 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOFE -- Neural Operator Function Embedding
May 12, 2026Most dimensionality reduction methods treat data as discrete point clouds, ignoring the continuous domain structure inherent to many real-world processes. To bridge this gap, we introduce Neural Operator Function Embedding (NOFE), a domain-aware framework for continuous dimensionality reduction. NOFE learns function-to-function mappings via a Graph Kernel Operator, enabling mesh-free evaluation at arbitrary query locations independent of input discretization. We establish NOFE as approximation of sheaf-to-sheaf mappings, generalizing Sheaf Neural Networks to continuous domains. We evaluate NOFE across different datasets, comparing it against PCA, t-SNE, and UMAP. Our results demonstrate that NOFE significantly outperforms baselines in local structure preservation, achieving a local Stress of 0.111 compared to 0.398 for PCA, 0.773 for t-SNE, and 0.791 for UMAP for the ERA5 climate reanalysis dataset. NOFE also exhibits robust sampling independence, reducing the Patch Stitching Error by up to $20.0\times$ relative to UMAP (59.0 vs. 267.6 under regional normalization) and ensuring consistency across disjoint domain patches. While maintaining competitive global structure preservation (Stress-1: 0.379 vs. PCA's 0.268), NOFE resolves fine-grained structures and produces smooth, consistent embeddings that generalize across varying sample densities, addressing key limitations of discrete reduction methods.
From Words to Wavelengths: VLMs for Few-Shot Multispectral Object Detection
Dec 17, 2025
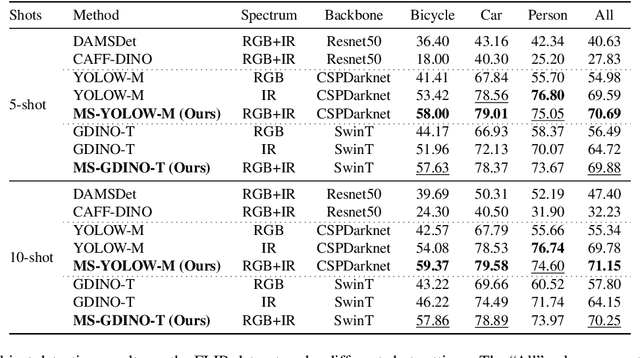

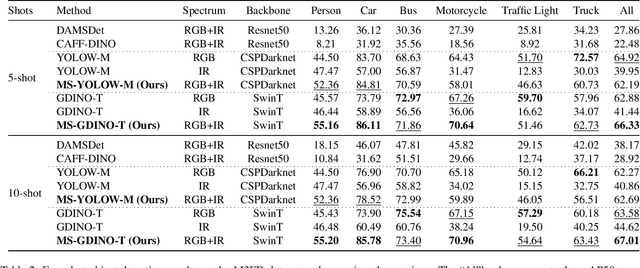
Multispectral object detection is critical for safety-sensitive applications such as autonomous driving and surveillance, where robust perception under diverse illumination conditions is essential. However, the limited availability of annotated multispectral data severely restricts the training of deep detectors. In such data-scarce scenarios, textual class information can serve as a valuable source of semantic supervision. Motivated by the recent success of Vision-Language Models (VLMs) in computer vision, we explore their potential for few-shot multispectral object detection. Specifically, we adapt two representative VLM-based detectors, Grounding DINO and YOLO-World, to handle multispectral inputs and propose an effective mechanism to integrate text, visual and thermal modalities. Through extensive experiments on two popular multispectral image benchmarks, FLIR and M3FD, we demonstrate that VLM-based detectors not only excel in few-shot regimes, significantly outperforming specialized multispectral models trained with comparable data, but also achieve competitive or superior results under fully supervised settings. Our findings reveal that the semantic priors learned by large-scale VLMs effectively transfer to unseen spectral modalities, ofFering a powerful pathway toward data-efficient multispectral perception.
On the use of Graphs for Satellite Image Time Series
May 22, 2025



The Earth's surface is subject to complex and dynamic processes, ranging from large-scale phenomena such as tectonic plate movements to localized changes associated with ecosystems, agriculture, or human activity. Satellite images enable global monitoring of these processes with extensive spatial and temporal coverage, offering advantages over in-situ methods. In particular, resulting satellite image time series (SITS) datasets contain valuable information. To handle their large volume and complexity, some recent works focus on the use of graph-based techniques that abandon the regular Euclidean structure of satellite data to work at an object level. Besides, graphs enable modelling spatial and temporal interactions between identified objects, which are crucial for pattern detection, classification and regression tasks. This paper is an effort to examine the integration of graph-based methods in spatio-temporal remote-sensing analysis. In particular, it aims to present a versatile graph-based pipeline to tackle SITS analysis. It focuses on the construction of spatio-temporal graphs from SITS and their application to downstream tasks. The paper includes a comprehensive review and two case studies, which highlight the potential of graph-based approaches for land cover mapping and water resource forecasting. It also discusses numerous perspectives to resolve current limitations and encourage future developments.
Towards Efficient Benchmarking of Foundation Models in Remote Sensing: A Capabilities Encoding Approach
May 06, 2025Foundation models constitute a significant advancement in computer vision: after a single, albeit costly, training phase, they can address a wide array of tasks. In the field of Earth observation, over 75 remote sensing vision foundation models have been developed in the past four years. However, none has consistently outperformed the others across all available downstream tasks. To facilitate their comparison, we propose a cost-effective method for predicting a model's performance on multiple downstream tasks without the need for fine-tuning on each one. This method is based on what we call "capabilities encoding." The utility of this novel approach is twofold: we demonstrate its potential to simplify the selection of a foundation model for a given new task, and we employ it to offer a fresh perspective on the existing literature, suggesting avenues for future research. Codes are available at https://github.com/pierreadorni/capabilities-encoding.
Plant detection from ultra high resolution remote sensing images: A Semantic Segmentation approach based on fuzzy loss
Aug 31, 2024



In this study, we tackle the challenge of identifying plant species from ultra high resolution (UHR) remote sensing images. Our approach involves introducing an RGB remote sensing dataset, characterized by millimeter-level spatial resolution, meticulously curated through several field expeditions across a mountainous region in France covering various landscapes. The task of plant species identification is framed as a semantic segmentation problem for its practical and efficient implementation across vast geographical areas. However, when dealing with segmentation masks, we confront instances where distinguishing boundaries between plant species and their background is challenging. We tackle this issue by introducing a fuzzy loss within the segmentation model. Instead of utilizing one-hot encoded ground truth (GT), our model incorporates Gaussian filter refined GT, introducing stochasticity during training. First experimental results obtained on both our UHR dataset and a public dataset are presented, showing the relevance of the proposed methodology, as well as the need for future improvement.
Mapping earth mounds from space
Aug 31, 2024Regular patterns of vegetation are considered widespread landscapes, although their global extent has never been estimated. Among them, spotted landscapes are of particular interest in the context of climate change. Indeed, regularly spaced vegetation spots in semi-arid shrublands result from extreme resource depletion and prefigure catastrophic shift of the ecosystem to a homogeneous desert, while termite mounds also producing spotted landscapes were shown to increase robustness to climate change. Yet, their identification at large scale calls for automatic methods, for instance using the popular deep learning framework, able to cope with a vast amount of remote sensing data, e.g., optical satellite imagery. In this paper, we tackle this problem and benchmark some state-of-the-art deep networks on several landscapes and geographical areas. Despite the promising results we obtained, we found that more research is needed to be able to map automatically these earth mounds from space.
3DMASC: Accessible, explainable 3D point clouds classification. Application to Bi-spectral Topo-bathymetric lidar data
Jan 15, 2024Three-dimensional data have become increasingly present in earth observation over the last decades. However, many 3D surveys are still underexploited due to the lack of accessible and explainable automatic classification methods, for example, new topo-bathymetric lidar data. In this work, we introduce explainable machine learning for 3D data classification using Multiple Attributes, Scales, and Clouds under 3DMASC, a new workflow. This workflow introduces multi-cloud classification through dual-cloud features, encrypting local spectral and geometrical ratios and differences. 3DMASC uses classical multi-scale descriptors adapted to all types of 3D point clouds and new ones based on their spatial variations. In this paper, we present the performances of 3DMASC for multi-class classification of topo-bathymetric lidar data in coastal and fluvial environments. We show how multivariate and embedded feature selection allows the building of optimized predictor sets of reduced complexity, and we identify features particularly relevant for coastal and riverine scene descriptions. Our results show the importance of dual-cloud features, lidar return-based attributes averaged over specific scales, and of statistics of dimensionality-based and spectral features. Additionally, they indicate that small to medium spherical neighbourhood diameters (<7 m) are sufficient to build effective classifiers, namely when combined with distance-to-ground or distance-to-water-surface features. Without using optional RGB information, and with a maximum of 37 descriptors, we obtain classification accuracies between 91 % for complex multi-class tasks and 98 % for lower-level processing using models trained on less than 2000 samples per class. Comparisons with classical point cloud classification methods show that 3DMASC features have a significantly improved descriptive power. Our contributions are made available through a plugin in the CloudCompare software, allowing non-specialist users to create classifiers for any type of 3D data characterized by 1 or 2 point clouds (airborne or terrestrial lidar, structure from motion), and two labelled topo-bathymetric lidar datasets, available on https://opentopography.org/.
Weakly supervised marine animal detection from remote sensing images using vector-quantized variational autoencoder
Jul 13, 2023



This paper studies a reconstruction-based approach for weakly-supervised animal detection from aerial images in marine environments. Such an approach leverages an anomaly detection framework that computes metrics directly on the input space, enhancing interpretability and anomaly localization compared to feature embedding methods. Building upon the success of Vector-Quantized Variational Autoencoders in anomaly detection on computer vision datasets, we adapt them to the marine animal detection domain and address the challenge of handling noisy data. To evaluate our approach, we compare it with existing methods in the context of marine animal detection from aerial image data. Experiments conducted on two dedicated datasets demonstrate the superior performance of the proposed method over recent studies in the literature. Our framework offers improved interpretability and localization of anomalies, providing valuable insights for monitoring marine ecosystems and mitigating the impact of human activities on marine animals.
Multimodal Object Detection in Remote Sensing
Jul 13, 2023Object detection in remote sensing is a crucial computer vision task that has seen significant advancements with deep learning techniques. However, most existing works in this area focus on the use of generic object detection and do not leverage the potential of multimodal data fusion. In this paper, we present a comparison of methods for multimodal object detection in remote sensing, survey available multimodal datasets suitable for evaluation, and discuss future directions.
A Deep Active Contour Model for Delineating Glacier Calving Fronts
Jul 07, 2023



Choosing how to encode a real-world problem as a machine learning task is an important design decision in machine learning. The task of glacier calving front modeling has often been approached as a semantic segmentation task. Recent studies have shown that combining segmentation with edge detection can improve the accuracy of calving front detectors. Building on this observation, we completely rephrase the task as a contour tracing problem and propose a model for explicit contour detection that does not incorporate any dense predictions as intermediate steps. The proposed approach, called ``Charting Outlines by Recurrent Adaptation'' (COBRA), combines Convolutional Neural Networks (CNNs) for feature extraction and active contour models for the delineation. By training and evaluating on several large-scale datasets of Greenland's outlet glaciers, we show that this approach indeed outperforms the aforementioned methods based on segmentation and edge-detection. Finally, we demonstrate that explicit contour detection has benefits over pixel-wise methods when quantifying the models' prediction uncertainties. The project page containing the code and animated model predictions can be found at \url{https://khdlr.github.io/COBRA/}.