 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Truncated Newton Method for Optimal Transport
Apr 02, 2025Developing a contemporary optimal transport (OT) solver requires navigating trade-offs among several critical requirements: GPU parallelization, scalability to high-dimensional problems, theoretical convergence guarantees, empirical performance in terms of precision versus runtime, and numerical stability in practice. With these challenges in mind, we introduce a specialized truncated Newton algorithm for entropic-regularized OT. In addition to proving that locally quadratic convergence is possible without assuming a Lipschitz Hessian, we provide strategies to maximally exploit the high rate of local convergence in practice. Our GPU-parallel algorithm exhibits exceptionally favorable runtime performance, achieving high precision orders of magnitude faster than many existing alternatives. This is evidenced by wall-clock time experiments on 24 problem sets (12 datasets $\times$ 2 cost functions). The scalability of the algorithm is showcased on an extremely large OT problem with $n \approx 10^6$, solved approximately under weak entopric regularization.
Efficient and Accurate Optimal Transport with Mirror Descent and Conjugate Gradients
Jul 17, 2023We design a novel algorithm for optimal transport by drawing from the entropic optimal transport, mirror descent and conjugate gradients literatures. Our algorithm is able to compute optimal transport costs with arbitrary accuracy without running into numerical stability issues. The algorithm is implemented efficiently on GPUs and is shown empirically to converge more quickly than traditional algorithms such as Sinkhorn's Algorithm both in terms of number of iterations and wall-clock time in many cases. We pay particular attention to the entropy of marginal distributions and show that high entropy marginals make for harder optimal transport problems, for which our algorithm is a good fit. We provide a careful ablation analysis with respect to algorithm and problem parameters, and present benchmarking over the MNIST dataset. The results suggest that our algorithm can be a useful addition to the practitioner's optimal transport toolkit. Our code is open-sourced at https://github.com/adaptive-agents-lab/MDOT-PNCG .
StepFormer: Self-supervised Step Discovery and Localization in Instructional Videos
Apr 26, 2023



Instructional videos are an important resource to learn procedural tasks from human demonstrations. However, the instruction steps in such videos are typically short and sparse, with most of the video being irrelevant to the procedure. This motivates the need to temporally localize the instruction steps in such videos, i.e. the task called key-step localization. Traditional methods for key-step localization require video-level human annotations and thus do not scale to large datasets. In this work, we tackle the problem with no human supervision and introduce StepFormer, a self-supervised model that discovers and localizes instruction steps in a video. StepFormer is a transformer decoder that attends to the video with learnable queries, and produces a sequence of slots capturing the key-steps in the video. We train our system on a large dataset of instructional videos, using their automatically-generated subtitles as the only source of supervision. In particular, we supervise our system with a sequence of text narrations using an order-aware loss function that filters out irrelevant phrases. We show that our model outperforms all previous unsupervised and weakly-supervised approaches on step detection and localization by a large margin on three challenging benchmarks. Moreover, our model demonstrates an emergent property to solve zero-shot multi-step localization and outperforms all relevant baselines at this task.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022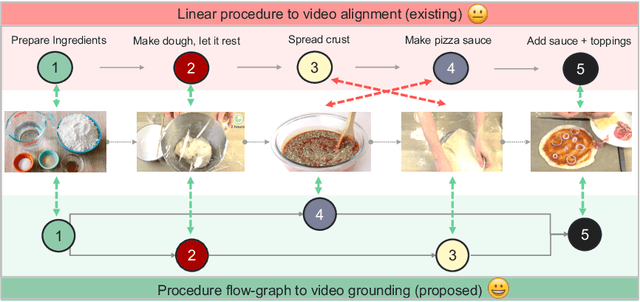
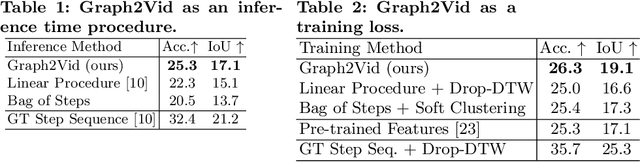

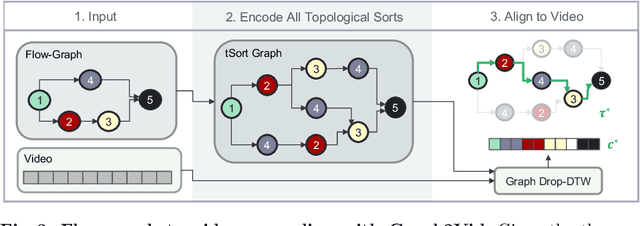
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
P3IV: Probabilistic Procedure Planning from Instructional Videos with Weak Supervision
May 04, 2022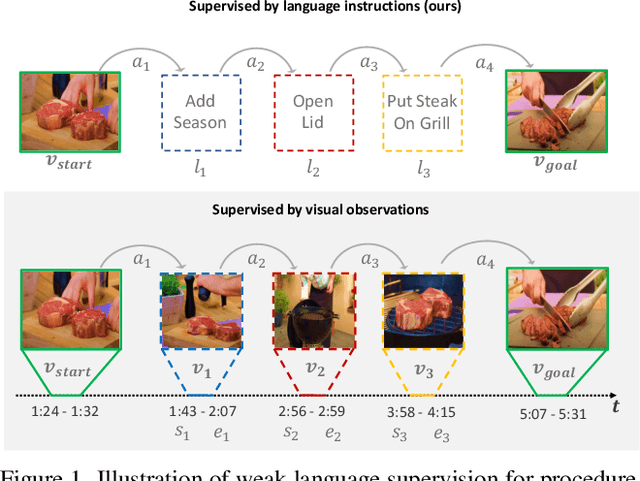
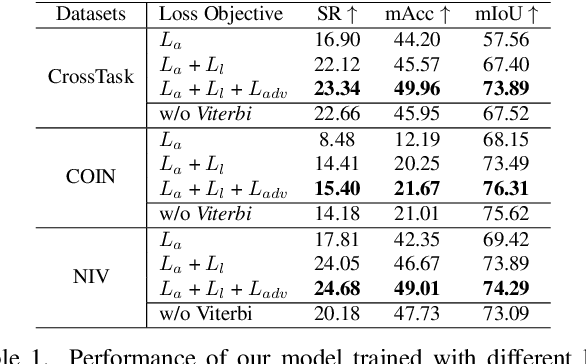
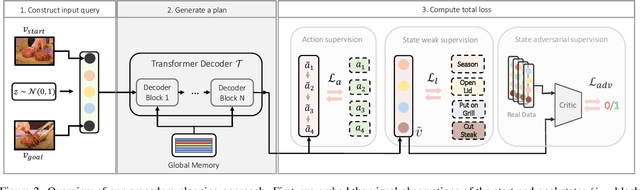
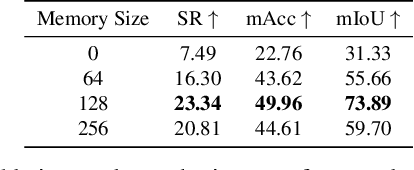
In this paper, we study the problem of procedure planning in instructional videos. Here, an agent must produce a plausible sequence of actions that can transform the environment from a given start to a desired goal state. When learning procedure planning from instructional videos, most recent work leverages intermediate visual observations as supervision, which requires expensive annotation efforts to localize precisely all the instructional steps in training videos. In contrast, we remove the need for expensive temporal video annotations and propose a weakly supervised approach by learning from natural language instructions. Our model is based on a transformer equipped with a memory module, which maps the start and goal observations to a sequence of plausible actions. Furthermore, we augment our model with a probabilistic generative module to capture the uncertainty inherent to procedure planning, an aspect largely overlooked by previous work. We evaluate our model on three datasets and show our weaklysupervised approach outperforms previous fully supervised state-of-the-art models on multiple metrics.
Drop-DTW: Aligning Common Signal Between Sequences While Dropping Outliers
Aug 26, 2021
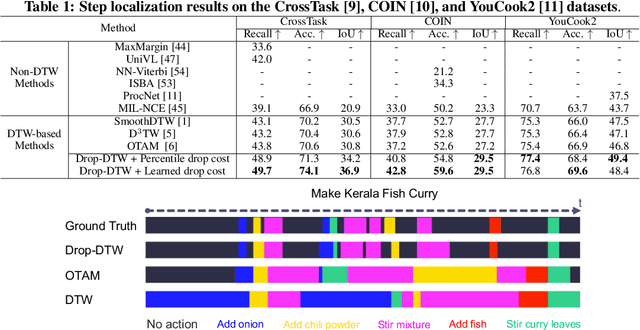
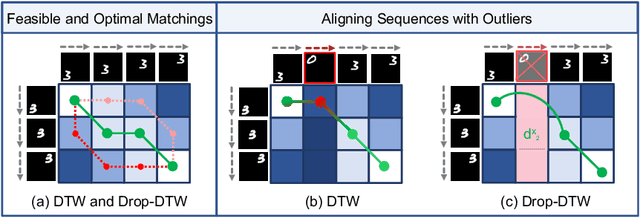
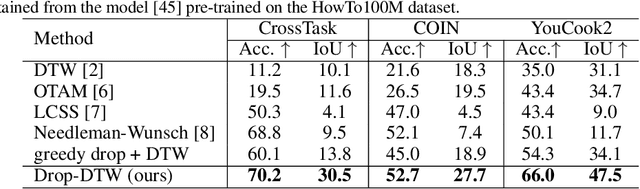
In this work, we consider the problem of sequence-to-sequence alignment for signals containing outliers. Assuming the absence of outliers, the standard Dynamic Time Warping (DTW) algorithm efficiently computes the optimal alignment between two (generally) variable-length sequences. While DTW is robust to temporal shifts and dilations of the signal, it fails to align sequences in a meaningful way in the presence of outliers that can be arbitrarily interspersed in the sequences. To address this problem, we introduce Drop-DTW, a novel algorithm that aligns the common signal between the sequences while automatically dropping the outlier elements from the matching. The entire procedure is implemented as a single dynamic program that is efficient and fully differentiable. In our experiments, we show that Drop-DTW is a robust similarity measure for sequence retrieval and demonstrate its effectiveness as a training loss on diverse applications. With Drop-DTW, we address temporal step localization on instructional videos, representation learning from noisy videos, and cross-modal representation learning for audio-visual retrieval and localization. In all applications, we take a weakly- or unsupervised approach and demonstrate state-of-the-art results under these settings.
Representation Learning via Global Temporal Alignment and Cycle-Consistency
May 11, 2021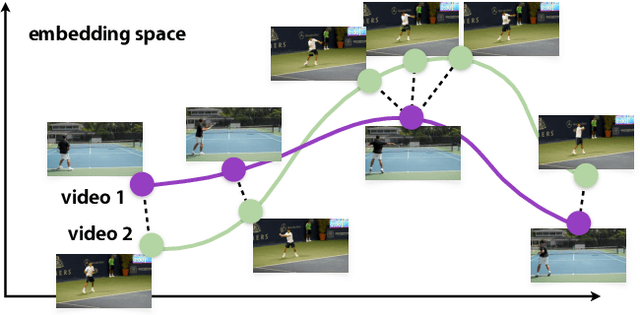

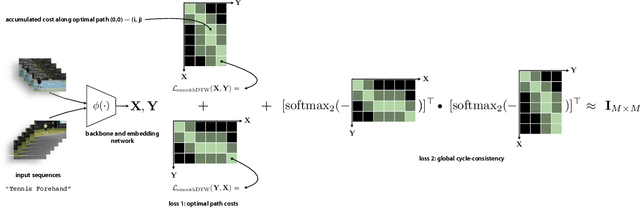
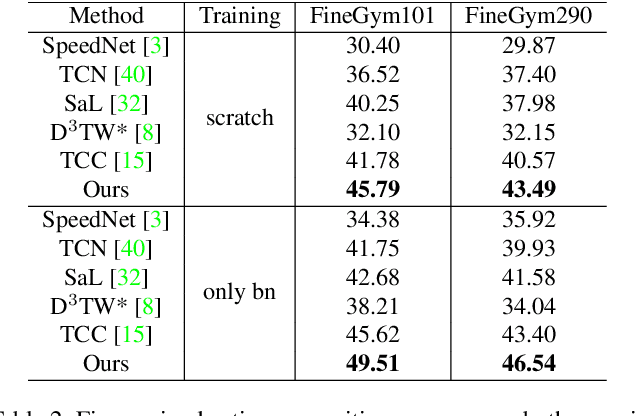
We introduce a weakly supervised method for representation learning based on aligning temporal sequences (e.g., videos) of the same process (e.g., human action). The main idea is to use the global temporal ordering of latent correspondences across sequence pairs as a supervisory signal. In particular, we propose a loss based on scoring the optimal sequence alignment to train an embedding network. Our loss is based on a novel probabilistic path finding view of dynamic time warping (DTW) that contains the following three key features: (i) the local path routing decisions are contrastive and differentiable, (ii) pairwise distances are cast as probabilities that are contrastive as well, and (iii) our formulation naturally admits a global cycle consistency loss that verifies correspondences. For evaluation, we consider the tasks of fine-grained action classification, few shot learning, and video synchronization. We report significant performance increases over previous methods. In addition, we report two applications of our temporal alignment framework, namely 3D pose reconstruction and fine-grained audio/visual retrieval.
Cycle-Consistent Generative Rendering for 2D-3D Modality Translation
Nov 16, 2020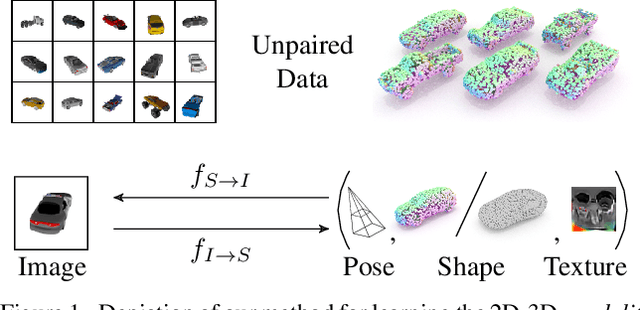
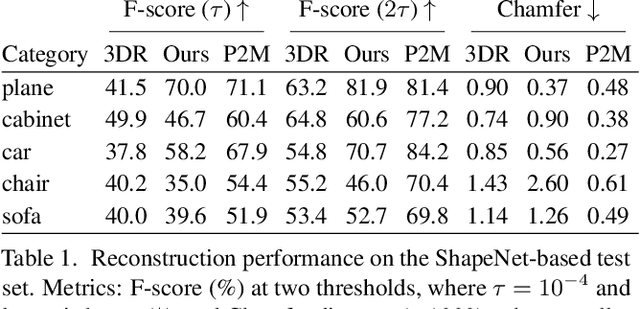

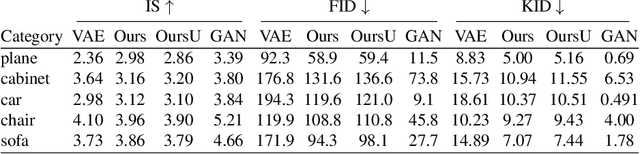
For humans, visual understanding is inherently generative: given a 3D shape, we can postulate how it would look in the world; given a 2D image, we can infer the 3D structure that likely gave rise to it. We can thus translate between the 2D visual and 3D structural modalities of a given object. In the context of computer vision, this corresponds to a learnable module that serves two purposes: (i) generate a realistic rendering of a 3D object (shape-to-image translation) and (ii) infer a realistic 3D shape from an image (image-to-shape translation). In this paper, we learn such a module while being conscious of the difficulties in obtaining large paired 2D-3D datasets. By leveraging generative domain translation methods, we are able to define a learning algorithm that requires only weak supervision, with unpaired data. The resulting model is not only able to perform 3D shape, pose, and texture inference from 2D images, but can also generate novel textured 3D shapes and renders, similar to a graphics pipeline. More specifically, our method (i) infers an explicit 3D mesh representation, (ii) utilizes example shapes to regularize inference, (iii) requires only an image mask (no keypoints or camera extrinsics), and (iv) has generative capabilities. While prior work explores subsets of these properties, their combination is novel. We demonstrate the utility of our learned representation, as well as its performance on image generation and unpaired 3D shape inference tasks.