 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Instance Priors Help Weakly Supervised Semantic Segmentation?
Apr 13, 2026Semantic segmentation requires dense pixel-level annotations, which are costly and time-consuming to acquire. To address this, we present SeSAM, a framework that uses a foundational segmentation model, i.e. Segment Anything Model (SAM), with weak labels, including coarse masks, scribbles, and points. SAM, originally designed for instance-based segmentation, cannot be directly used for semantic segmentation tasks. In this work, we identify specific challenges faced by SAM and determine appropriate components to adapt it for class-based segmentation using weak labels. Specifically, SeSAM decomposes class masks into connected components, samples point prompts along object skeletons, selects SAM masks using weak-label coverage, and iteratively refines labels using pseudo-labels, enabling SAM-generated masks to be effectively used for semantic segmentation. Integrated with a semi-supervised learning framework, SeSAM balances ground-truth labels, SAM-based pseudo-labels, and high-confidence pseudo-labels, significantly improving segmentation quality. Extensive experiments across multiple benchmarks and weak annotation types show that SeSAM consistently outperforms weakly supervised baselines while substantially reducing annotation cost relative to fine supervision.
Steerable Visual Representations
Apr 02, 2026Pretrained Vision Transformers (ViTs) such as DINOv2 and MAE provide generic image features that can be applied to a variety of downstream tasks such as retrieval, classification, and segmentation. However, such representations tend to focus on the most salient visual cues in the image, with no way to direct them toward less prominent concepts of interest. In contrast, Multimodal LLMs can be guided with textual prompts, but the resulting representations tend to be language-centric and lose their effectiveness for generic visual tasks. To address this, we introduce Steerable Visual Representations, a new class of visual representations, whose global and local features can be steered with natural language. While most vision-language models (e.g., CLIP) fuse text with visual features after encoding (late fusion), we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention. We introduce benchmarks for measuring representational steerability, and demonstrate that our steerable visual features can focus on any desired objects in an image while preserving the underlying representation quality. Our method also matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination, exhibiting zero-shot generalization to out-of-distribution tasks.
MoireMix: A Formula-Based Data Augmentation for Improving Image Classification Robustness
Mar 26, 2026Data augmentation is a key technique for improving the robustness of image classification models. However, many recent approaches rely on diffusion-based synthesis or complex feature mixing strategies, which introduce substantial computational overhead or require external datasets. In this work, we explore a different direction: procedural augmentation based on analytic interference patterns. Unlike conventional augmentation methods that rely on stochastic noise, feature mixing, or generative models, our approach exploits Moire interference to generate structured perturbations spanning a wide range of spatial frequencies. We propose a lightweight augmentation method that procedurally generates Moire textures on-the-fly using a closed-form mathematical formulation. The patterns are synthesized directly in memory with negligible computational cost (0.0026 seconds per image), mixed with training images during training, and immediately discarded, enabling a storage-free augmentation pipeline without external data. Extensive experiments with Vision Transformers demonstrate that the proposed method consistently improves robustness across multiple benchmarks, including ImageNet-C, ImageNet-R, and adversarial benchmarks, outperforming standard augmentation baselines and existing external-data-free augmentation approaches. These results suggest that analytic interference patterns provide a practical and efficient alternative to data-driven generative augmentation methods.
Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning
Feb 11, 2026Supervised fine-tuning (SFT) on chain-of-thought data is an essential post-training step for reasoning language models. Standard machine learning intuition suggests that training with more unique training samples yields better generalization. Counterintuitively, we show that SFT benefits from repetition: under a fixed update budget, training for more epochs on smaller datasets outperforms single-epoch training on larger datasets. On AIME'24/25 and GPQA benchmarks, Olmo3-7B trained for 128 epochs on 400 samples outperforms the equivalent 1 epoch on 51200 samples by 12-26 percentage points, with no additional catastrophic forgetting. We find that training token accuracy reliably signals when repetition has saturated; improvements from additional epochs plateau at full memorization, a pattern consistent across all settings. These findings provide a practical approach for reasoning SFT, where scaling epochs with token accuracy as a stopping criterion can replace expensive undirected data scaling. We pose the repetition advantage, where full memorization coincides with improved generalization, as a new open problem for the community in understanding the training dynamics of large language models.
Private PoEtry: Private In-Context Learning via Product of Experts
Feb 04, 2026In-context learning (ICL) enables Large Language Models (LLMs) to adapt to new tasks with only a small set of examples at inference time, thereby avoiding task-specific fine-tuning. However, in-context examples may contain privacy-sensitive information that should not be revealed through model outputs. Existing differential privacy (DP) approaches to ICL are either computationally expensive or rely on heuristics with limited effectiveness, including context oversampling, synthetic data generation, or unnecessary thresholding. We reformulate private ICL through the lens of a Product-of-Experts model. This gives a theoretically grounded framework, and the algorithm can be trivially parallelized. We evaluate our method across five datasets in text classification, math, and vision-language. We find that our method improves accuracy by more than 30 percentage points on average compared to prior DP-ICL methods, while maintaining strong privacy guarantees.
3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
Dec 28, 2025Despite recent progress in 3D self-supervised learning, collecting large-scale 3D scene scans remains expensive and labor-intensive. In this work, we investigate whether 3D representations can be learned from unlabeled videos recorded without any real 3D sensors. We present Laplacian-Aware Multi-level 3D Clustering with Sinkhorn-Knopp (LAM3C), a self-supervised framework that learns from video-generated point clouds from unlabeled videos. We first introduce RoomTours, a video-generated point cloud dataset constructed by collecting room-walkthrough videos from the web (e.g., real-estate tours) and generating 49,219 scenes using an off-the-shelf feed-forward reconstruction model. We also propose a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Remarkably, without using any real 3D scans, LAM3C achieves higher performance than the previous self-supervised methods on indoor semantic and instance segmentation. These results suggest that unlabeled videos represent an abundant source of data for 3D self-supervised learning.
Test-Time Modification: Inverse Domain Transformation for Robust Perception
Dec 15, 2025



Generative foundation models contain broad visual knowledge and can produce diverse image variations, making them particularly promising for advancing domain generalization tasks. While they can be used for training data augmentation, synthesizing comprehensive target-domain variations remains slow, expensive, and incomplete. We propose an alternative: using diffusion models at test time to map target images back to the source distribution where the downstream model was trained. This approach requires only a source domain description, preserves the task model, and eliminates large-scale synthetic data generation. We demonstrate consistent improvements across segmentation, detection, and classification tasks under challenging environmental shifts in real-to-real domain generalization scenarios with unknown target distributions. Our analysis spans multiple generative and downstream models, including an ensemble variant for enhanced robustness. The method achieves substantial relative gains: 137% on BDD100K-Night, 68% on ImageNet-R, and 62% on DarkZurich.
Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs
Dec 09, 2025We introduce two new benchmarks REST and REST+(Render-Equivalence Stress Tests) to enable systematic evaluation of cross-modal inconsistency in multimodal large language models (MLLMs). MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. Our benchmarks contain samples with the same semantic information in three modalities (image, text, mixed) and we show that state-of-the-art MLLMs cannot consistently reason over these different modalities. We evaluate 15 MLLMs and find that the degree of modality inconsistency varies substantially, even when accounting for problems with text recognition (OCR). Neither rendering text as image nor rendering an image as text solves the inconsistency. Even if OCR is correct, we find that visual characteristics (text colour and resolution, but not font) and the number of vision tokens have an impact on model performance. Finally, we find that our consistency score correlates with the modality gap between text and images, highlighting a mechanistic interpretation of cross-modal inconsistent MLLMs.
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Jul 18, 2025



We present Franca (pronounced Fran-ka): free one; the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2, etc. Our approach is grounded in a transparent training pipeline inspired by Web-SSL and uses publicly available data: ImageNet-21K and a subset of ReLAION-2B. Beyond model release, we tackle critical limitations in SSL clustering methods. While modern models rely on assigning image features to large codebooks via clustering algorithms like Sinkhorn-Knopp, they fail to account for the inherent ambiguity in clustering semantics. To address this, we introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations. This design progressively refines features into increasingly fine-grained clusters without increasing the model size, enabling both performance and memory efficiency. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, thereby improving the encoding of semantic content. This leads to consistent gains on several downstream benchmarks, demonstrating the utility of cleaner feature spaces. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models for the broader AI community. The code and model checkpoints are available at https://github.com/valeoai/Franca.
Segment Any 3D-Part in a Scene from a Sentence
Jun 24, 2025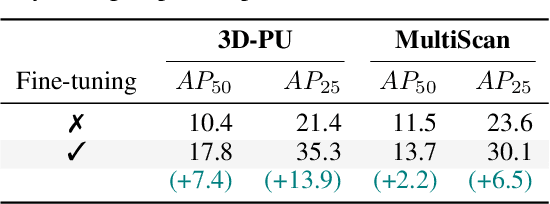
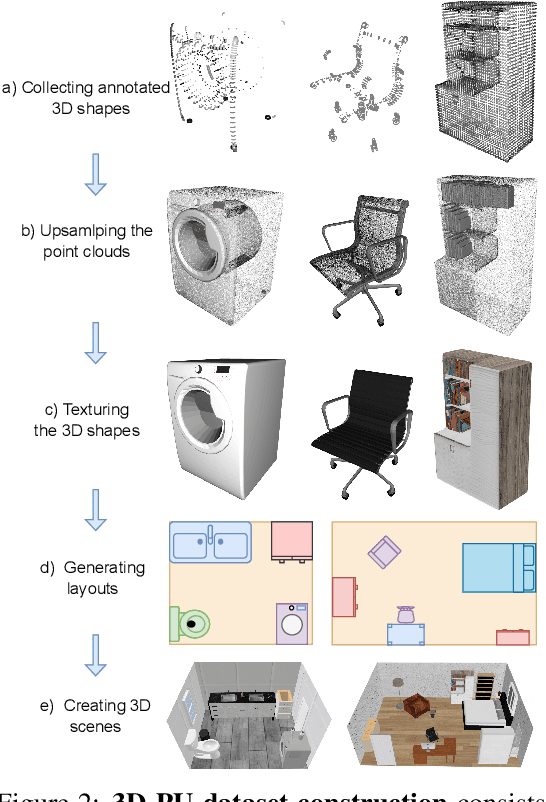


This paper aims to achieve the segmentation of any 3D part in a scene based on natural language descriptions, extending beyond traditional object-level 3D scene understanding and addressing both data and methodological challenges. Due to the expensive acquisition and annotation burden, existing datasets and methods are predominantly limited to object-level comprehension. To overcome the limitations of data and annotation availability, we introduce the 3D-PU dataset, the first large-scale 3D dataset with dense part annotations, created through an innovative and cost-effective method for constructing synthetic 3D scenes with fine-grained part-level annotations, paving the way for advanced 3D-part scene understanding. On the methodological side, we propose OpenPart3D, a 3D-input-only framework to effectively tackle the challenges of part-level segmentation. Extensive experiments demonstrate the superiority of our approach in open-vocabulary 3D scene understanding tasks at the part level, with strong generalization capabilities across various 3D scene datasets.