 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood, Cheap, and Fast: Overfitted Image Compression with Wasserstein Distortion
Nov 30, 2024Inspired by the success of generative image models, recent work on learned image compression increasingly focuses on better probabilistic models of the natural image distribution, leading to excellent image quality. This, however, comes at the expense of a computational complexity that is several orders of magnitude higher than today's commercial codecs, and thus prohibitive for most practical applications. With this paper, we demonstrate that by focusing on modeling visual perception rather than the data distribution, we can achieve a very good trade-off between visual quality and bit rate similar to "generative" compression models such as HiFiC, while requiring less than 1% of the multiply-accumulate operations (MACs) for decompression. We do this by optimizing C3, an overfitted image codec, for Wasserstein Distortion (WD), and evaluating the image reconstructions with a human rater study. The study also reveals that WD outperforms other perceptual quality metrics such as LPIPS, DISTS, and MS-SSIM, both as an optimization objective and as a predictor of human ratings, achieving over 94% Pearson correlation with Elo scores.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Improving fine-grained understanding in image-text pre-training
Jan 18, 2024



We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
C3: High-performance and low-complexity neural compression from a single image or video
Dec 05, 2023Most neural compression models are trained on large datasets of images or videos in order to generalize to unseen data. Such generalization typically requires large and expressive architectures with a high decoding complexity. Here we introduce C3, a neural compression method with strong rate-distortion (RD) performance that instead overfits a small model to each image or video separately. The resulting decoding complexity of C3 can be an order of magnitude lower than neural baselines with similar RD performance. C3 builds on COOL-CHIC (Ladune et al.) and makes several simple and effective improvements for images. We further develop new methodology to apply C3 to videos. On the CLIC2020 image benchmark, we match the RD performance of VTM, the reference implementation of the H.266 codec, with less than 3k MACs/pixel for decoding. On the UVG video benchmark, we match the RD performance of the Video Compression Transformer (Mentzer et al.), a well-established neural video codec, with less than 5k MACs/pixel for decoding.
Spatial Functa: Scaling Functa to ImageNet Classification and Generation
Feb 09, 2023



Neural fields, also known as implicit neural representations, have emerged as a powerful means to represent complex signals of various modalities. Based on this Dupont et al. (2022) introduce a framework that views neural fields as data, termed *functa*, and proposes to do deep learning directly on this dataset of neural fields. In this work, we show that the proposed framework faces limitations when scaling up to even moderately complex datasets such as CIFAR-10. We then propose *spatial functa*, which overcome these limitations by using spatially arranged latent representations of neural fields, thereby allowing us to scale up the approach to ImageNet-1k at 256x256 resolution. We demonstrate competitive performance to Vision Transformers (Steiner et al., 2022) on classification and Latent Diffusion (Rombach et al., 2022) on image generation respectively.
Regularising for invariance to data augmentation improves supervised learning
Mar 07, 2022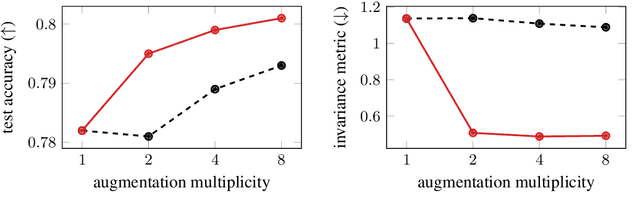
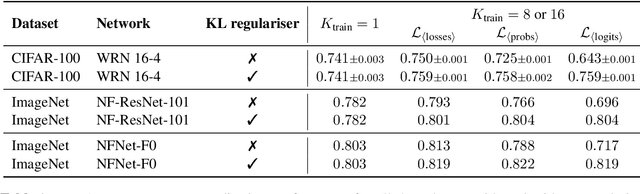
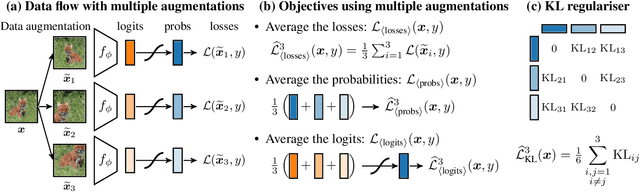
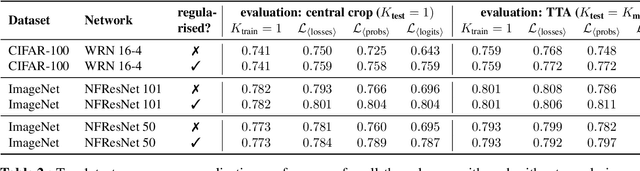
Data augmentation is used in machine learning to make the classifier invariant to label-preserving transformations. Usually this invariance is only encouraged implicitly by including a single augmented input during training. However, several works have recently shown that using multiple augmentations per input can improve generalisation or can be used to incorporate invariances more explicitly. In this work, we first empirically compare these recently proposed objectives that differ in whether they rely on explicit or implicit regularisation and at what level of the predictor they encode the invariances. We show that the predictions of the best performing method are also the most similar when compared on different augmentations of the same input. Inspired by this observation, we propose an explicit regulariser that encourages this invariance on the level of individual model predictions. Through extensive experiments on CIFAR-100 and ImageNet we show that this explicit regulariser (i) improves generalisation and (ii) equalises performance differences between all considered objectives. Our results suggest that objectives that encourage invariance on the level of the neural network itself generalise better than those that achieve invariance by averaging predictions of non-invariant models.
Laplace Redux -- Effortless Bayesian Deep Learning
Jun 28, 2021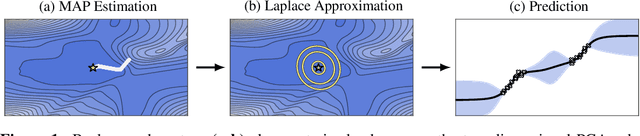
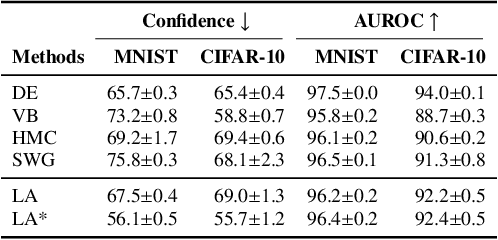
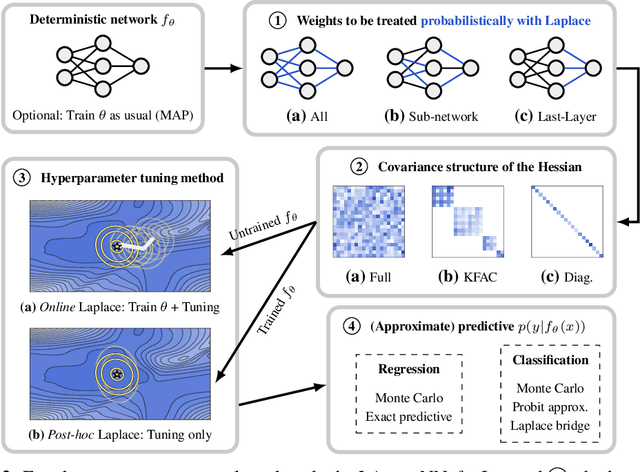
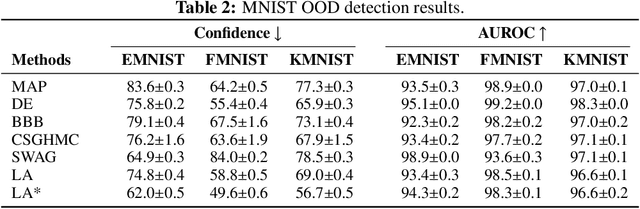
Bayesian formulations of deep learning have been shown to have compelling theoretical properties and offer practical functional benefits, such as improved predictive uncertainty quantification and model selection. The Laplace approximation (LA) is a classic, and arguably the simplest family of approximations for the intractable posteriors of deep neural networks. Yet, despite its simplicity, the LA is not as popular as alternatives like variational Bayes or deep ensembles. This may be due to assumptions that the LA is expensive due to the involved Hessian computation, that it is difficult to implement, or that it yields inferior results. In this work we show that these are misconceptions: we (i) review the range of variants of the LA including versions with minimal cost overhead; (ii) introduce "laplace", an easy-to-use software library for PyTorch offering user-friendly access to all major flavors of the LA; and (iii) demonstrate through extensive experiments that the LA is competitive with more popular alternatives in terms of performance, while excelling in terms of computational cost. We hope that this work will serve as a catalyst to a wider adoption of the LA in practical deep learning, including in domains where Bayesian approaches are not typically considered at the moment.
Scalable Marginal Likelihood Estimation for Model Selection in Deep Learning
May 11, 2021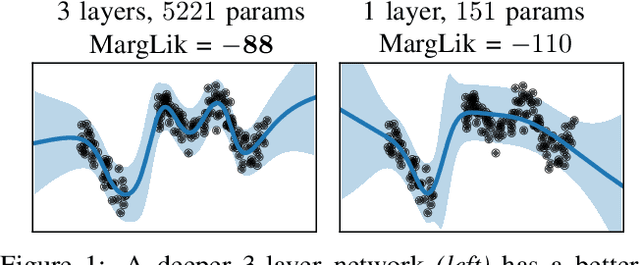
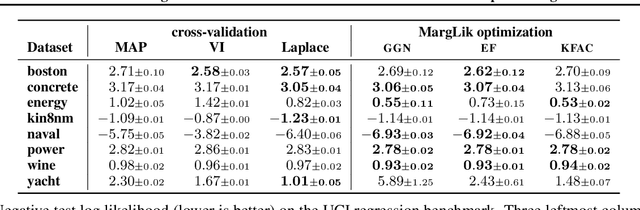
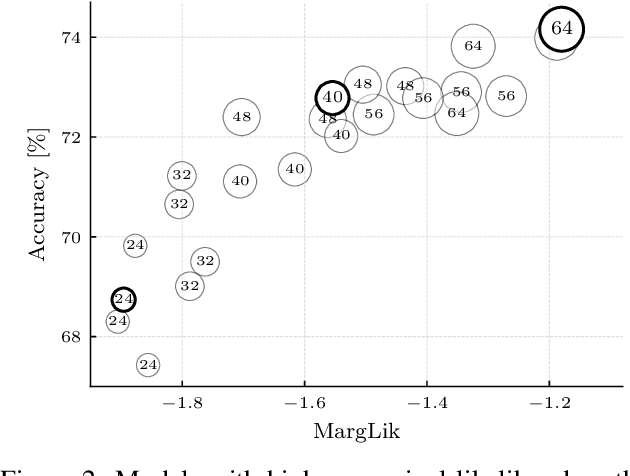
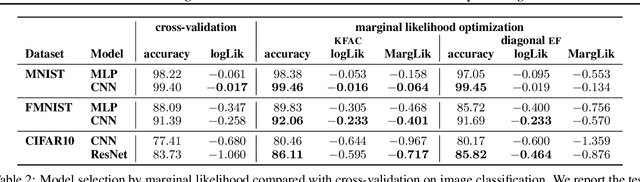
Marginal-likelihood based model-selection, even though promising, is rarely used in deep learning due to estimation difficulties. Instead, most approaches rely on validation data, which may not be readily available. In this work, we present a scalable marginal-likelihood estimation method to select both the hyperparameters and network architecture based on the training data alone. Some hyperparameters can be estimated online during training, simplifying the procedure. Our marginal-likelihood estimate is based on Laplace's method and Gauss-Newton approximations to the Hessian, and it outperforms cross-validation and manual-tuning on standard regression and image classification datasets, especially in terms of calibration and out-of-distribution detection. Our work shows that marginal likelihoods can improve generalization and be useful when validation data is unavailable (e.g., in nonstationary settings).
Generalized Doubly Reparameterized Gradient Estimators
Jan 26, 2021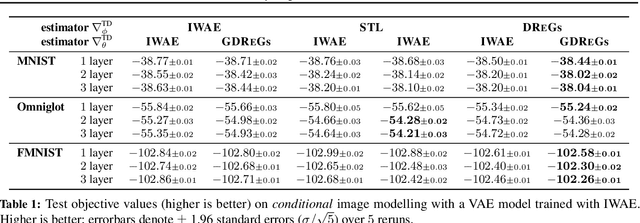

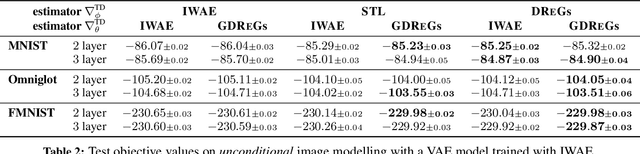

Efficient low-variance gradient estimation enabled by the reparameterization trick (RT) has been essential to the success of variational autoencoders. Doubly-reparameterized gradients (DReGs) improve on the RT for multi-sample variational bounds by applying reparameterization a second time for an additional reduction in variance. Here, we develop two generalizations of the DReGs estimator and show that they can be used to train conditional and hierarchical VAEs on image modelling tasks more effectively. We first extend the estimator to hierarchical models with several stochastic layers by showing how to treat additional score function terms due to the hierarchical variational posterior. We then generalize DReGs to score functions of arbitrary distributions instead of just those of the sampling distribution, which makes the estimator applicable to the parameters of the prior in addition to those of the posterior.