 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
B-line Detection in Lung Ultrasound Videos: Cartesian vs Polar Representation
Jul 26, 2021
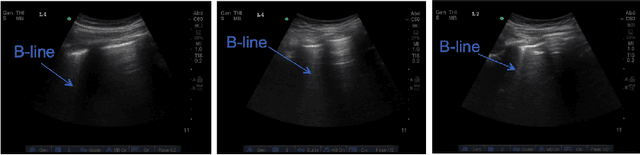

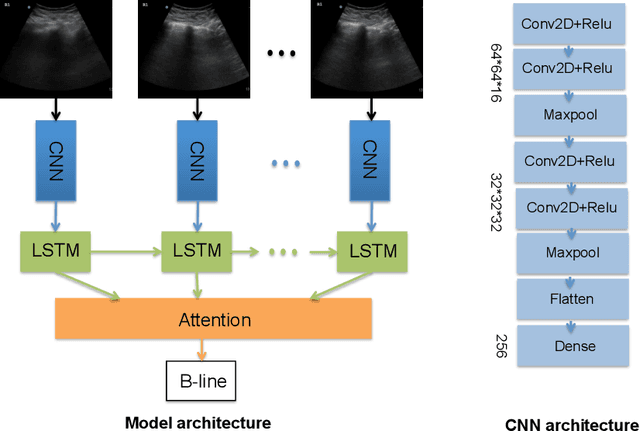
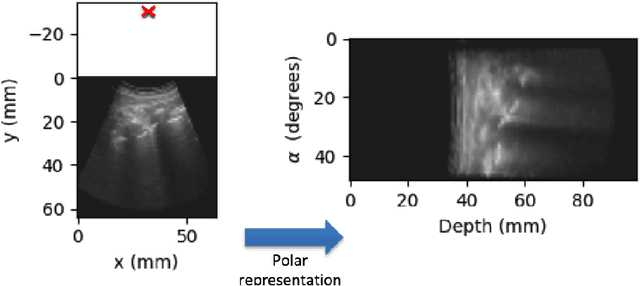
Lung ultrasound (LUS) imaging is becoming popular in the intensive care units (ICU) for assessing lung abnormalities such as the appearance of B-line artefacts as a result of severe dengue. These artefacts appear in the LUS images and disappear quickly, making their manual detection very challenging. They also extend radially following the propagation of the sound waves. As a result, we hypothesize that a polar representation may be more adequate for automatic image analysis of these images. This paper presents an attention-based Convolutional+LSTM model to automatically detect B-lines in LUS videos, comparing performance when image data is taken in Cartesian and polar representations. Results indicate that the proposed framework with polar representation achieves competitive performance compared to the Cartesian representation for B-line classification and that attention mechanism can provide better localization.
Design of Low-Artifact Interpolation Kernels by Means of Computer Algebra
Jun 08, 2021
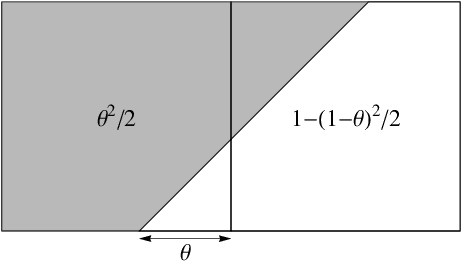
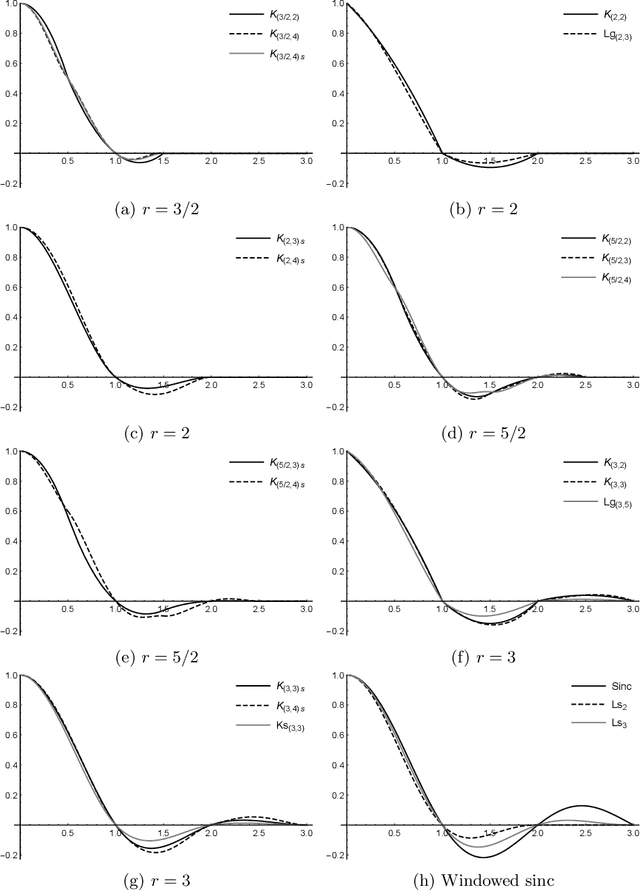
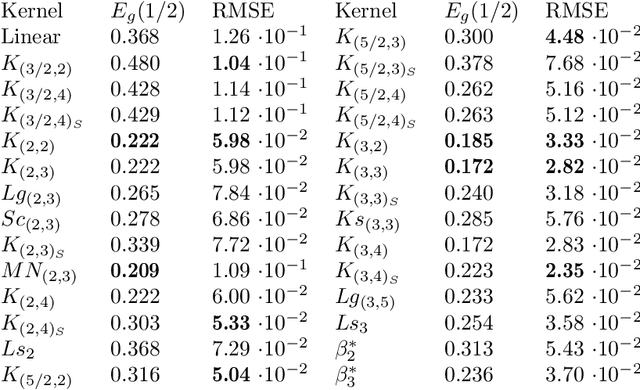
We present a number of new piecewise-polynomial kernels for image interpolation. The kernels are constructed by optimizing a measure of interpolation quality based on the magnitude of anisotropic artifacts. The kernel design process is performed symbolically using Mathematica computer algebra system. Experimental evaluation involving 14 image quality assessment methods demonstrates that our results compare favorably with the existing linear interpolators.
Tea Chrysanthemum Detection under Unstructured Environments Using the TC-YOLO Model
Nov 04, 2021

Tea chrysanthemum detection at its flowering stage is one of the key components for selective chrysanthemum harvesting robot development. However, it is a challenge to detect flowering chrysanthemums under unstructured field environments given the variations on illumination, occlusion and object scale. In this context, we propose a highly fused and lightweight deep learning architecture based on YOLO for tea chrysanthemum detection (TC-YOLO). First, in the backbone component and neck component, the method uses the Cross-Stage Partially Dense Network (CSPDenseNet) as the main network, and embeds custom feature fusion modules to guide the gradient flow. In the final head component, the method combines the recursive feature pyramid (RFP) multiscale fusion reflow structure and the Atrous Spatial Pyramid Pool (ASPP) module with cavity convolution to achieve the detection task. The resulting model was tested on 300 field images, showing that under the NVIDIA Tesla P100 GPU environment, if the inference speed is 47.23 FPS for each image (416 * 416), TC-YOLO can achieve the average precision (AP) of 92.49% on our own tea chrysanthemum dataset. In addition, this method (13.6M) can be deployed on a single mobile GPU, and it could be further developed as a perception system for a selective chrysanthemum harvesting robot in the future.
Localizing Unseen Activities in Video via Image Query
Jun 28, 2019
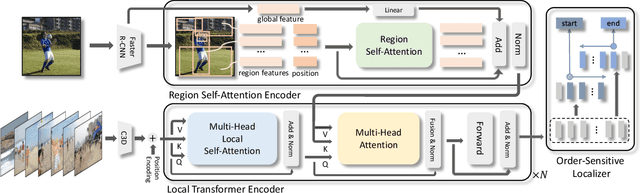
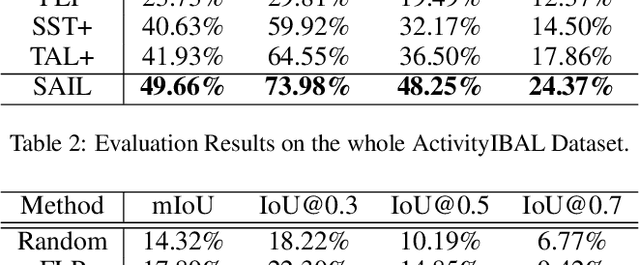
Action localization in untrimmed videos is an important topic in the field of video understanding. However, existing action localization methods are restricted to a pre-defined set of actions and cannot localize unseen activities. Thus, we consider a new task to localize unseen activities in videos via image queries, named Image-Based Activity Localization. This task faces three inherent challenges: (1) how to eliminate the influence of semantically inessential contents in image queries; (2) how to deal with the fuzzy localization of inaccurate image queries; (3) how to determine the precise boundaries of target segments. We then propose a novel self-attention interaction localizer to retrieve unseen activities in an end-to-end fashion. Specifically, we first devise a region self-attention method with relative position encoding to learn fine-grained image region representations. Then, we employ a local transformer encoder to build multi-step fusion and reasoning of image and video contents. We next adopt an order-sensitive localizer to directly retrieve the target segment. Furthermore, we construct a new dataset ActivityIBAL by reorganizing the ActivityNet dataset. The extensive experiments show the effectiveness of our method.
Well-classified Examples are Underestimated in Classification with Deep Neural Networks
Oct 15, 2021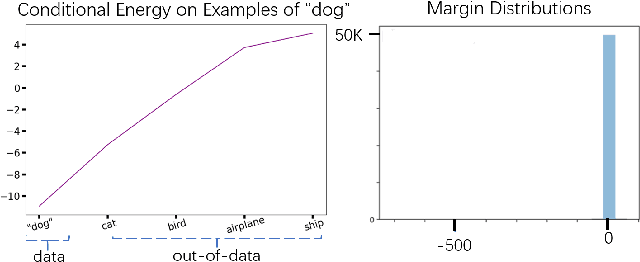
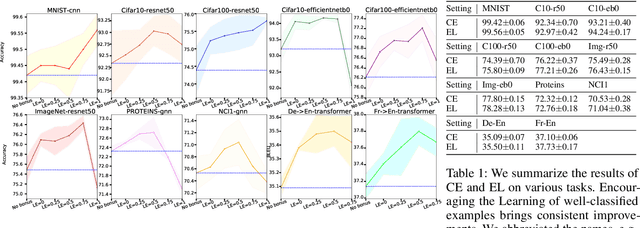
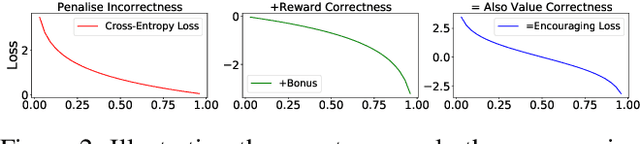

The conventional wisdom behind learning deep classification models is to focus on bad-classified examples and ignore well-classified examples that are far from the decision boundary. For instance, when training with cross-entropy loss, examples with higher likelihoods (i.e., well-classified examples) contribute smaller gradients in back-propagation. However, we theoretically show that this common practice hinders representation learning, energy optimization, and the growth of margin. To counteract this deficiency, we propose to reward well-classified examples with additive bonuses to revive their contribution to learning. This counterexample theoretically addresses these three issues. We empirically support this claim by directly verify the theoretical results or through the significant performance improvement with our counterexample on diverse tasks, including image classification, graph classification, and machine translation. Furthermore, this paper shows that because our idea can solve these three issues, we can deal with complex scenarios, such as imbalanced classification, OOD detection, and applications under adversarial attacks. Code is available at: https://github.com/lancopku/well-classified-examples-are-underestimated.
Lizard: A Large-Scale Dataset for Colonic Nuclear Instance Segmentation and Classification
Aug 25, 2021
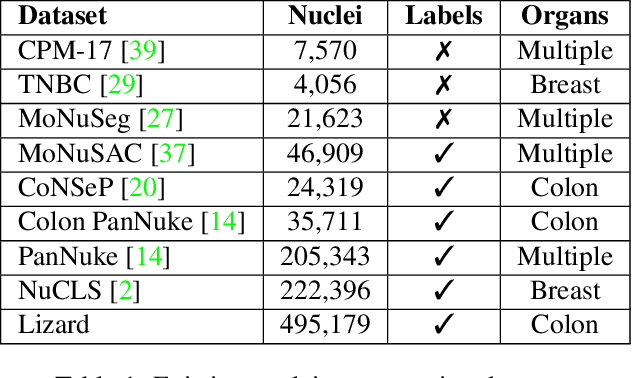
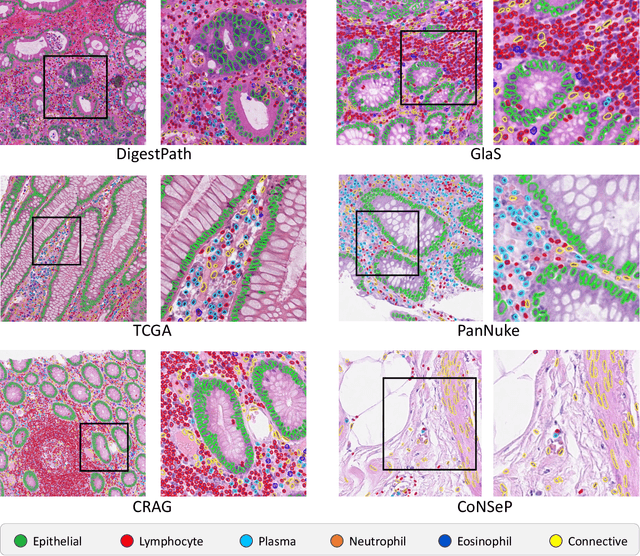
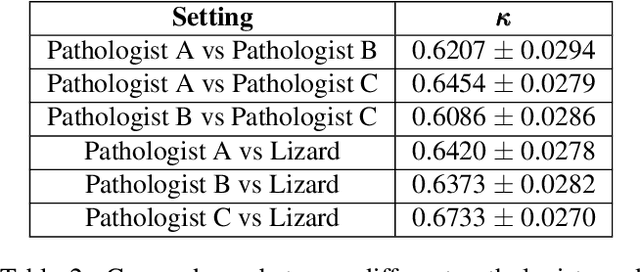
The development of deep segmentation models for computational pathology (CPath) can help foster the investigation of interpretable morphological biomarkers. Yet, there is a major bottleneck in the success of such approaches because supervised deep learning models require an abundance of accurately labelled data. This issue is exacerbated in the field of CPath because the generation of detailed annotations usually demands the input of a pathologist to be able to distinguish between different tissue constructs and nuclei. Manually labelling nuclei may not be a feasible approach for collecting large-scale annotated datasets, especially when a single image region can contain thousands of different cells. However, solely relying on automatic generation of annotations will limit the accuracy and reliability of ground truth. Therefore, to help overcome the above challenges, we propose a multi-stage annotation pipeline to enable the collection of large-scale datasets for histology image analysis, with pathologist-in-the-loop refinement steps. Using this pipeline, we generate the largest known nuclear instance segmentation and classification dataset, containing nearly half a million labelled nuclei in H&E stained colon tissue. We have released the dataset and encourage the research community to utilise it to drive forward the development of downstream cell-based models in CPath.
Check Your Other Door! Establishing Backdoor Attacks in the Frequency Domain
Sep 12, 2021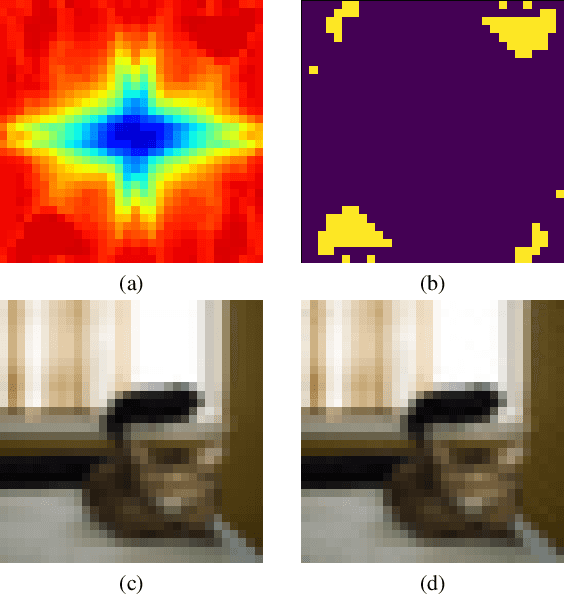
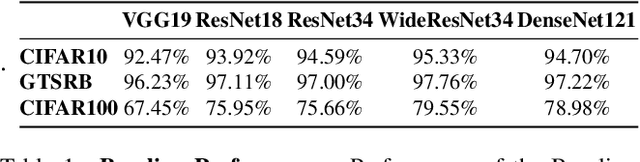
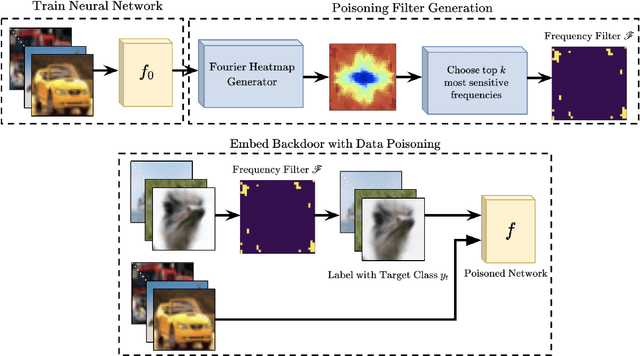
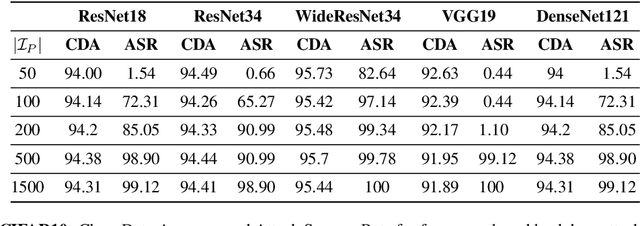
Deep Neural Networks (DNNs) have been utilized in various applications ranging from image classification and facial recognition to medical imagery analysis and real-time object detection. As our models become more sophisticated and complex, the computational cost of training such models becomes a burden for small companies and individuals; for this reason, outsourcing the training process has been the go-to option for such users. Unfortunately, outsourcing the training process comes at the cost of vulnerability to backdoor attacks. These attacks aim at establishing hidden backdoors in the DNN such that the model performs well on benign samples but outputs a particular target label when a trigger is applied to the input. Current backdoor attacks rely on generating triggers in the image/pixel domain; however, as we show in this paper, it is not the only domain to exploit and one should always "check the other doors". In this work, we propose a complete pipeline for generating a dynamic, efficient, and invisible backdoor attack in the frequency domain. We show the advantages of utilizing the frequency domain for establishing undetectable and powerful backdoor attacks through extensive experiments on various datasets and network architectures. The backdoored models are shown to break various state-of-the-art defences. We also show two possible defences that succeed against frequency-based backdoor attacks and possible ways for the attacker to bypass them. We conclude the work with some remarks regarding a network's learning capacity and the capability of embedding a backdoor attack in the model.
Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey
Feb 10, 2020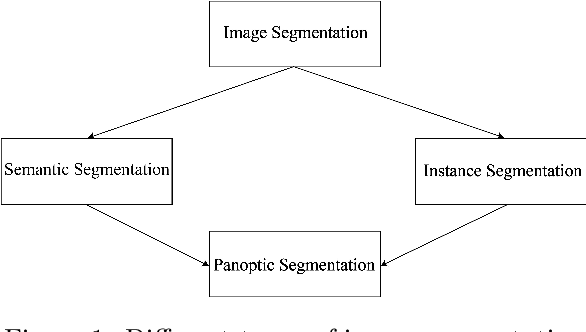
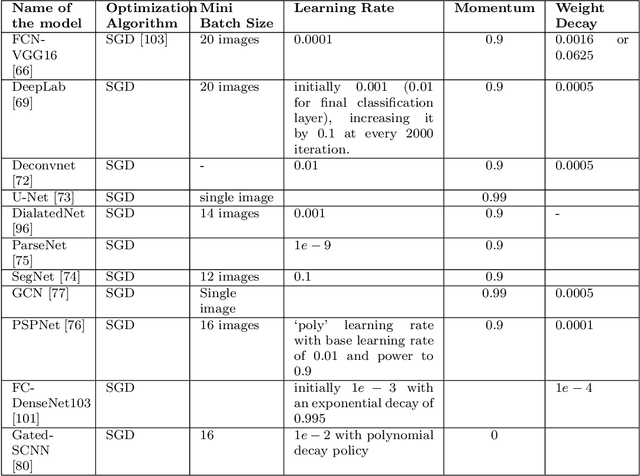
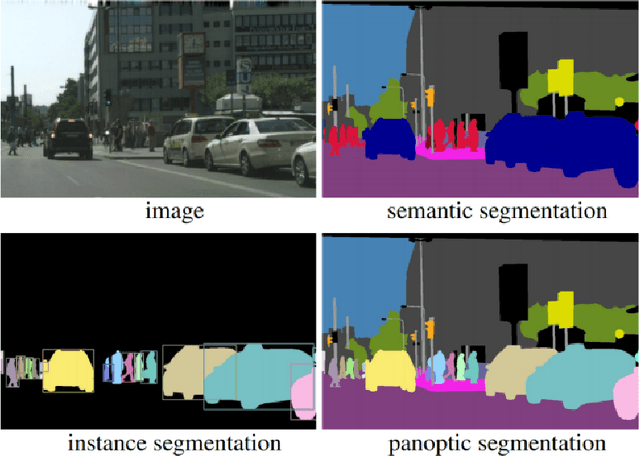
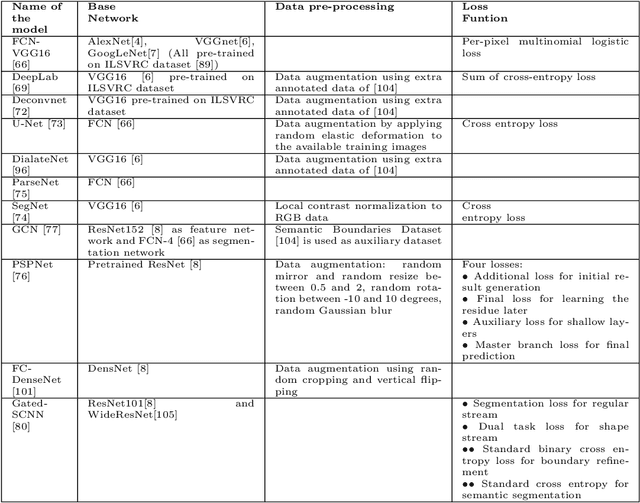
From the autonomous car driving to medical diagnosis, the requirement of the task of image segmentation is everywhere. Segmentation of an image is one of the indispensable tasks in computer vision. This task is comparatively complicated than other vision tasks as it needs low-level spatial information. Basically, image segmentation can be of two types: semantic segmentation and instance segmentation. The combined version of these two basic tasks is known as panoptic segmentation. In the recent era, the success of deep convolutional neural network (CNN) has influenced the field of segmentation greatly and gave us various successful models to date. In this survey, we are going to take a glance at the evolution of both semantic and instance segmentation work based on CNN. We have also specified comparative architectural details of some state-of-the-art models and discuss their training details to present a lucid understanding of hyper-parameter tuning of those models. Lastly, we have drawn a comparison among the performance of those models on different datasets.
TimeMatch: Unsupervised Cross-Region Adaptation by Temporal Shift Estimation
Nov 04, 2021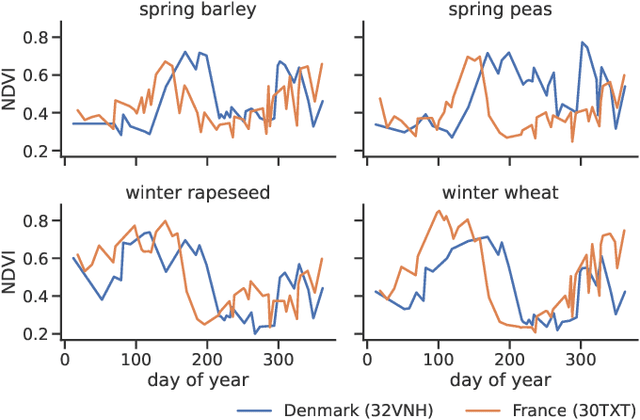
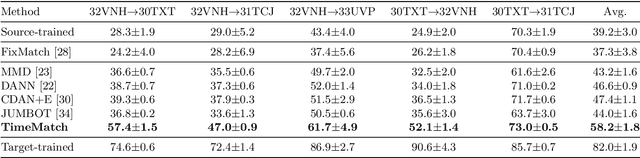
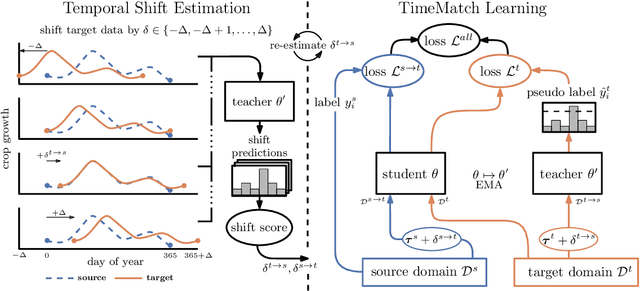

The recent developments of deep learning models that capture the complex temporal patterns of crop phenology have greatly advanced crop classification of Satellite Image Time Series (SITS). However, when applied to target regions spatially different from the training region, these models perform poorly without any target labels due to the temporal shift of crop phenology between regions. To address this unsupervised cross-region adaptation setting, existing methods learn domain-invariant features without any target supervision, but not the temporal shift itself. As a consequence, these techniques provide only limited benefits for SITS. In this paper, we propose TimeMatch, a new unsupervised domain adaptation method for SITS that directly accounts for the temporal shift. TimeMatch consists of two components: 1) temporal shift estimation, which estimates the temporal shift of the unlabeled target region with a source-trained model, and 2) TimeMatch learning, which combines temporal shift estimation with semi-supervised learning to adapt a classifier to an unlabeled target region. We also introduce an open-access dataset for cross-region adaptation with SITS from four different regions in Europe. On this dataset, we demonstrate that TimeMatch outperforms all competing methods by 11% in F1-score across five different adaptation scenarios, setting a new state-of-the-art for cross-region adaptation.
Zero-Shot Certified Defense against Adversarial Patches with Vision Transformers
Nov 19, 2021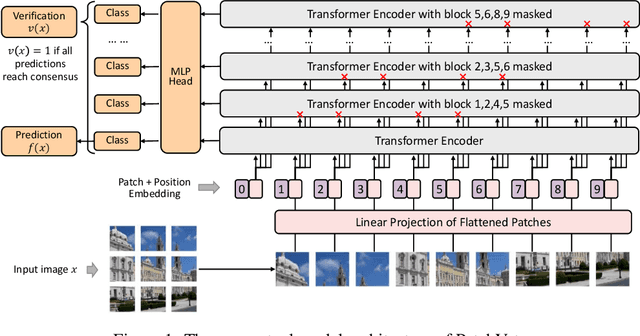
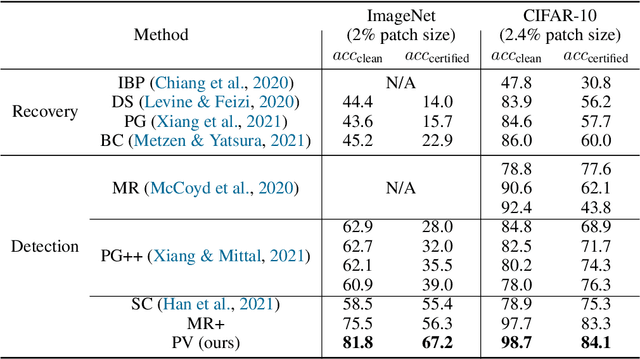
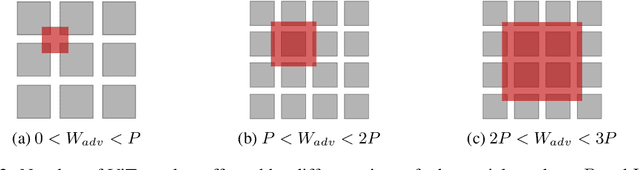
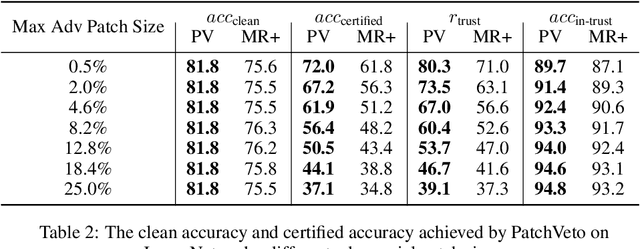
Adversarial patch attack aims to fool a machine learning model by arbitrarily modifying pixels within a restricted region of an input image. Such attacks are a major threat to models deployed in the physical world, as they can be easily realized by presenting a customized object in the camera view. Defending against such attacks is challenging due to the arbitrariness of patches, and existing provable defenses suffer from poor certified accuracy. In this paper, we propose PatchVeto, a zero-shot certified defense against adversarial patches based on Vision Transformer (ViT) models. Rather than training a robust model to resist adversarial patches which may inevitably sacrifice accuracy, PatchVeto reuses a pretrained ViT model without any additional training, which can achieve high accuracy on clean inputs while detecting adversarial patched inputs by simply manipulating the attention map of ViT. Specifically, each input is tested by voting over multiple inferences with different attention masks, where at least one inference is guaranteed to exclude the adversarial patch. The prediction is certifiably robust if all masked inferences reach consensus, which ensures that any adversarial patch would be detected with no false negative. Extensive experiments have shown that PatchVeto is able to achieve high certified accuracy (e.g. 67.1% on ImageNet for 2%-pixel adversarial patches), significantly outperforming state-of-the-art methods. The clean accuracy is the same as vanilla ViT models (81.8% on ImageNet) since the model parameters are directly reused. Meanwhile, our method can flexibly handle different adversarial patch sizes by simply changing the masking strategy.