 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLizard: A Large-Scale Dataset for Colonic Nuclear Instance Segmentation and Classification
Paper and Code
Aug 25, 2021
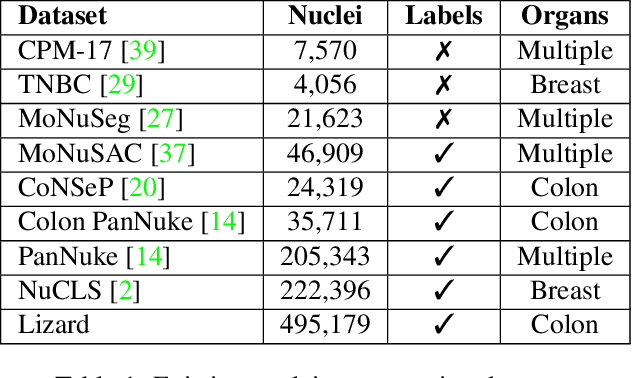
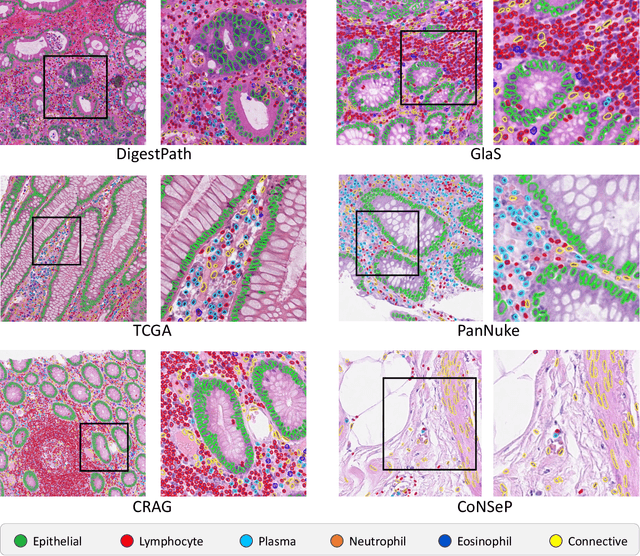
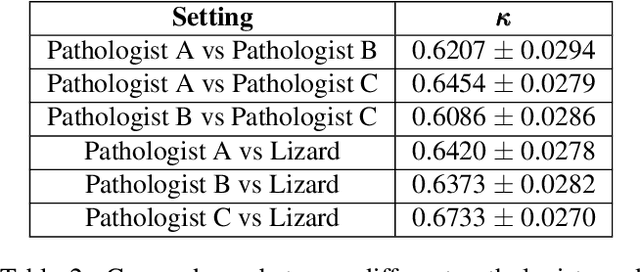
The development of deep segmentation models for computational pathology (CPath) can help foster the investigation of interpretable morphological biomarkers. Yet, there is a major bottleneck in the success of such approaches because supervised deep learning models require an abundance of accurately labelled data. This issue is exacerbated in the field of CPath because the generation of detailed annotations usually demands the input of a pathologist to be able to distinguish between different tissue constructs and nuclei. Manually labelling nuclei may not be a feasible approach for collecting large-scale annotated datasets, especially when a single image region can contain thousands of different cells. However, solely relying on automatic generation of annotations will limit the accuracy and reliability of ground truth. Therefore, to help overcome the above challenges, we propose a multi-stage annotation pipeline to enable the collection of large-scale datasets for histology image analysis, with pathologist-in-the-loop refinement steps. Using this pipeline, we generate the largest known nuclear instance segmentation and classification dataset, containing nearly half a million labelled nuclei in H&E stained colon tissue. We have released the dataset and encourage the research community to utilise it to drive forward the development of downstream cell-based models in CPath.