 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Local Augmentation for Graph Neural Networks
Sep 08, 2021
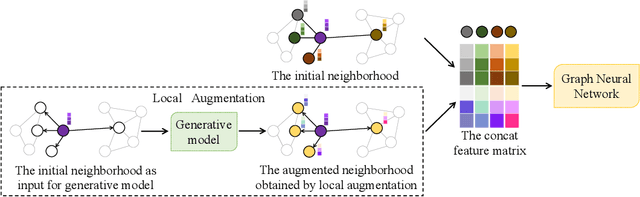
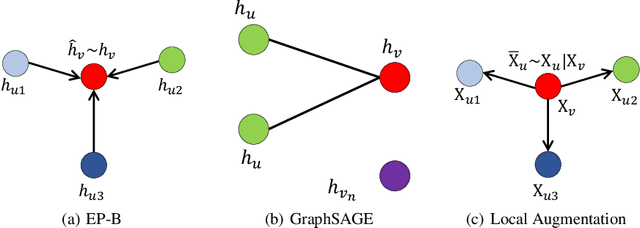

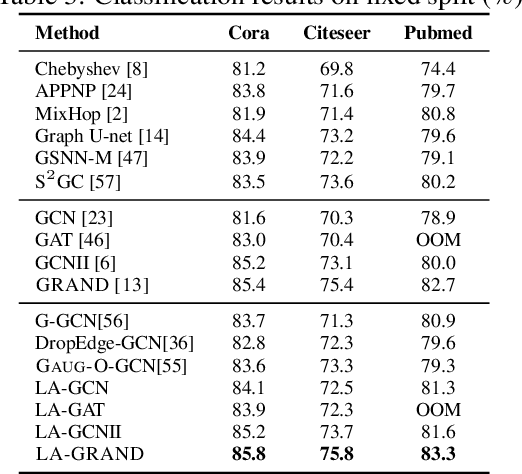
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
fastMRI+: Clinical Pathology Annotations for Knee and Brain Fully Sampled Multi-Coil MRI Data
Sep 08, 2021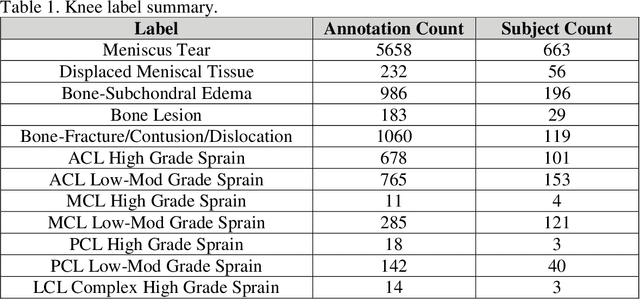
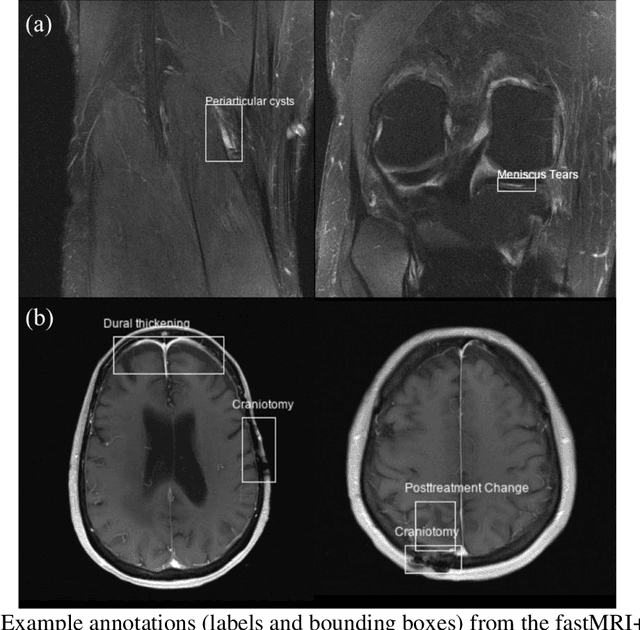
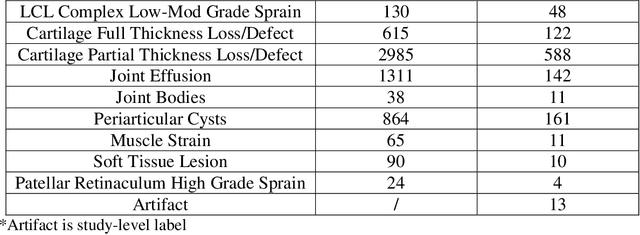
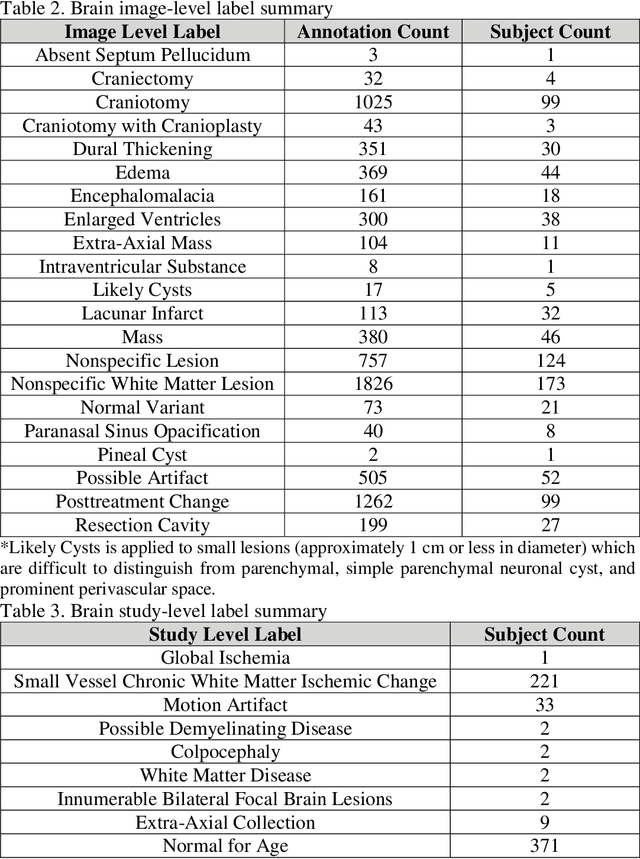
Improving speed and image quality of Magnetic Resonance Imaging (MRI) via novel reconstruction approaches remains one of the highest impact applications for deep learning in medical imaging. The fastMRI dataset, unique in that it contains large volumes of raw MRI data, has enabled significant advances in accelerating MRI using deep learning-based reconstruction methods. While the impact of the fastMRI dataset on the field of medical imaging is unquestioned, the dataset currently lacks clinical expert pathology annotations, critical to addressing clinically relevant reconstruction frameworks and exploring important questions regarding rendering of specific pathology using such novel approaches. This work introduces fastMRI+, which consists of 16154 subspecialist expert bounding box annotations and 13 study-level labels for 22 different pathology categories on the fastMRI knee dataset, and 7570 subspecialist expert bounding box annotations and 643 study-level labels for 30 different pathology categories for the fastMRI brain dataset. The fastMRI+ dataset is open access and aims to support further research and advancement of medical imaging in MRI reconstruction and beyond.
A Survey on Machine Learning Techniques for Auto Labeling of Video, Audio, and Text Data
Sep 08, 2021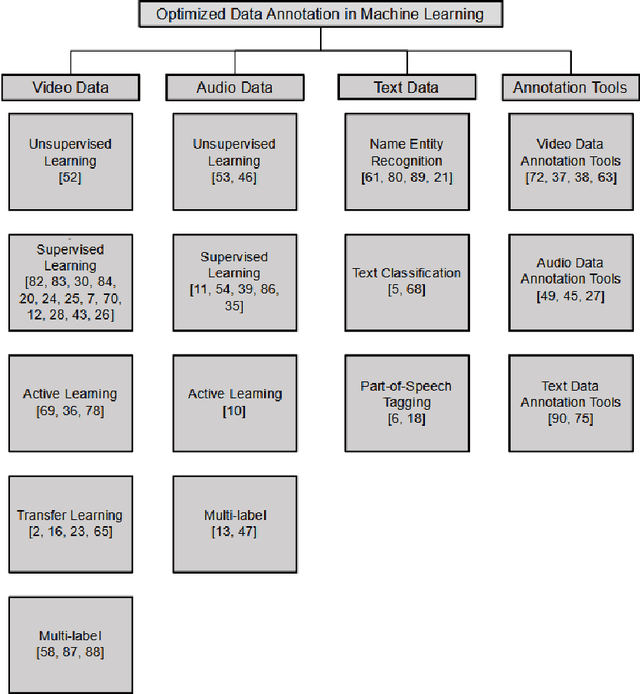
Machine learning has been utilized to perform tasks in many different domains such as classification, object detection, image segmentation and natural language analysis. Data labeling has always been one of the most important tasks in machine learning. However, labeling large amounts of data increases the monetary cost in machine learning. As a result, researchers started to focus on reducing data annotation and labeling costs. Transfer learning was designed and widely used as an efficient approach that can reasonably reduce the negative impact of limited data, which in turn, reduces the data preparation cost. Even transferring previous knowledge from a source domain reduces the amount of data needed in a target domain. However, large amounts of annotated data are still demanded to build robust models and improve the prediction accuracy of the model. Therefore, researchers started to pay more attention on auto annotation and labeling. In this survey paper, we provide a review of previous techniques that focuses on optimized data annotation and labeling for video, audio, and text data.
Deep Simultaneous Optimisation of Sampling and Reconstruction for Multi-contrast MRI
Mar 31, 2021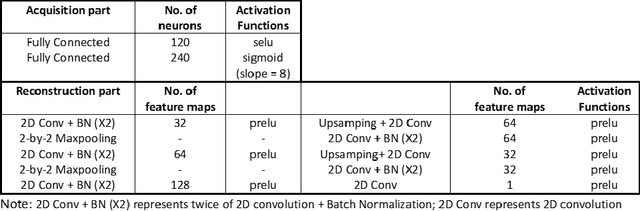
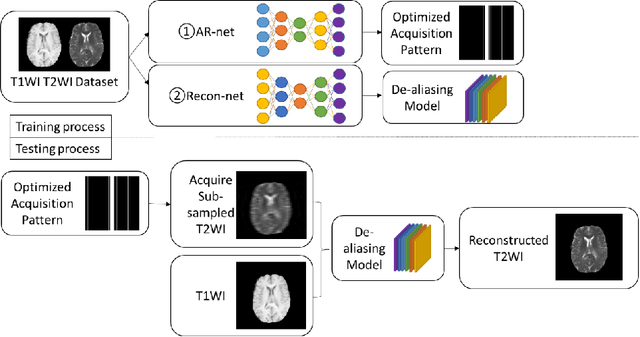
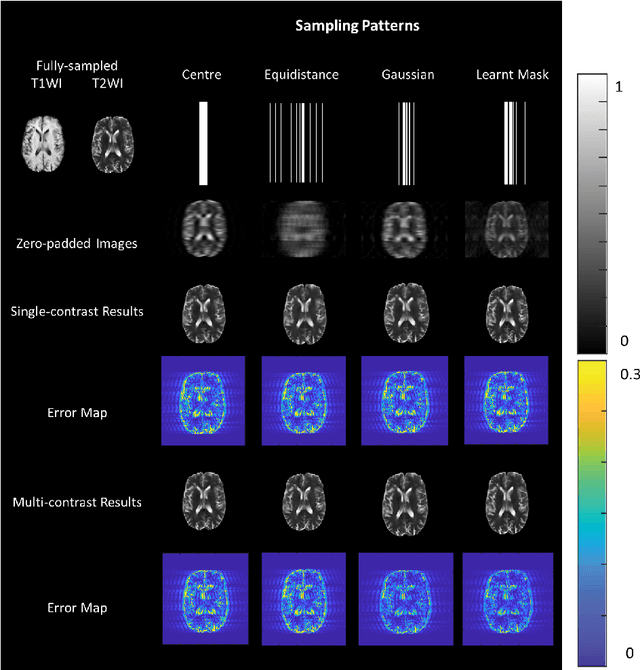
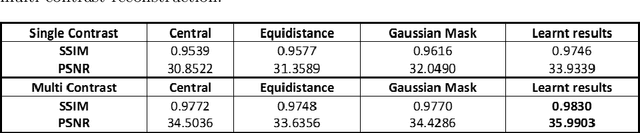
MRI images of the same subject in different contrasts contain shared information, such as the anatomical structure. Utilizing the redundant information amongst the contrasts to sub-sample and faithfully reconstruct multi-contrast images could greatly accelerate the imaging speed, improve image quality and shorten scanning protocols. We propose an algorithm that generates the optimised sampling pattern and reconstruction scheme of one contrast (e.g. T2-weighted image) when images with different contrast (e.g. T1-weighted image) have been acquired. The proposed algorithm achieves increased PSNR and SSIM with the resulting optimal sampling pattern compared to other acquisition patterns and single contrast methods.
Realistic Hands: A Hybrid Model for 3D Hand Reconstruction
Aug 31, 2021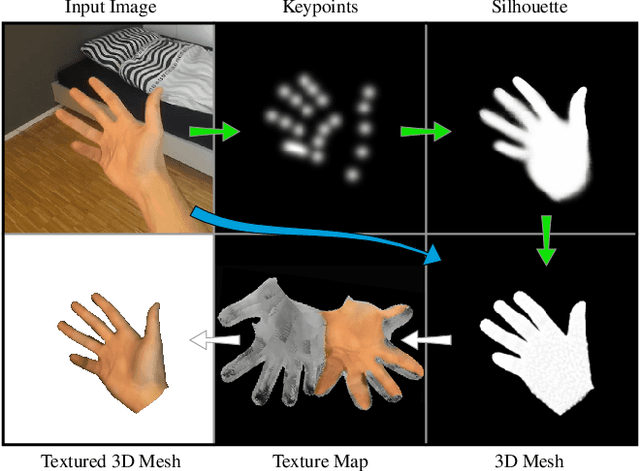
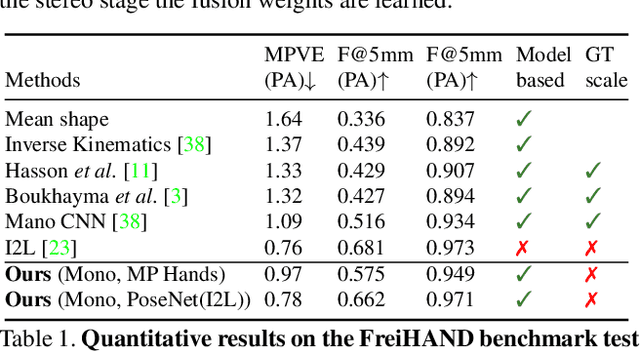
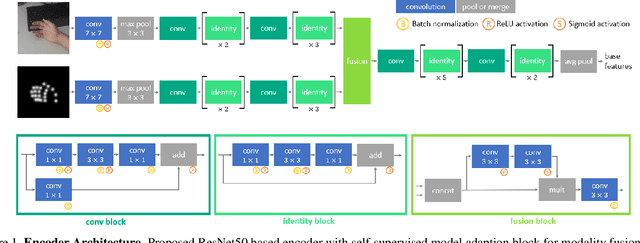
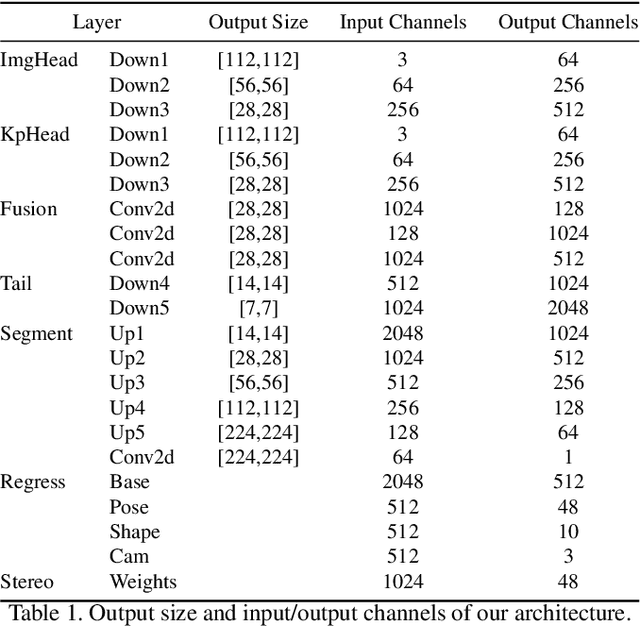
Estimating 3D hand meshes from RGB images robustly is a highly desirable task, made challenging due to the numerous degrees of freedom, and issues such as self similarity and occlusions. Previous methods generally either use parametric 3D hand models or follow a model-free approach. While the former can be considered more robust, e.g. to occlusions, they are less expressive. We propose a hybrid approach, utilizing a deep neural network and differential rendering based optimization to demonstrably achieve the best of both worlds. In addition, we explore Virtual Reality (VR) as an application. Most VR headsets are nowadays equipped with multiple cameras, which we can leverage by extending our method to the egocentric stereo domain. This extension proves to be more resilient to the above mentioned issues. Finally, as a use-case, we show that the improved image-model alignment can be used to acquire the user's hand texture, which leads to a more realistic virtual hand representation.
Self-Training Based Unsupervised Cross-Modality Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation
Sep 22, 2021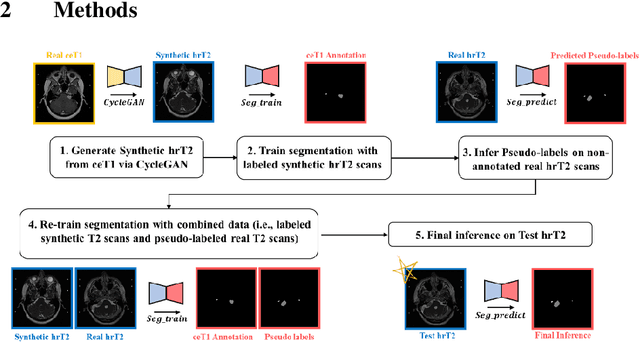
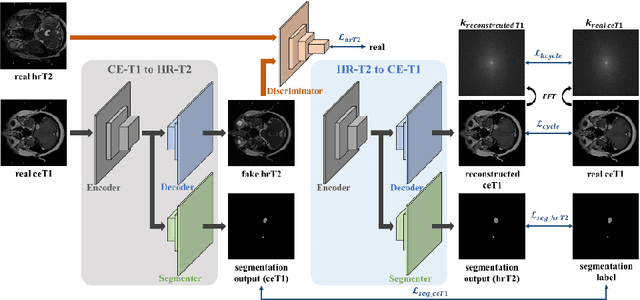
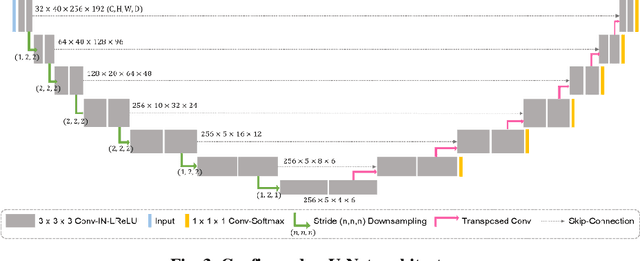
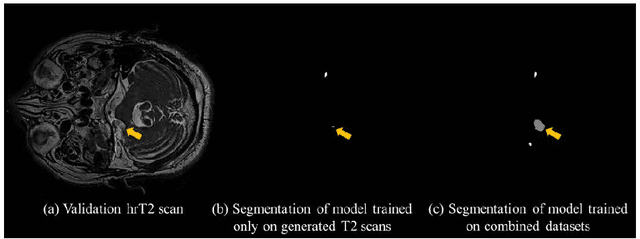
With the advances of deep learning, many medical image segmentation studies achieve human-level performance when in fully supervised condition. However, it is extremely expensive to acquire annotation on every data in medical fields, especially on magnetic resonance images (MRI) that comprise many different contrasts. Unsupervised methods can alleviate this problem; however, the performance drop is inevitable compared to fully supervised methods. In this work, we propose a self-training based unsupervised-learning framework that performs automatic segmentation of Vestibular Schwannoma (VS) and cochlea on high-resolution T2 scans. Our method consists of 4 main stages: 1) VS-preserving contrast conversion from contrast-enhanced T1 scan to high-resolution T2 scan, 2) training segmentation on generated T2 scans with annotations on T1 scans, and 3) Inferring pseudo-labels on non-annotated real T2 scans, and 4) boosting the generalizability of VS and cochlea segmentation by training with combined data (i.e., real T2 scans with pseudo-labels and generated T2 scans with true annotations). Our method showed mean Dice score and Average Symmetric Surface Distance (ASSD) of 0.8570 (0.0705) and 0.4970 (0.3391) for VS, 0.8446 (0.0211) and 0.1513 (0.0314) for Cochlea on CrossMoDA2021 challenge validation phase leaderboard, outperforming most other approaches.
End-to-End Deep Convolutional Active Contours for Image Segmentation
Oct 04, 2019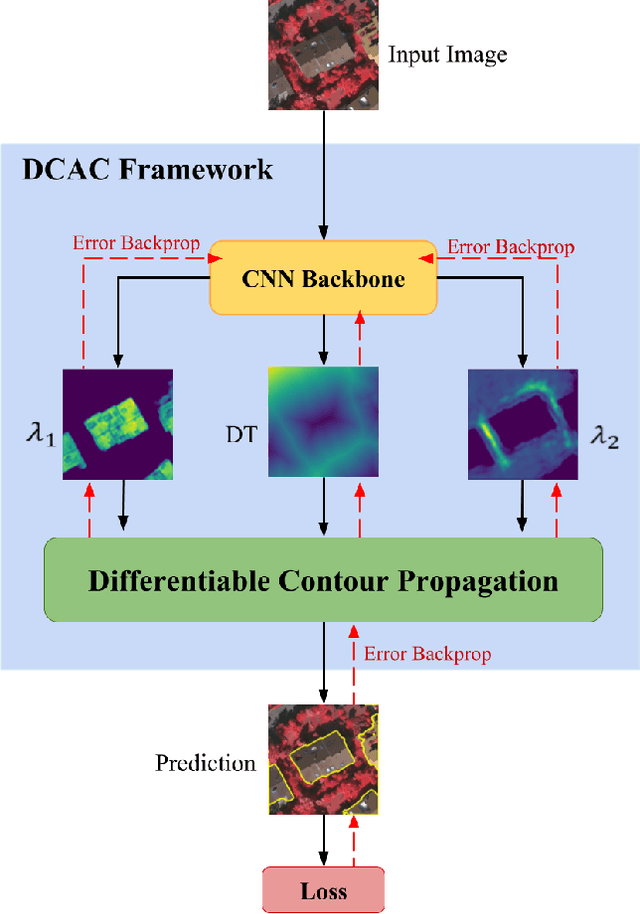
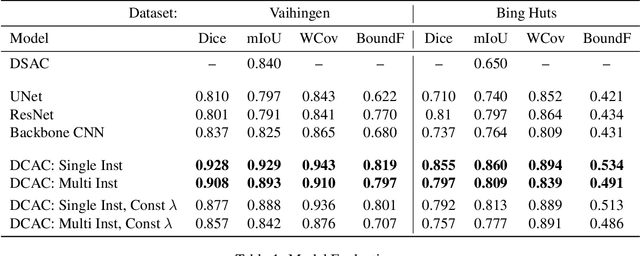
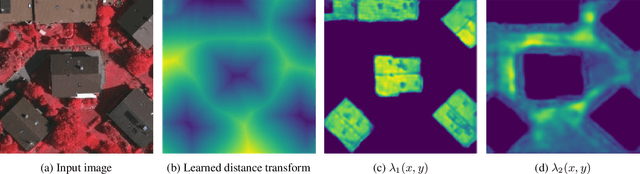
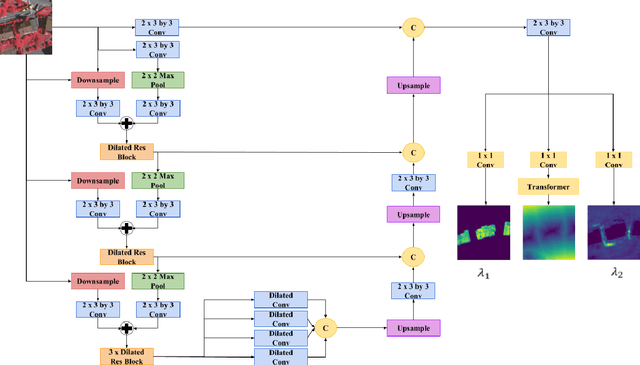
The Active Contour Model (ACM) is a standard image analysis technique whose numerous variants have attracted an enormous amount of research attention across multiple fields. Incorrectly, however, the ACM's differential-equation-based formulation and prototypical dependence on user initialization have been regarded as being largely incompatible with the recently popular deep learning approaches to image segmentation. This paper introduces the first tight unification of these two paradigms. In particular, we devise Deep Convolutional Active Contours (DCAC), a truly end-to-end trainable image segmentation framework comprising a Convolutional Neural Network (CNN) and an ACM with learnable parameters. The ACM's Eulerian energy functional includes per-pixel parameter maps predicted by the backbone CNN, which also initializes the ACM. Importantly, both the CNN and ACM components are fully implemented in TensorFlow, and the entire DCAC architecture is end-to-end automatically differentiable and backpropagation trainable without user intervention. As a challenging test case, we tackle the problem of building instance segmentation in aerial images and evaluate DCAC on two publicly available datasets, Vaihingen and Bing Huts. Our reseults demonstrate that, for building segmentation, the DCAC establishes a new state-of-the-art performance by a wide margin.
Deep Learning for Fine-Grained Image Analysis: A Survey
Jul 06, 2019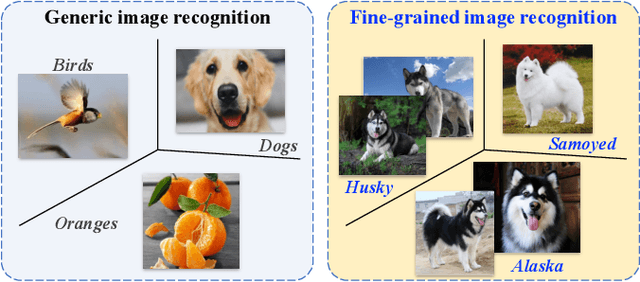
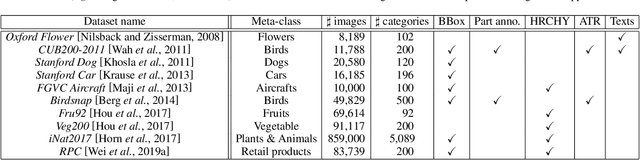
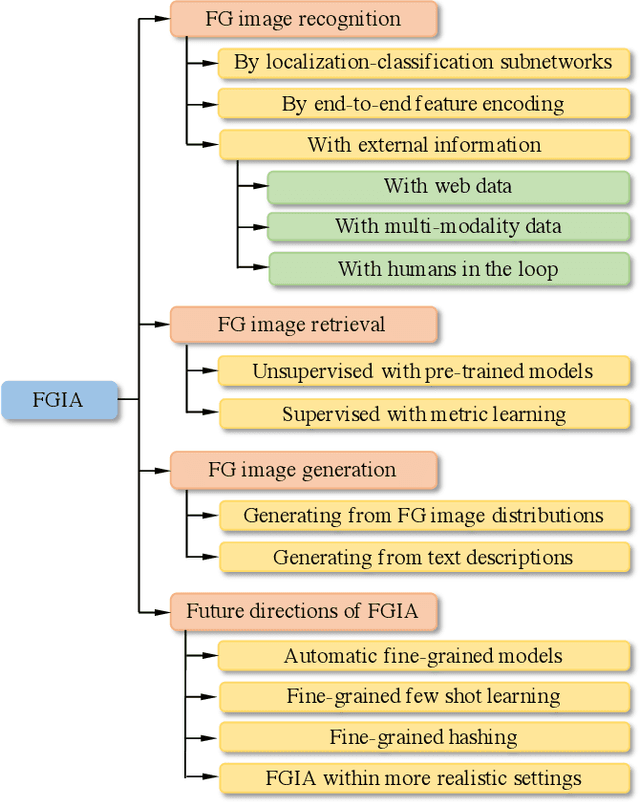

Computer vision (CV) is the process of using machines to understand and analyze imagery, which is an integral branch of artificial intelligence. Among various research areas of CV, fine-grained image analysis (FGIA) is a longstanding and fundamental problem, and has become ubiquitous in diverse real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, \eg, species of birds or models of cars. The small inter-class variations and the large intra-class variations caused by the fine-grained nature makes it a challenging problem. During the booming of deep learning, recent years have witnessed remarkable progress of FGIA using deep learning techniques. In this paper, we aim to give a survey on recent advances of deep learning based FGIA techniques in a systematic way. Specifically, we organize the existing studies of FGIA techniques into three major categories: fine-grained image recognition, fine-grained image retrieval and fine-grained image generation. In addition, we also cover some other important issues of FGIA, such as publicly available benchmark datasets and its related domain specific applications. Finally, we conclude this survey by highlighting several directions and open problems which need be further explored by the community in the future.
LDC-VAE: A Latent Distribution Consistency Approach to Variational AutoEncoders
Sep 22, 2021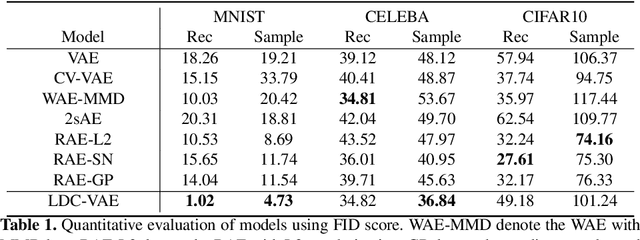
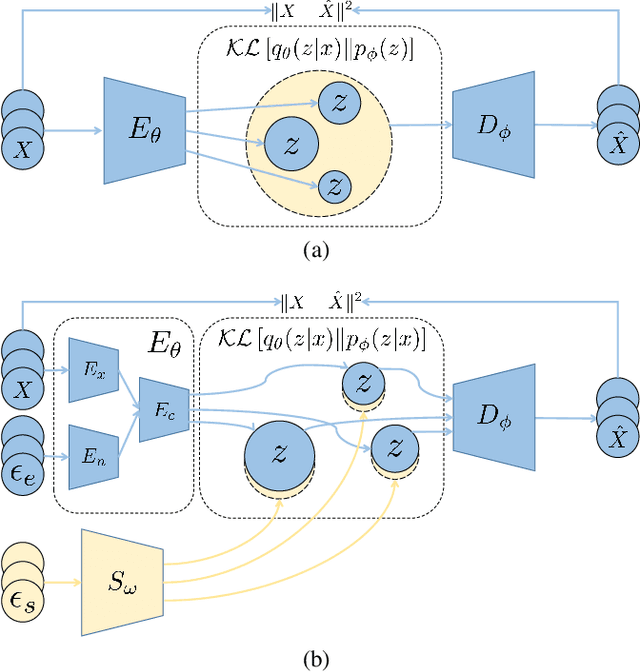
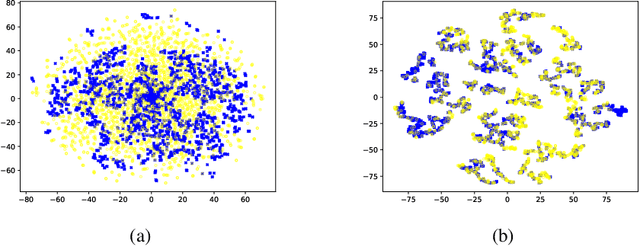

Variational autoencoders (VAEs), as an important aspect of generative models, have received a lot of research interests and reached many successful applications. However, it is always a challenge to achieve the consistency between the learned latent distribution and the prior latent distribution when optimizing the evidence lower bound (ELBO), and finally leads to an unsatisfactory performance in data generation. In this paper, we propose a latent distribution consistency approach to avoid such substantial inconsistency between the posterior and prior latent distributions in ELBO optimizing. We name our method as latent distribution consistency VAE (LDC-VAE). We achieve this purpose by assuming the real posterior distribution in latent space as a Gibbs form, and approximating it by using our encoder. However, there is no analytical solution for such Gibbs posterior in approximation, and traditional approximation ways are time consuming, such as using the iterative sampling-based MCMC. To address this problem, we use the Stein Variational Gradient Descent (SVGD) to approximate the Gibbs posterior. Meanwhile, we use the SVGD to train a sampler net which can obtain efficient samples from the Gibbs posterior. Comparative studies on the popular image generation datasets show that our method has achieved comparable or even better performance than several powerful improvements of VAEs.
Continual Active Learning for Efficient Adaptation of Machine Learning Models to Changing Image Acquisition
Jun 07, 2021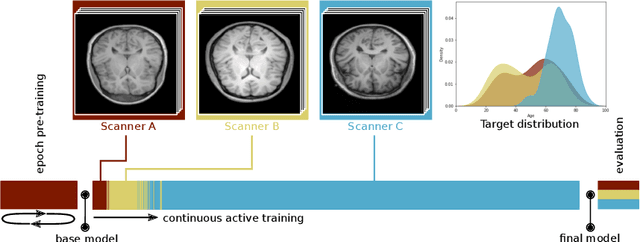
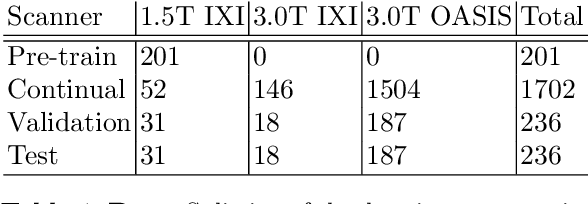
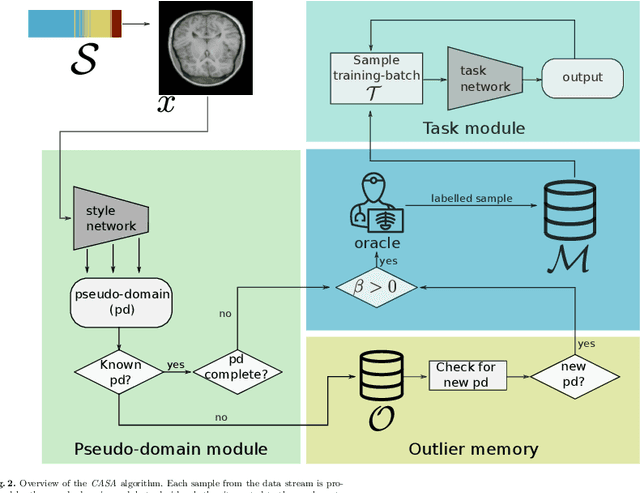
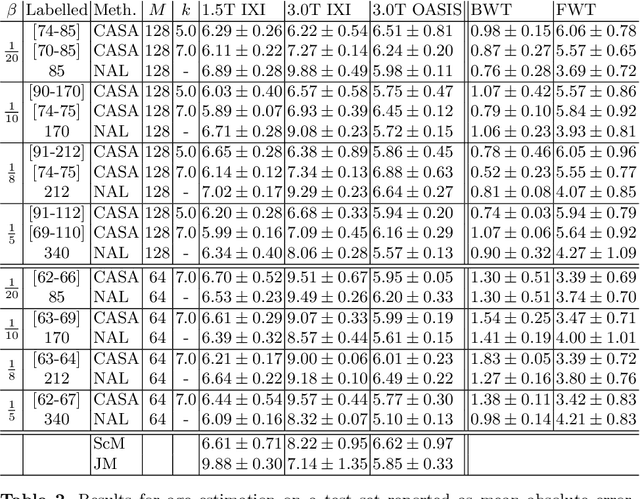
Imaging in clinical routine is subject to changing scanner protocols, hardware, or policies in a typically heterogeneous set of acquisition hardware. Accuracy and reliability of deep learning models suffer from those changes as data and targets become inconsistent with their initial static training set. Continual learning can adapt to a continuous data stream of a changing imaging environment. Here, we propose a method for continual active learning on a data stream of medical images. It recognizes shifts or additions of new imaging sources - domains -, adapts training accordingly, and selects optimal examples for labelling. Model training has to cope with a limited labelling budget, resembling typical real world scenarios. We demonstrate our method on T1-weighted magnetic resonance images from three different scanners with the task of brain age estimation. Results demonstrate that the proposed method outperforms naive active learning while requiring less manual labelling.