 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepImageSpam: Deep Learning based Image Spam Detection
Oct 03, 2018

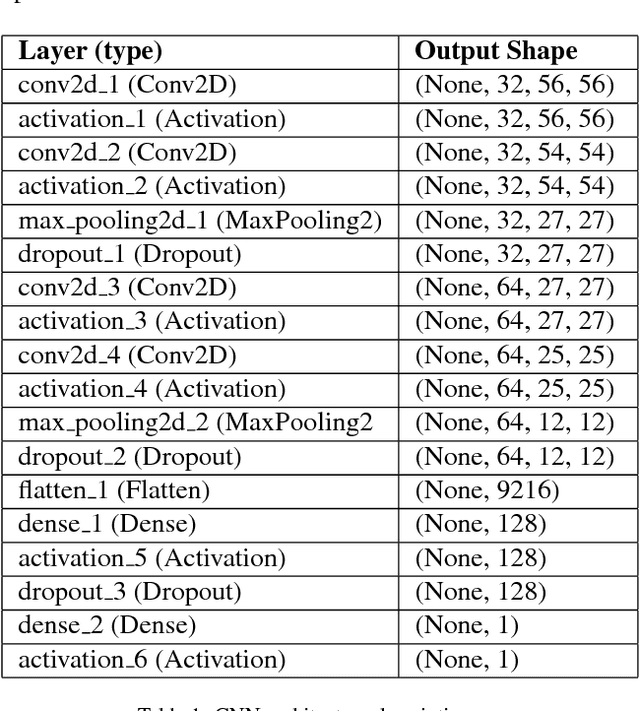

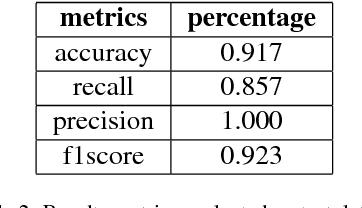
Hackers and spammers are employing innovative and novel techniques to deceive novice and even knowledgeable internet users. Image spam is one of such technique where the spammer varies and changes some portion of the image such that it is indistinguishable from the original image fooling the users. This paper proposes a deep learning based approach for image spam detection using the convolutional neural networks which uses a dataset with 810 natural images and 928 spam images for classification achieving an accuracy of 91.7% outperforming the existing image processing and machine learning techniques
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
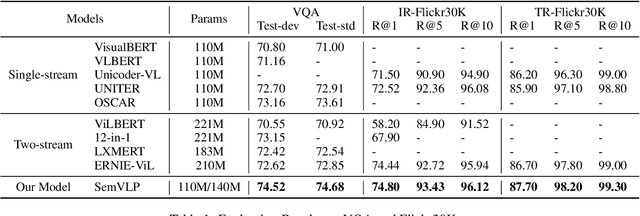
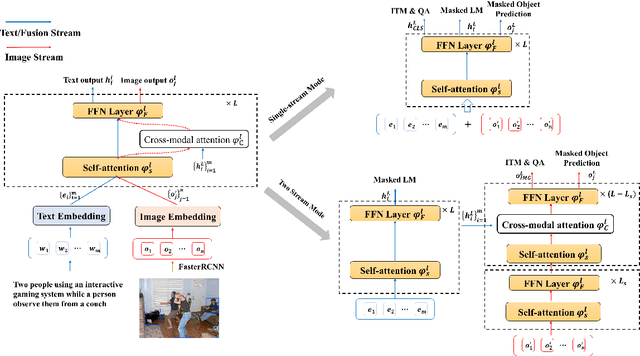

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Jun 04, 2021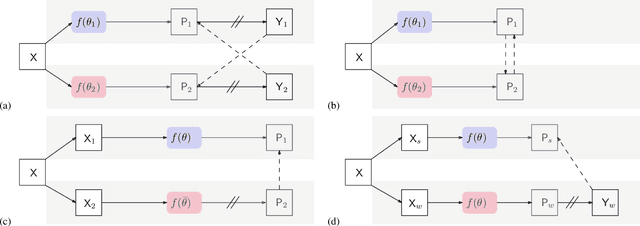
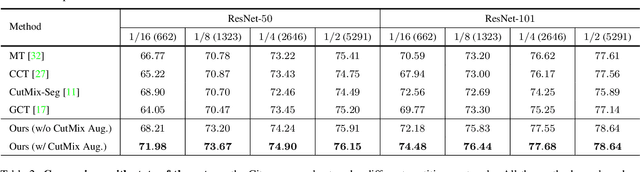
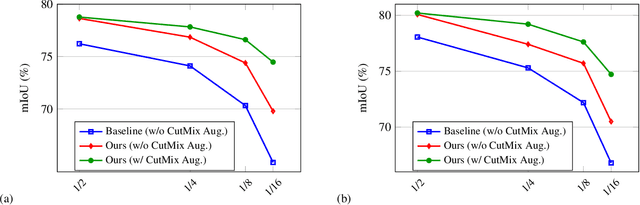
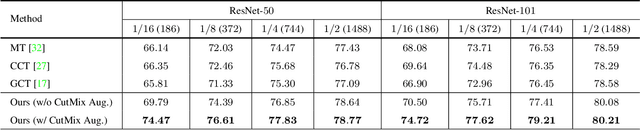
In this paper, we study the semi-supervised semantic segmentation problem via exploring both labeled data and extra unlabeled data. We propose a novel consistency regularization approach, called cross pseudo supervision (CPS). Our approach imposes the consistency on two segmentation networks perturbed with different initialization for the same input image. The pseudo one-hot label map, output from one perturbed segmentation network, is used to supervise the other segmentation network with the standard cross-entropy loss, and vice versa. The CPS consistency has two roles: encourage high similarity between the predictions of two perturbed networks for the same input image, and expand training data by using the unlabeled data with pseudo labels. Experiment results show that our approach achieves the state-of-the-art semi-supervised segmentation performance on Cityscapes and PASCAL VOC 2012. Code is available at https://git.io/CPS.
Learning Multimodal Affinities for Textual Editing in Images
Mar 18, 2021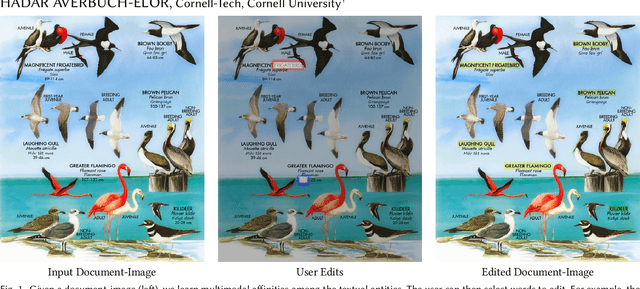
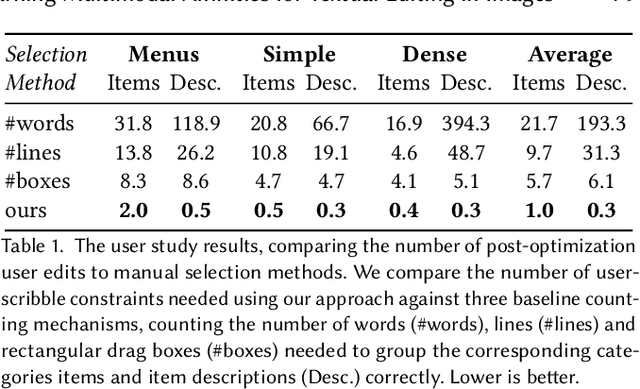
Nowadays, as cameras are rapidly adopted in our daily routine, images of documents are becoming both abundant and prevalent. Unlike natural images that capture physical objects, document-images contain a significant amount of text with critical semantics and complicated layouts. In this work, we devise a generic unsupervised technique to learn multimodal affinities between textual entities in a document-image, considering their visual style, the content of their underlying text and their geometric context within the image. We then use these learned affinities to automatically cluster the textual entities in the image into different semantic groups. The core of our approach is a deep optimization scheme dedicated for an image provided by the user that detects and leverages reliable pairwise connections in the multimodal representation of the textual elements in order to properly learn the affinities. We show that our technique can operate on highly varying images spanning a wide range of documents and demonstrate its applicability for various editing operations manipulating the content, appearance and geometry of the image.
Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge
Jan 06, 2020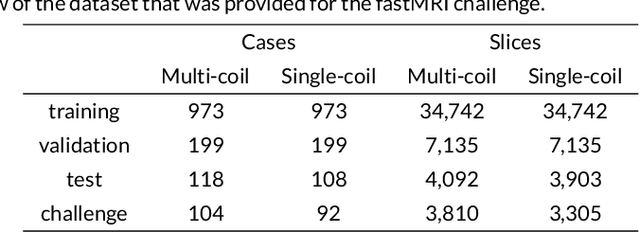
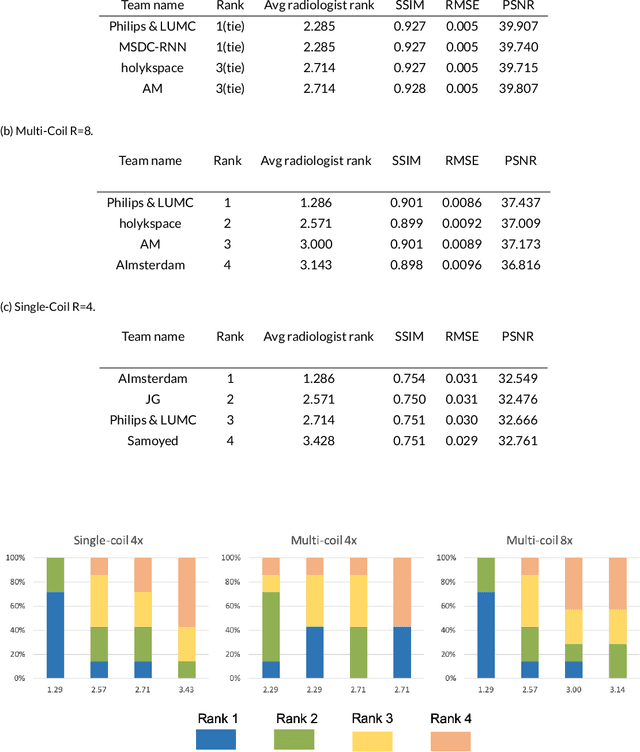

Purpose: To advance research in the field of machine learning for MR image reconstruction with an open challenge. Methods: We provided participants with a dataset of raw k-space data from 1,594 consecutive clinical exams of the knee. The goal of the challenge was to reconstruct images from these data. In order to strike a balance between realistic data and a shallow learning curve for those not already familiar with MR image reconstruction, we ran multiple tracks for multi-coil and single-coil data. We performed a two-stage evaluation based on quantitative image metrics followed by evaluation by a panel of radiologists. The challenge ran from June to December of 2019. Results: We received a total of 33 challenge submissions. All participants chose to submit results from supervised machine learning approaches. Conclusion: The challenge led to new developments in machine learning for image reconstruction, provided insight into the current state of the art in the field, and highlighted remaining hurdles for clinical adoption.
PASS: An ImageNet replacement for self-supervised pretraining without humans
Sep 27, 2021


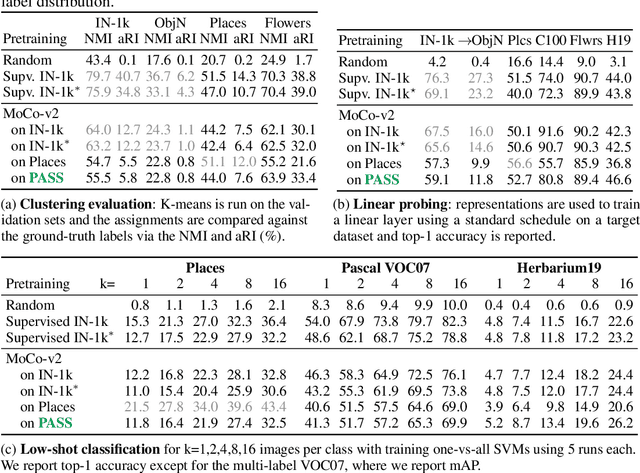
Computer vision has long relied on ImageNet and other large datasets of images sampled from the Internet for pretraining models. However, these datasets have ethical and technical shortcomings, such as containing personal information taken without consent, unclear license usage, biases, and, in some cases, even problematic image content. On the other hand, state-of-the-art pretraining is nowadays obtained with unsupervised methods, meaning that labelled datasets such as ImageNet may not be necessary, or perhaps not even optimal, for model pretraining. We thus propose an unlabelled dataset PASS: Pictures without humAns for Self-Supervision. PASS only contains images with CC-BY license and complete attribution metadata, addressing the copyright issue. Most importantly, it contains no images of people at all, and also avoids other types of images that are problematic for data protection or ethics. We show that PASS can be used for pretraining with methods such as MoCo-v2, SwAV and DINO. In the transfer learning setting, it yields similar downstream performances to ImageNet pretraining even on tasks that involve humans, such as human pose estimation. PASS does not make existing datasets obsolete, as for instance it is insufficient for benchmarking. However, it shows that model pretraining is often possible while using safer data, and it also provides the basis for a more robust evaluation of pretraining methods.
Image-Based Feature Representation for Insider Threat Classification
Nov 13, 2019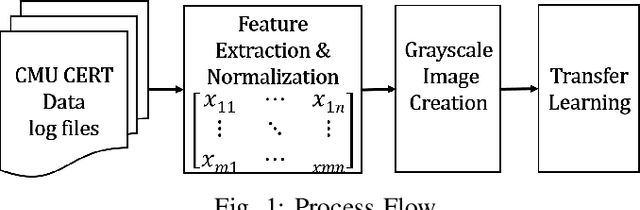
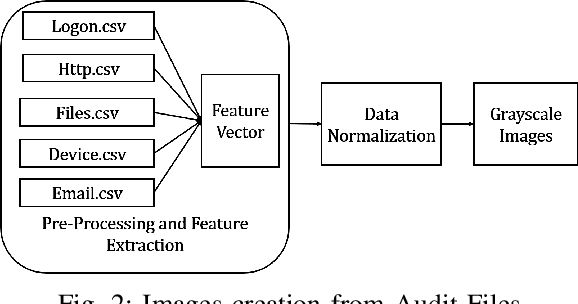

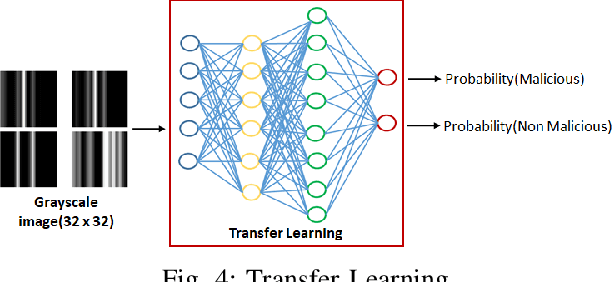
Insiders are the trusted entities in the organization, but poses threat to the with access to sensitive information network and resources. The insider threat detection is a well studied problem in security analytics. Identifying the features from data sources and using them with the right data analytics algorithms makes various kinds of threat analysis possible. The insider threat analysis is mainly done using the frequency based attributes extracted from the raw data available from data sources. In this paper, we propose an image-based feature representation of the daily resource usage pattern of users in the organization. The features extracted from the audit files of the organization are represented as gray scale images. Hence, these images are used to represent the resource access patterns and thereby the behavior of users. Classification models are applied to the representative images to detect anomalous behavior of insiders. The images are classified to malicious and non-malicious. The effectiveness of the proposed representation is evaluated using the CMU CERT data V4.2, and state-of-art image classification models like Mobilenet, VGG and ResNet. The experimental results showed improved accuracy. The comparison with existing works show a performance improvement in terms of high recall and precision values.
Robust Reference-based Super-Resolution via C2-Matching
Jun 03, 2021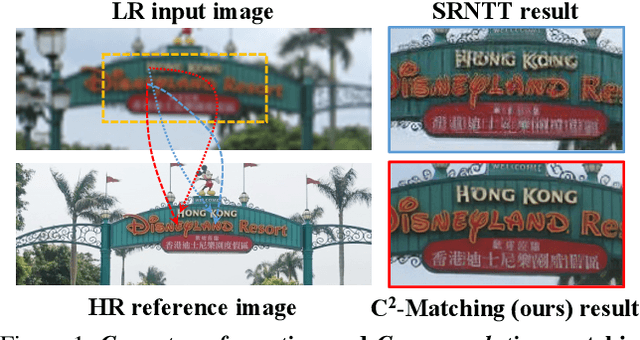
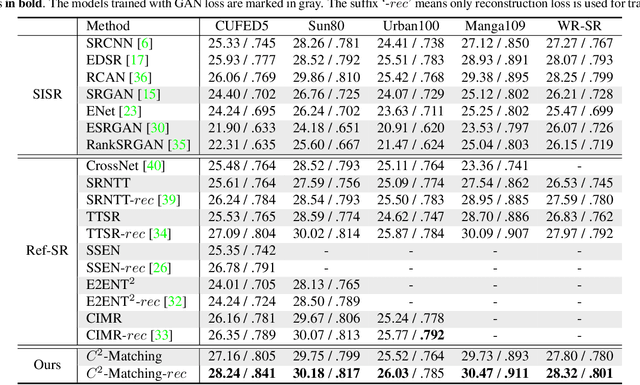
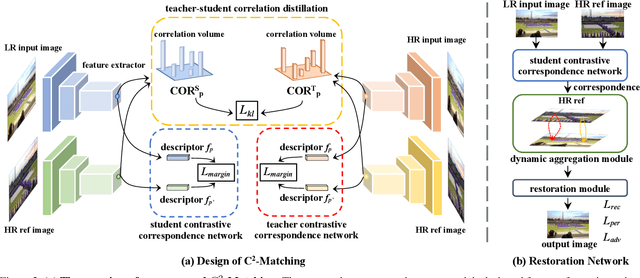
Reference-based Super-Resolution (Ref-SR) has recently emerged as a promising paradigm to enhance a low-resolution (LR) input image by introducing an additional high-resolution (HR) reference image. Existing Ref-SR methods mostly rely on implicit correspondence matching to borrow HR textures from reference images to compensate for the information loss in input images. However, performing local transfer is difficult because of two gaps between input and reference images: the transformation gap (e.g. scale and rotation) and the resolution gap (e.g. HR and LR). To tackle these challenges, we propose C2-Matching in this work, which produces explicit robust matching crossing transformation and resolution. 1) For the transformation gap, we propose a contrastive correspondence network, which learns transformation-robust correspondences using augmented views of the input image. 2) For the resolution gap, we adopt a teacher-student correlation distillation, which distills knowledge from the easier HR-HR matching to guide the more ambiguous LR-HR matching. 3) Finally, we design a dynamic aggregation module to address the potential misalignment issue. In addition, to faithfully evaluate the performance of Ref-SR under a realistic setting, we contribute the Webly-Referenced SR (WR-SR) dataset, mimicking the practical usage scenario. Extensive experiments demonstrate that our proposed C2-Matching significantly outperforms state of the arts by over 1dB on the standard CUFED5 benchmark. Notably, it also shows great generalizability on WR-SR dataset as well as robustness across large scale and rotation transformations.
Multiple instance dense connected convolution neural network for aerial image scene classification
Aug 22, 2019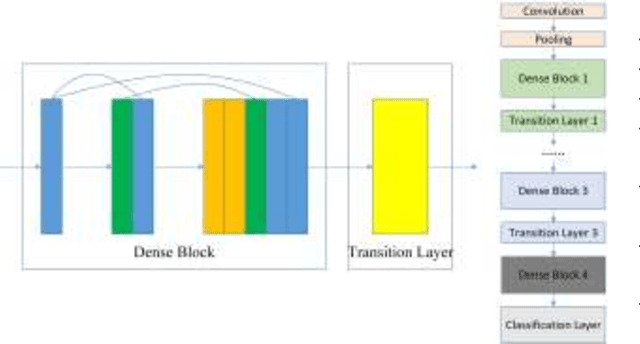
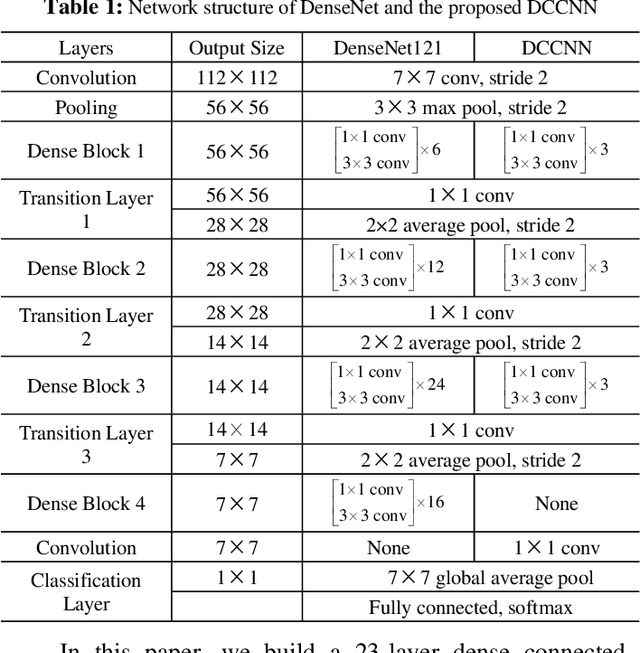
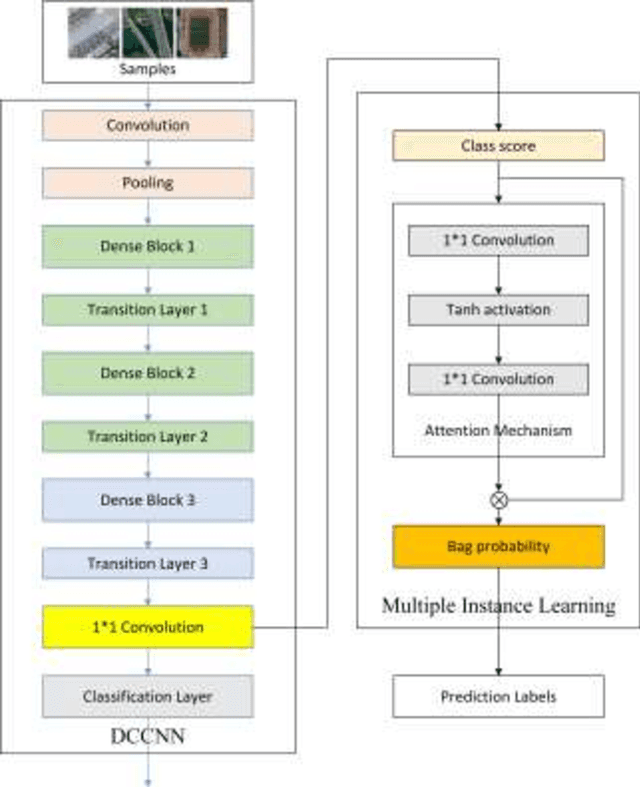
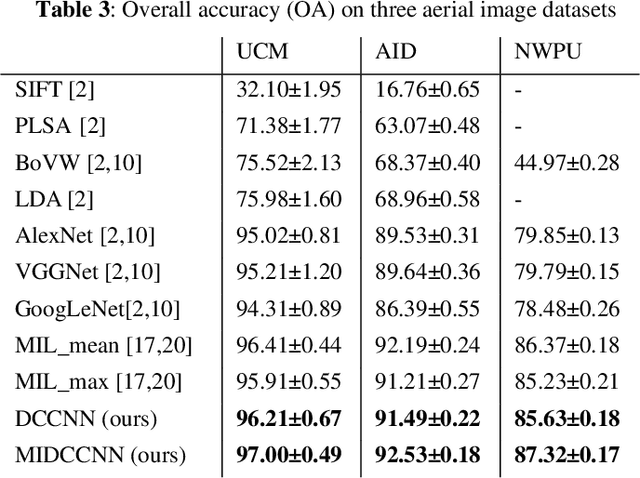
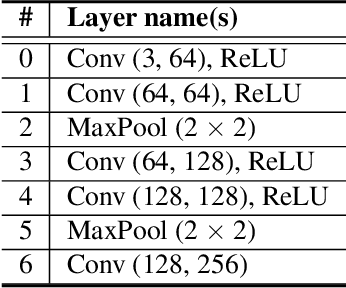
With the development of deep learning, many state-of-the-art natural image scene classification methods have demonstrated impressive performance. While the current convolution neural network tends to extract global features and global semantic information in a scene, the geo-spatial objects can be located at anywhere in an aerial image scene and their spatial arrangement tends to be more complicated. One possible solution is to preserve more local semantic information and enhance feature propagation. In this paper, an end to end multiple instance dense connected convolution neural network (MIDCCNN) is proposed for aerial image scene classification. First, a 23 layer dense connected convolution neural network (DCCNN) is built and served as a backbone to extract convolution features. It is capable of preserving middle and low level convolution features. Then, an attention based multiple instance pooling is proposed to highlight the local semantics in an aerial image scene. Finally, we minimize the loss between the bag-level predictions and the ground truth labels so that the whole framework can be trained directly. Experiments on three aerial image datasets demonstrate that our proposed methods can outperform current baselines by a large margin.
Image classification in frequency domain with 2SReLU: a second harmonics superposition activation function
Jun 18, 2020

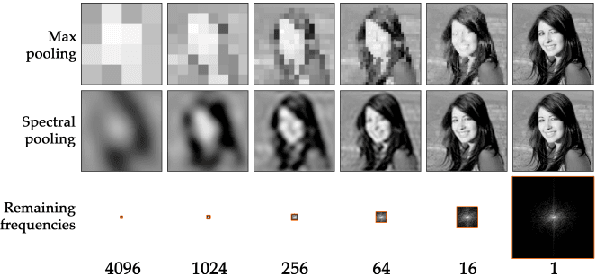
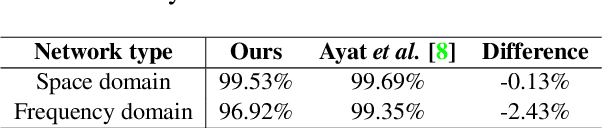
Deep Convolutional Neural Networks are able to identify complex patterns and perform tasks with super-human capabilities. However, besides the exceptional results, they are not completely understood and it is still impractical to hand-engineer similar solutions. In this work, an image classification Convolutional Neural Network and its building blocks are described from a frequency domain perspective. Some network layers have established counterparts in the frequency domain like the convolutional and pooling layers. We propose the 2SReLU layer, a novel non-linear activation function that preserves high frequency components in deep networks. It is demonstrated that in the frequency domain it is possible to achieve competitive results without using the computationally costly convolution operation. A source code implementation in PyTorch is provided at: https://gitlab.com/thomio/2srelu