit probabilistic association by updating the posterior probability of the template model given the input. A novel unsupervised loss is further derived that penalizes the discrepancy between the deformed template and the input point cloud conditioned on the posterior probability. Our approach is very flexible, which works with both complete point cloud and incomplete ones including even a single depth image as input. Our network is trained from scratch with no need to warm-up the network with supervised data. Compared to previous unsupervised methods, our method shows the capability to deal with substantial noise and outliers. Extensive experiments conducted on various public synthetic datasets as well as a very noisy real dataset (i.e. CMU Panoptic) demonstrate the superior performance of our approach over the state-of-the-art methods. Code can be found \url{https://github.com/wangsen1312/unsupervised3dhuman.git}
Passage Retrieval for Outside-Knowledge Visual Question Answering
May 09, 2021

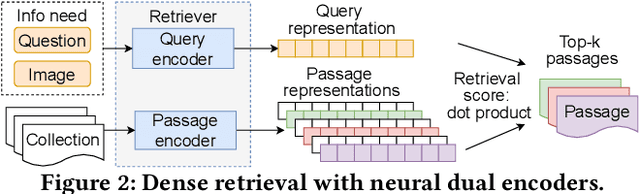
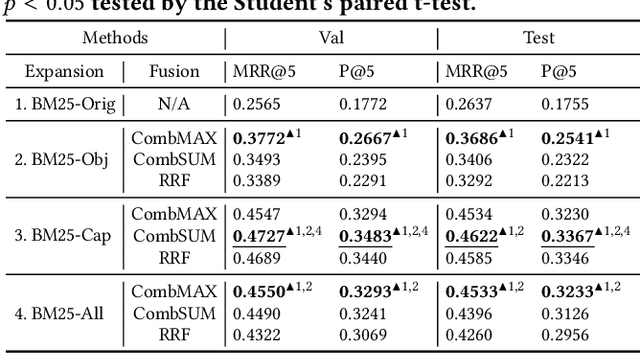
In this work, we address multi-modal information needs that contain text questions and images by focusing on passage retrieval for outside-knowledge visual question answering. This task requires access to outside knowledge, which in our case we define to be a large unstructured passage collection. We first conduct sparse retrieval with BM25 and study expanding the question with object names and image captions. We verify that visual clues play an important role and captions tend to be more informative than object names in sparse retrieval. We then construct a dual-encoder dense retriever, with the query encoder being LXMERT, a multi-modal pre-trained transformer. We further show that dense retrieval significantly outperforms sparse retrieval that uses object expansion. Moreover, dense retrieval matches the performance of sparse retrieval that leverages human-generated captions.