 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIM: Zero-Shot Image Matting for Anything
Nov 01, 2024



The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D NeRF. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code is available at \url{https://github.com/naver-ai/ZIM}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Rethinking Saliency-Guided Weakly-Supervised Semantic Segmentation
Apr 02, 2024This paper presents a fresh perspective on the role of saliency maps in weakly-supervised semantic segmentation (WSSS) and offers new insights and research directions based on our empirical findings. We conduct comprehensive experiments and observe that the quality of the saliency map is a critical factor in saliency-guided WSSS approaches. Nonetheless, we find that the saliency maps used in previous works are often arbitrarily chosen, despite their significant impact on WSSS. Additionally, we observe that the choice of the threshold, which has received less attention before, is non-trivial in WSSS. To facilitate more meaningful and rigorous research for saliency-guided WSSS, we introduce \texttt{WSSS-BED}, a standardized framework for conducting research under unified conditions. \texttt{WSSS-BED} provides various saliency maps and activation maps for seven WSSS methods, as well as saliency maps from unsupervised salient object detection models.
Towards Label-Efficient Human Matting: A Simple Baseline for Weakly Semi-Supervised Trimap-Free Human Matting
Apr 01, 2024



This paper presents a new practical training method for human matting, which demands delicate pixel-level human region identification and significantly laborious annotations. To reduce the annotation cost, most existing matting approaches often rely on image synthesis to augment the dataset. However, the unnaturalness of synthesized training images brings in a new domain generalization challenge for natural images. To address this challenge, we introduce a new learning paradigm, weakly semi-supervised human matting (WSSHM), which leverages a small amount of expensive matte labels and a large amount of budget-friendly segmentation labels, to save the annotation cost and resolve the domain generalization problem. To achieve the goal of WSSHM, we propose a simple and effective training method, named Matte Label Blending (MLB), that selectively guides only the beneficial knowledge of the segmentation and matte data to the matting model. Extensive experiments with our detailed analysis demonstrate our method can substantially improve the robustness of the matting model using a few matte data and numerous segmentation data. Our training method is also easily applicable to real-time models, achieving competitive accuracy with breakneck inference speed (328 FPS on NVIDIA V100 GPU). The implementation code is available at \url{https://github.com/clovaai/WSSHM}.
ECLIPSE: Efficient Continual Learning in Panoptic Segmentation with Visual Prompt Tuning
Mar 29, 2024Panoptic segmentation, combining semantic and instance segmentation, stands as a cutting-edge computer vision task. Despite recent progress with deep learning models, the dynamic nature of real-world applications necessitates continual learning, where models adapt to new classes (plasticity) over time without forgetting old ones (catastrophic forgetting). Current continual segmentation methods often rely on distillation strategies like knowledge distillation and pseudo-labeling, which are effective but result in increased training complexity and computational overhead. In this paper, we introduce a novel and efficient method for continual panoptic segmentation based on Visual Prompt Tuning, dubbed ECLIPSE. Our approach involves freezing the base model parameters and fine-tuning only a small set of prompt embeddings, addressing both catastrophic forgetting and plasticity and significantly reducing the trainable parameters. To mitigate inherent challenges such as error propagation and semantic drift in continual segmentation, we propose logit manipulation to effectively leverage common knowledge across the classes. Experiments on ADE20K continual panoptic segmentation benchmark demonstrate the superiority of ECLIPSE, notably its robustness against catastrophic forgetting and its reasonable plasticity, achieving a new state-of-the-art. The code is available at https://github.com/clovaai/ECLIPSE.
The Devil is in the Points: Weakly Semi-Supervised Instance Segmentation via Point-Guided Mask Representation
Mar 27, 2023In this paper, we introduce a novel learning scheme named weakly semi-supervised instance segmentation (WSSIS) with point labels for budget-efficient and high-performance instance segmentation. Namely, we consider a dataset setting consisting of a few fully-labeled images and a lot of point-labeled images. Motivated by the main challenge of semi-supervised approaches mainly derives from the trade-off between false-negative and false-positive instance proposals, we propose a method for WSSIS that can effectively leverage the budget-friendly point labels as a powerful weak supervision source to resolve the challenge. Furthermore, to deal with the hard case where the amount of fully-labeled data is extremely limited, we propose a MaskRefineNet that refines noise in rough masks. We conduct extensive experiments on COCO and BDD100K datasets, and the proposed method achieves promising results comparable to those of the fully-supervised model, even with 50% of the fully labeled COCO data (38.8% vs. 39.7%). Moreover, when using as little as 5% of fully labeled COCO data, our method shows significantly superior performance over the state-of-the-art semi-supervised learning method (33.7% vs. 24.9%). The code is available at https://github.com/clovaai/PointWSSIS.
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022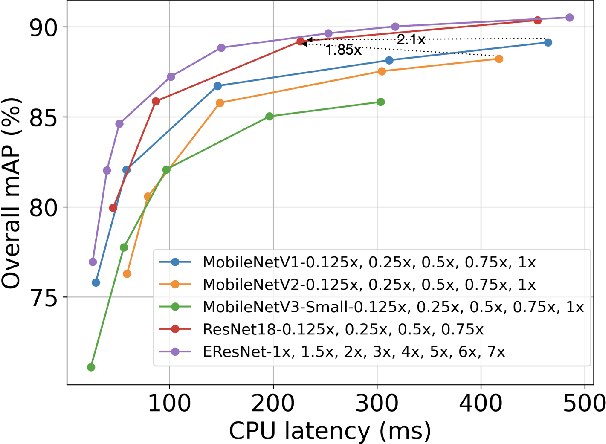
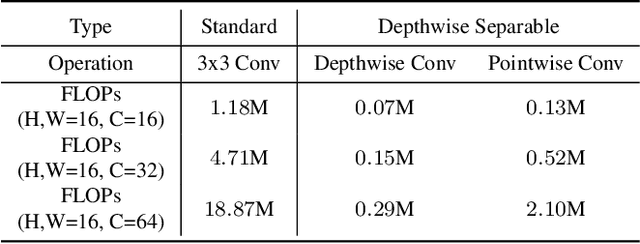
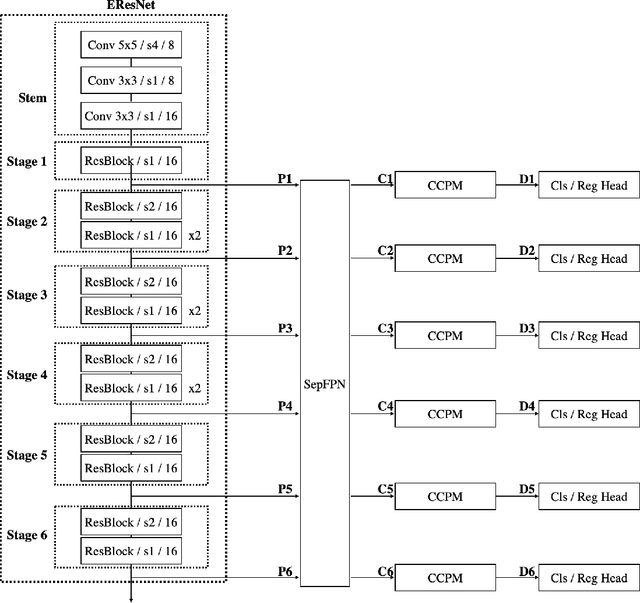
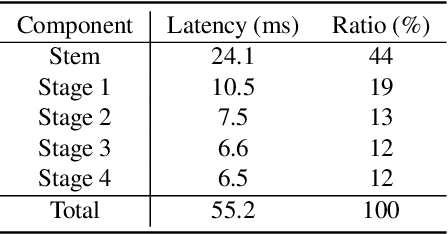
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.
Learning Features with Parameter-Free Layers
Feb 06, 2022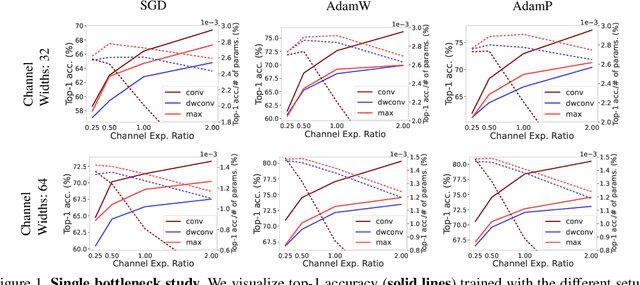
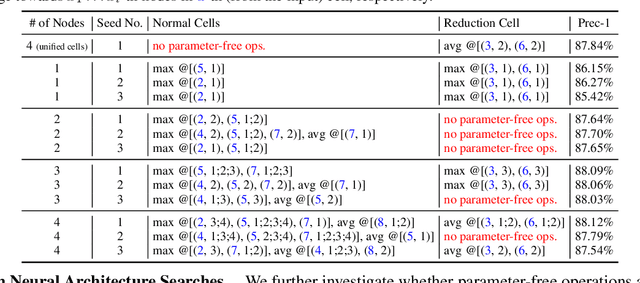
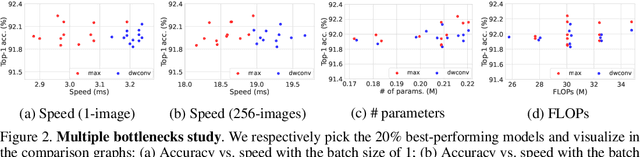
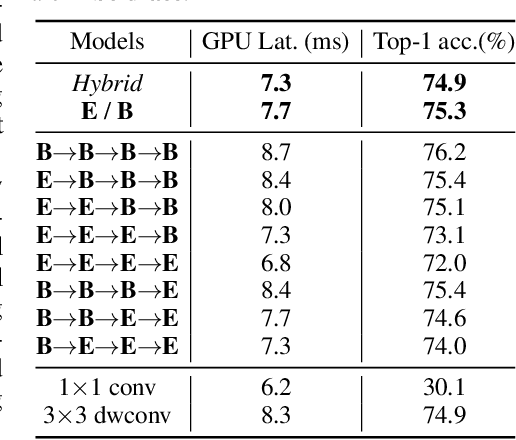
Trainable layers such as convolutional building blocks are the standard network design choices by learning parameters to capture the global context through successive spatial operations. When designing an efficient network, trainable layers such as the depthwise convolution is the source of efficiency in the number of parameters and FLOPs, but there was little improvement to the model speed in practice. This paper argues that simple built-in parameter-free operations can be a favorable alternative to the efficient trainable layers replacing spatial operations in a network architecture. We aim to break the stereotype of organizing the spatial operations of building blocks into trainable layers. Extensive experimental analyses based on layer-level studies with fully-trained models and neural architecture searches are provided to investigate whether parameter-free operations such as the max-pool are functional. The studies eventually give us a simple yet effective idea for redesigning network architectures, where the parameter-free operations are heavily used as the main building block without sacrificing the model accuracy as much. Experimental results on the ImageNet dataset demonstrate that the network architectures with parameter-free operations could enjoy the advantages of further efficiency in terms of model speed, the number of the parameters, and FLOPs. Code and ImageNet pretrained models are available at https://github.com/naver-ai/PfLayer.
Beyond Semantic to Instance Segmentation: Weakly-Supervised Instance Segmentation via Semantic Knowledge Transfer and Self-Refinement
Sep 20, 2021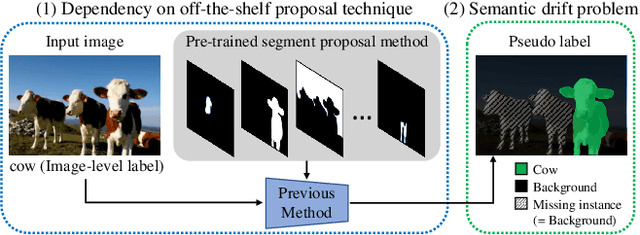
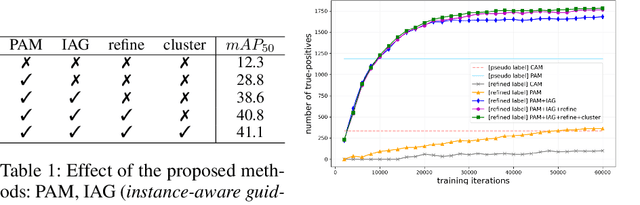
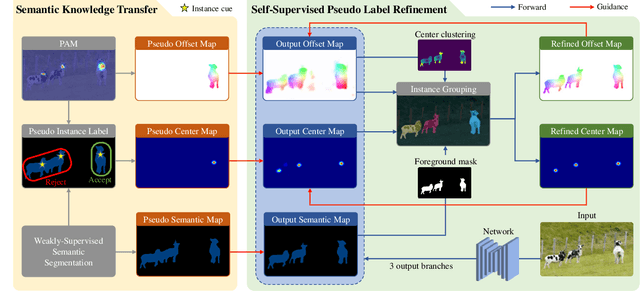
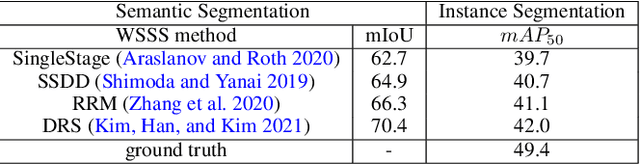
Recent weakly-supervised semantic segmentation (WSSS) has made remarkable progress due to class-wise localization techniques using image-level labels. Meanwhile, weakly-supervised instance segmentation (WSIS) is a more challenging task because instance-wise localization using only image-level labels is quite difficult. Consequently, most WSIS approaches exploit off-the-shelf proposal technique that requires pre-training with high-level labels, deviating a fully image-level supervised setting. Moreover, we focus on semantic drift problem, $i.e.,$ missing instances in pseudo instance labels are categorized as background class, occurring confusion between background and instance in training. To this end, we propose a novel approach that consists of two innovative components. First, we design a semantic knowledge transfer to obtain pseudo instance labels by transferring the knowledge of WSSS to WSIS while eliminating the need for off-the-shelf proposals. Second, we propose a self-refinement method that refines the pseudo instance labels in a self-supervised scheme and employs them to the training in an online manner while resolving the semantic drift problem. The extensive experiments demonstrate the effectiveness of our approach, and we outperform existing works on PASCAL VOC2012 without any off-the-shelf proposal techniques. Furthermore, our approach can be easily applied to the point-supervised setting, boosting the performance with an economical annotation cost. The code will be available soon.
SSUL: Semantic Segmentation with Unknown Label for Exemplar-based Class-Incremental Learning
Jul 01, 2021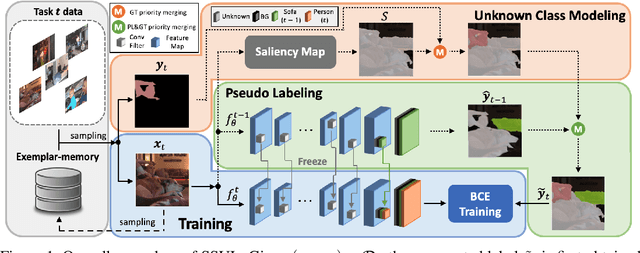


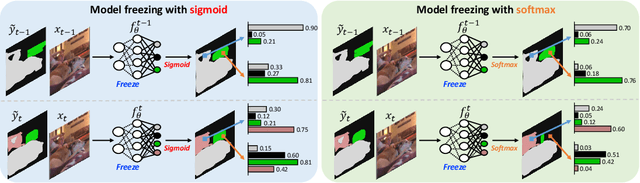
We consider a class-incremental semantic segmentation (CISS) problem. While some recently proposed algorithms utilized variants of knowledge distillation (KD) technique to tackle the problem, they only partially addressed the key additional challenges in CISS that causes the catastrophic forgetting; i.e., the semantic drift of the background class and multi-label prediction issue. To better address these challenges, we propose a new method, dubbed as SSUL-M (Semantic Segmentation with Unknown Label with Memory), by carefully combining several techniques tailored for semantic segmentation. More specifically, we make three main contributions; (1) modeling unknown class within the background class to help learning future classes (help plasticity), (2) freezing backbone network and past classifiers with binary cross-entropy loss and pseudo-labeling to overcome catastrophic forgetting (help stability), and (3) utilizing tiny exemplar memory for the first time in CISS to improve both plasticity and stability. As a result, we show our method achieves significantly better performance than the recent state-of-the-art baselines on the standard benchmark datasets. Furthermore, we justify our contributions with thorough and extensive ablation analyses and discuss different natures of the CISS problem compared to the standard class-incremental learning for classification.