 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021
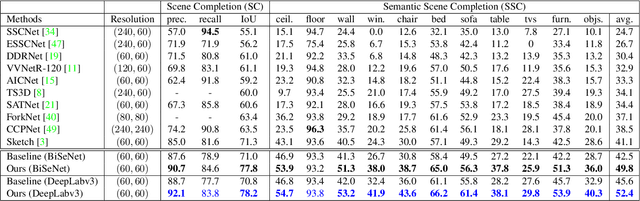

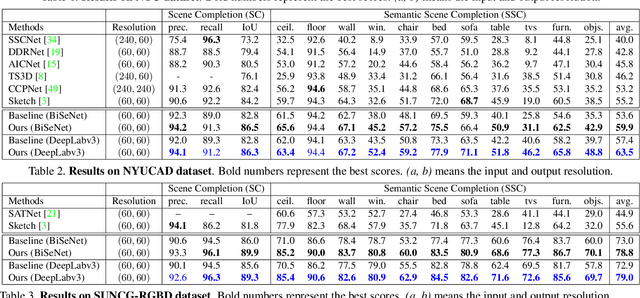
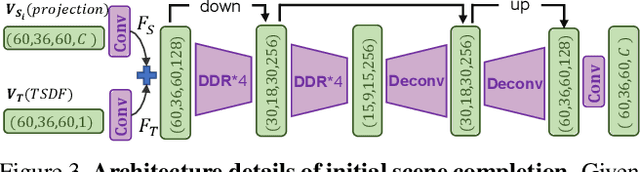
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.
Multi-bin Trainable Linear Unit for Fast Image Restoration Networks
Jul 30, 2018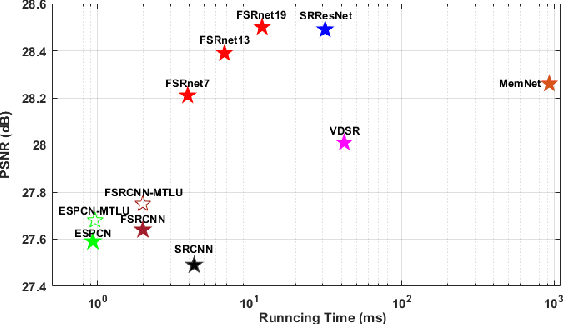
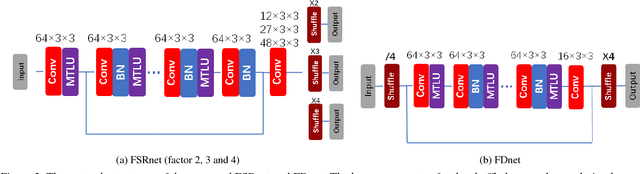
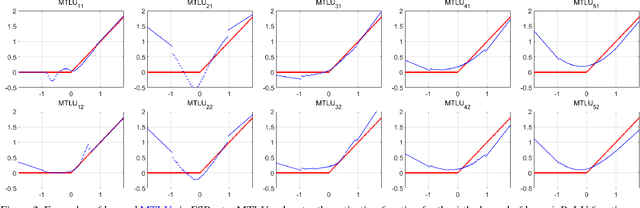
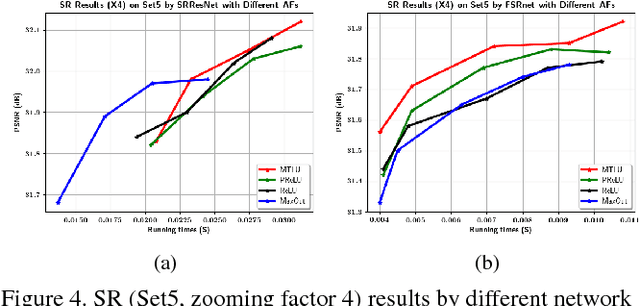
Tremendous advances in image restoration tasks such as denoising and super-resolution have been achieved using neural networks. Such approaches generally employ very deep architectures, large number of parameters, large receptive fields and high nonlinear modeling capacity. In order to obtain efficient and fast image restoration networks one should improve upon the above mentioned requirements. In this paper we propose a novel activation function, the multi-bin trainable linear unit (MTLU), for increasing the nonlinear modeling capacity together with lighter and shallower networks. We validate the proposed fast image restoration networks for image denoising (FDnet) and super-resolution (FSRnet) on standard benchmarks. We achieve large improvements in both memory and runtime over current state-of-the-art for comparable or better PSNR accuracies.
In-game Residential Home Planning via Visual Context-aware Global Relation Learning
Feb 23, 2021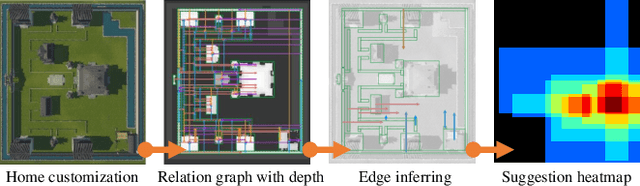
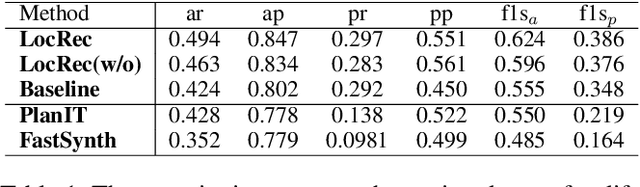
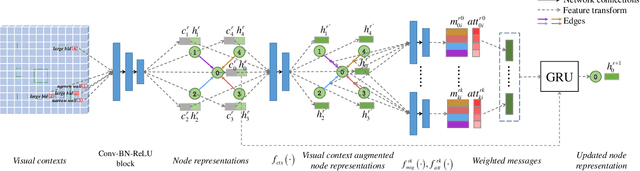
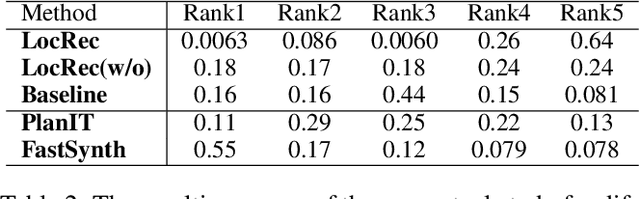
In this paper, we propose an effective global relation learning algorithm to recommend an appropriate location of a building unit for in-game customization of residential home complex. Given a construction layout, we propose a visual context-aware graph generation network that learns the implicit global relations among the scene components and infers the location of a new building unit. The proposed network takes as input the scene graph and the corresponding top-view depth image. It provides the location recommendations for a newly-added building units by learning an auto-regressive edge distribution conditioned on existing scenes. We also introduce a global graph-image matching loss to enhance the awareness of essential geometry semantics of the site. Qualitative and quantitative experiments demonstrate that the recommended location well reflects the implicit spatial rules of components in the residential estates, and it is instructive and practical to locate the building units in the 3D scene of the complex construction.
MarioNette: Self-Supervised Sprite Learning
Apr 29, 2021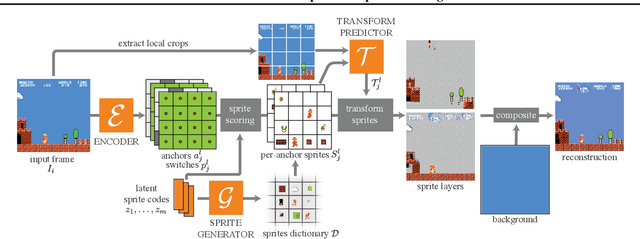
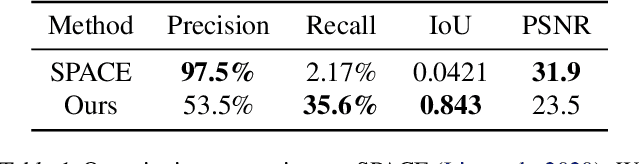
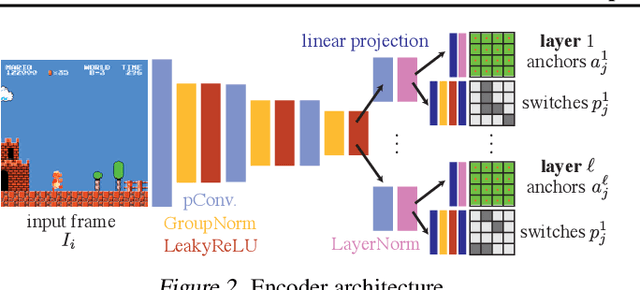
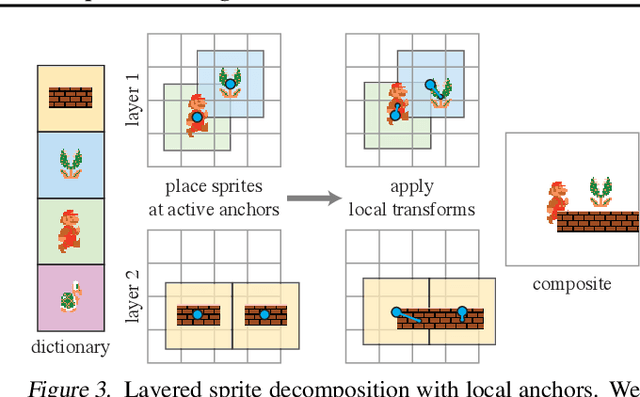
Visual content often contains recurring elements. Text is made up of glyphs from the same font, animations, such as cartoons or video games, are composed of sprites moving around the screen, and natural videos frequently have repeated views of objects. In this paper, we propose a deep learning approach for obtaining a graphically disentangled representation of recurring elements in a completely self-supervised manner. By jointly learning a dictionary of texture patches and training a network that places them onto a canvas, we effectively deconstruct sprite-based content into a sparse, consistent, and interpretable representation that can be easily used in downstream tasks. Our framework offers a promising approach for discovering recurring patterns in image collections without supervision.
Image classification and retrieval with random depthwise signed convolutional neural networks
Oct 09, 2018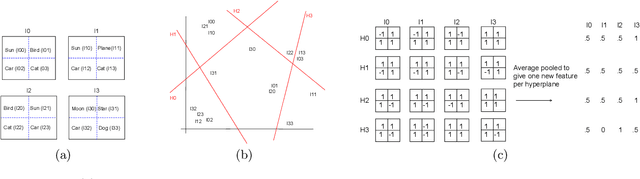
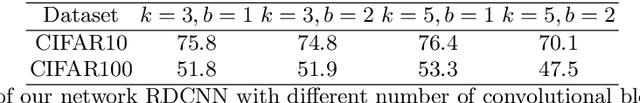
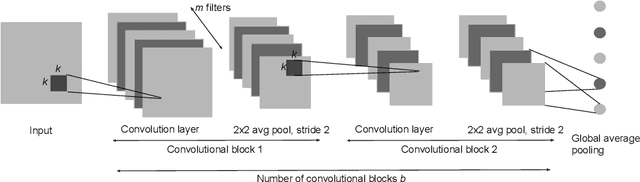
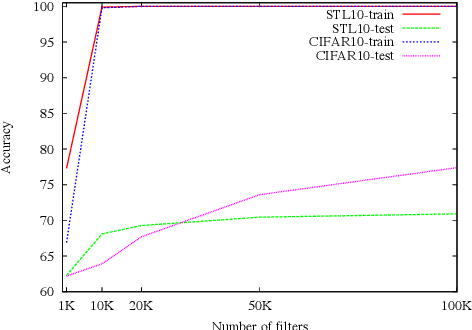
We study image classification and retrieval performance in a feature space given by random depthwise convolutional neural networks. Intuitively our network can be interpreted as applying random hyperplanes to the space of all patches of input images followed by average pooling to obtain final features. We show that the ratio of image pixel distribution similarity across classes to within classes and the average margin of the linear support vector machine on test data are both higher in our network's final layer compared to the input space. We then apply the linear support vector machine for image classification and $k$-nearest neighbor for image similarity detection on our network's final layer. We show that for classification our network attains higher accuracies than previous random networks and is not far behind in accuracy to trained state of the art networks, especially in the top-k setting. For example the top-2 accuracy of our network is near 90\% on both CIFAR10 and a 10-class mini ImageNet, and 85\% on STL10. In the problem of image similarity we find that $k$-nearest neighbor gives a comparable precision on the Corel Princeton Image Similarity Benchmark than if we were to use the last hidden layer of trained networks. We highlight sensitivity of our network to background color as a potential pitfall. Overall our work pushes the boundary of what can be achieved with random weights.
Scalable Marginal Likelihood Estimation for Model Selection in Deep Learning
May 11, 2021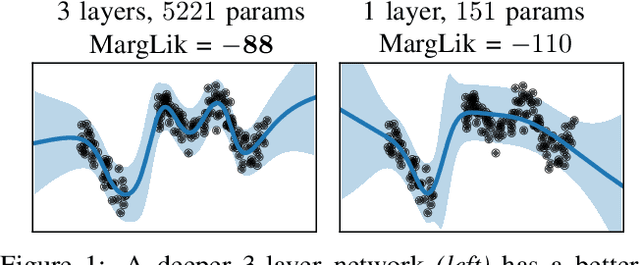
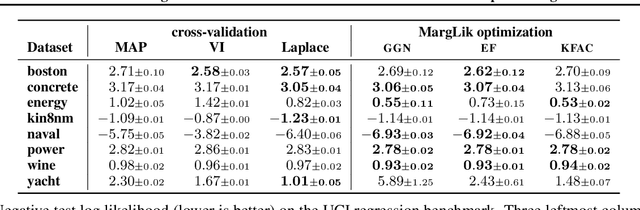
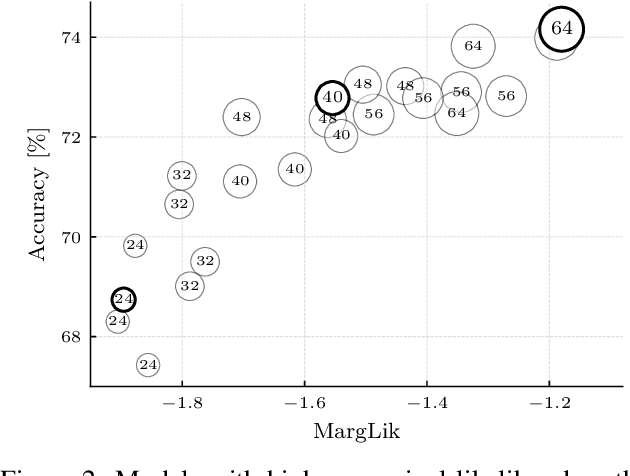
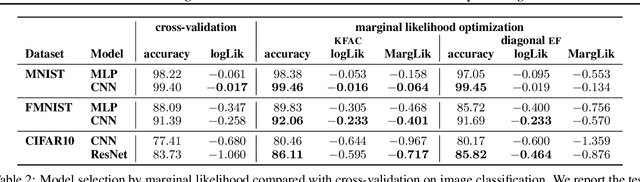
Marginal-likelihood based model-selection, even though promising, is rarely used in deep learning due to estimation difficulties. Instead, most approaches rely on validation data, which may not be readily available. In this work, we present a scalable marginal-likelihood estimation method to select both the hyperparameters and network architecture based on the training data alone. Some hyperparameters can be estimated online during training, simplifying the procedure. Our marginal-likelihood estimate is based on Laplace's method and Gauss-Newton approximations to the Hessian, and it outperforms cross-validation and manual-tuning on standard regression and image classification datasets, especially in terms of calibration and out-of-distribution detection. Our work shows that marginal likelihoods can improve generalization and be useful when validation data is unavailable (e.g., in nonstationary settings).
WDNet: Watermark-Decomposition Network for Visible Watermark Removal
Dec 14, 2020

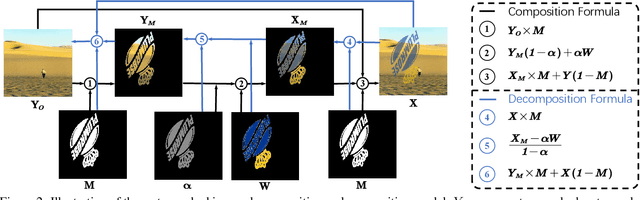
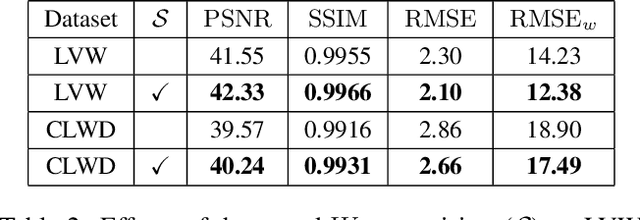
Visible watermarks are widely-used in images to protect copyright ownership. Analyzing watermark removal helps to reinforce the anti-attack techniques in an adversarial way. Current removal methods normally leverage image-to-image translation techniques. Nevertheless, the uncertainty of the size, shape, color and transparency of the watermarks set a huge barrier for these methods. To combat this, we combine traditional watermarked image decomposition into a two-stage generator, called Watermark-Decomposition Network (WDNet), where the first stage predicts a rough decomposition from the whole watermarked image and the second stage specifically centers on the watermarked area to refine the removal results. The decomposition formulation enables WDNet to separate watermarks from the images rather than simply removing them. We further show that these separated watermarks can serve as extra nutrients for building a larger training dataset and further improving removal performance. Besides, we construct a large-scale dataset named CLWD, which mainly contains colored watermarks, to fill the vacuum of colored watermark removal dataset. Extensive experiments on the public gray-scale dataset LVW and CLWD consistently show that the proposed WDNet outperforms the state-of-the-art approaches both in accuracy and efficiency.
Image segmentation of liver stage malaria infection with spatial uncertainty sampling
Nov 30, 2019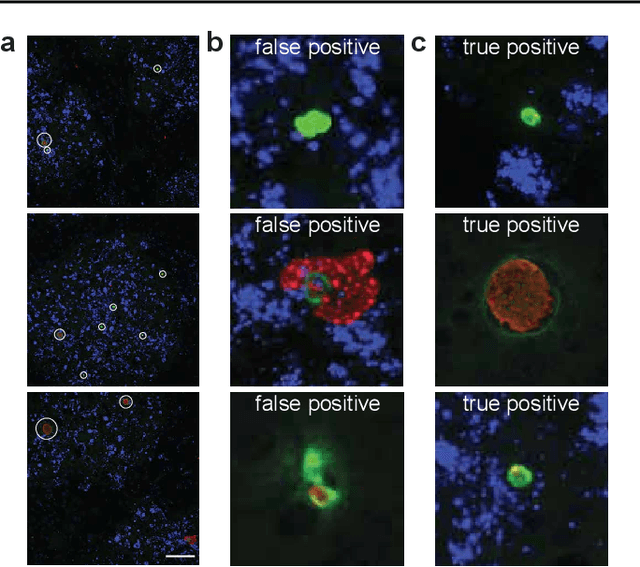
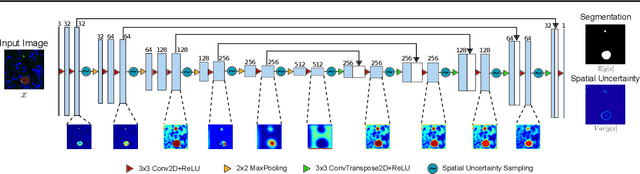
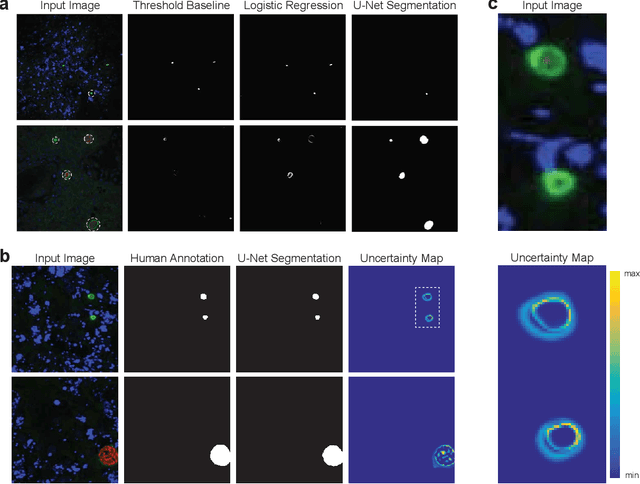
Global eradication of malaria depends on the development of drugs effective against the silent, yet obligate liver stage of the disease. The gold standard in drug development remains microscopic imaging of liver stage parasites in in vitro cell culture models. Image analysis presents a major bottleneck in this pipeline since the parasite has significant variability in size, shape, and density in these models. As with other highly variable datasets, traditional segmentation models have poor generalizability as they rely on hand-crafted features; thus, manual annotation of liver stage malaria images remains standard. To address this need, we develop a convolutional neural network architecture that utilizes spatial dropout sampling for parasite segmentation and epistemic uncertainty estimation in images of liver stage malaria. Our pipeline produces high-precision segmentations nearly identical to expert annotations, generalizes well on a diverse dataset of liver stage malaria parasites, and promotes independence between learned feature maps to model the uncertainty of generated predictions.
Full-Frame Scene Coordinate Regression for Image-Based Localization
Jun 25, 2018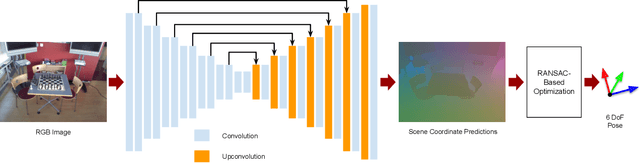

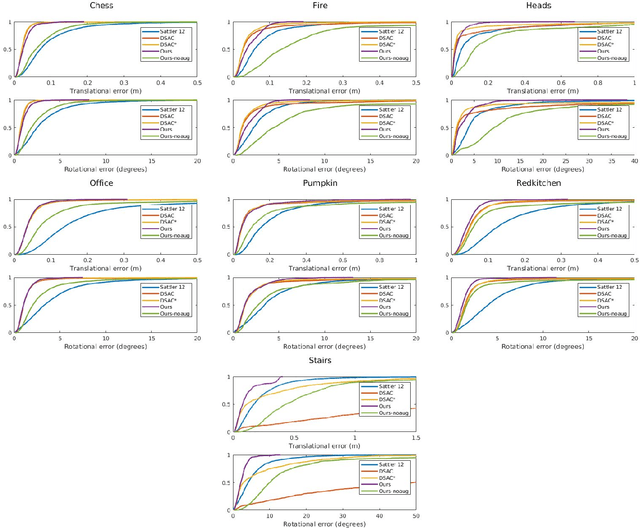
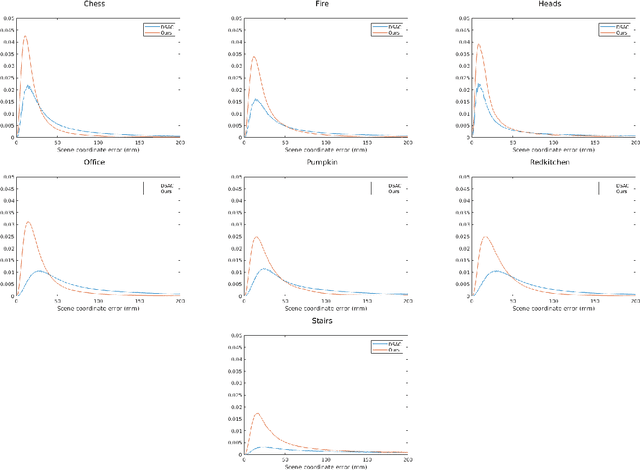
Image-based localization, or camera relocalization, is a fundamental problem in computer vision and robotics, and it refers to estimating camera pose from an image. Recent state-of-the-art approaches use learning based methods, such as Random Forests (RFs) and Convolutional Neural Networks (CNNs), to regress for each pixel in the image its corresponding position in the scene's world coordinate frame, and solve the final pose via a RANSAC-based optimization scheme using the predicted correspondences. In this paper, instead of in a patch-based manner, we propose to perform the scene coordinate regression in a full-frame manner to make the computation efficient at test time and, more importantly, to add more global context to the regression process to improve the robustness. To do so, we adopt a fully convolutional encoder-decoder neural network architecture which accepts a whole image as input and produces scene coordinate predictions for all pixels in the image. However, using more global context is prone to overfitting. To alleviate this issue, we propose to use data augmentation to generate more data for training. In addition to the data augmentation in 2D image space, we also augment the data in 3D space. We evaluate our approach on the publicly available 7-Scenes dataset, and experiments show that it has better scene coordinate predictions and achieves state-of-the-art results in localization with improved robustness on the hardest frames (e.g., frames with repeated structures).
Knowledge Distillation Circumvents Nonlinearity for Optical Convolutional Neural Networks
Feb 26, 2021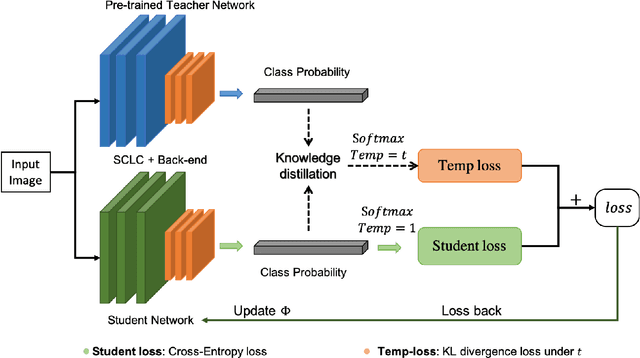
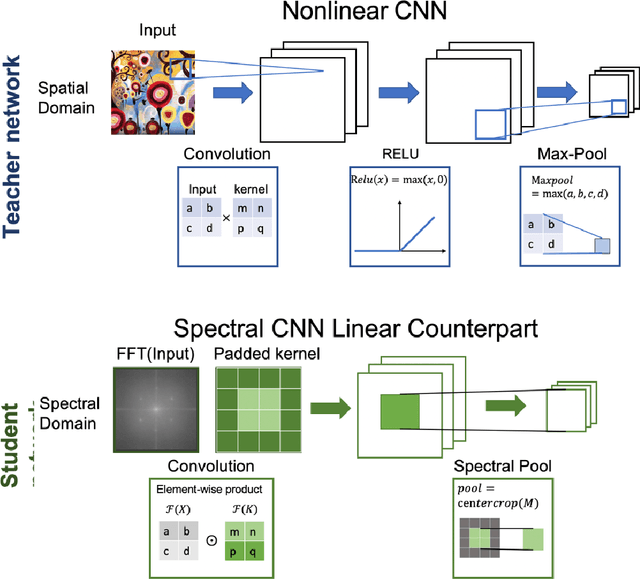
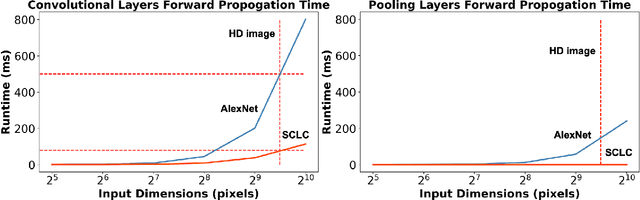
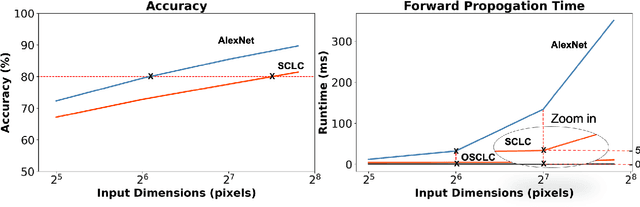
In recent years, Convolutional Neural Networks (CNNs) have enabled ubiquitous image processing applications. As such, CNNs require fast runtime (forward propagation) to process high-resolution visual streams in real time. This is still a challenging task even with state-of-the-art graphics and tensor processing units. The bottleneck in computational efficiency primarily occurs in the convolutional layers. Performing operations in the Fourier domain is a promising way to accelerate forward propagation since it transforms convolutions into elementwise multiplications, which are considerably faster to compute for large kernels. Furthermore, such computation could be implemented using an optical 4f system with orders of magnitude faster operation. However, a major challenge in using this spectral approach, as well as in an optical implementation of CNNs, is the inclusion of a nonlinearity between each convolutional layer, without which CNN performance drops dramatically. Here, we propose a Spectral CNN Linear Counterpart (SCLC) network architecture and develop a Knowledge Distillation (KD) approach to circumvent the need for a nonlinearity and successfully train such networks. While the KD approach is known in machine learning as an effective process for network pruning, we adapt the approach to transfer the knowledge from a nonlinear network (teacher) to a linear counterpart (student). We show that the KD approach can achieve performance that easily surpasses the standard linear version of a CNN and could approach the performance of the nonlinear network. Our simulations show that the possibility of increasing the resolution of the input image allows our proposed 4f optical linear network to perform more efficiently than a nonlinear network with the same accuracy on two fundamental image processing tasks: (i) object classification and (ii) semantic segmentation.