 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Supervised learning of analysis-sparsity priors with automatic differentiation
Dec 15, 2021

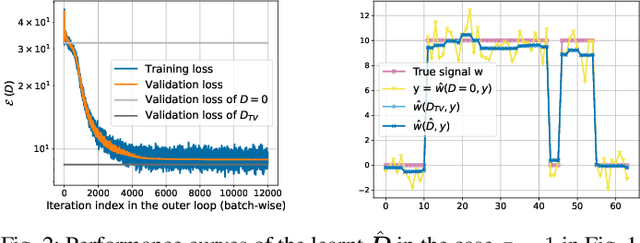
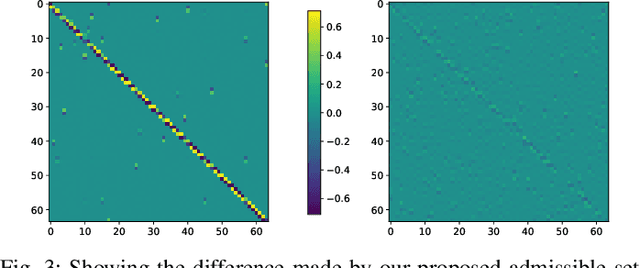
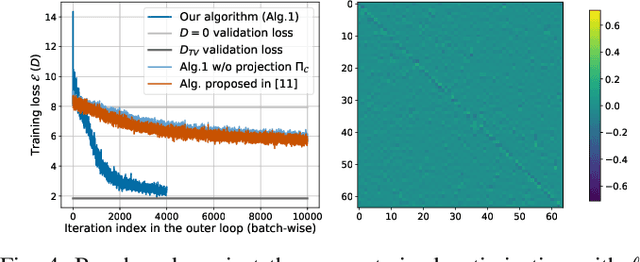
Sparsity priors are commonly used in denoising and image reconstruction. For analysis-type priors, a dictionary defines a representation of signals that is likely to be sparse. In most situations, this dictionary is not known, and is to be recovered from pairs of ground-truth signals and measurements, by minimizing the reconstruction error. This defines a hierarchical optimization problem, which can be cast as a bi-level optimization. Yet, this problem is unsolvable, as reconstructions and their derivative wrt the dictionary have no closed-form expression. However, reconstructions can be iteratively computed using the Forward-Backward splitting (FB) algorithm. In this paper, we approximate reconstructions by the output of the aforementioned FB algorithm. Then, we leverage automatic differentiation to evaluate the gradient of this output wrt the dictionary, which we learn with projected gradient descent. Experiments show that our algorithm successfully learns the 1D Total Variation (TV) dictionary from piecewise constant signals. For the same case study, we propose to constrain our search to dictionaries of 0-centered columns, which removes undesired local minima and improves numerical stability.
RepMLPNet: Hierarchical Vision MLP with Re-parameterized Locality
Dec 21, 2021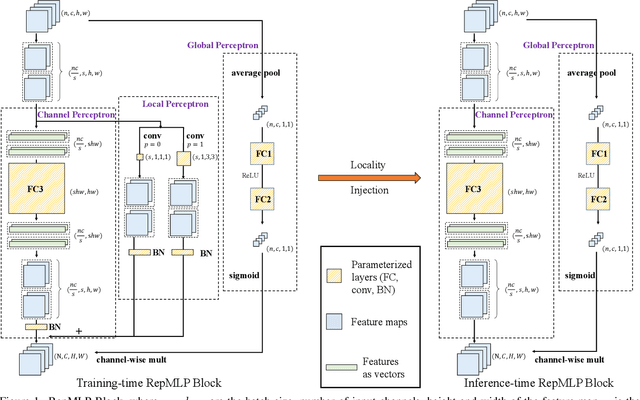
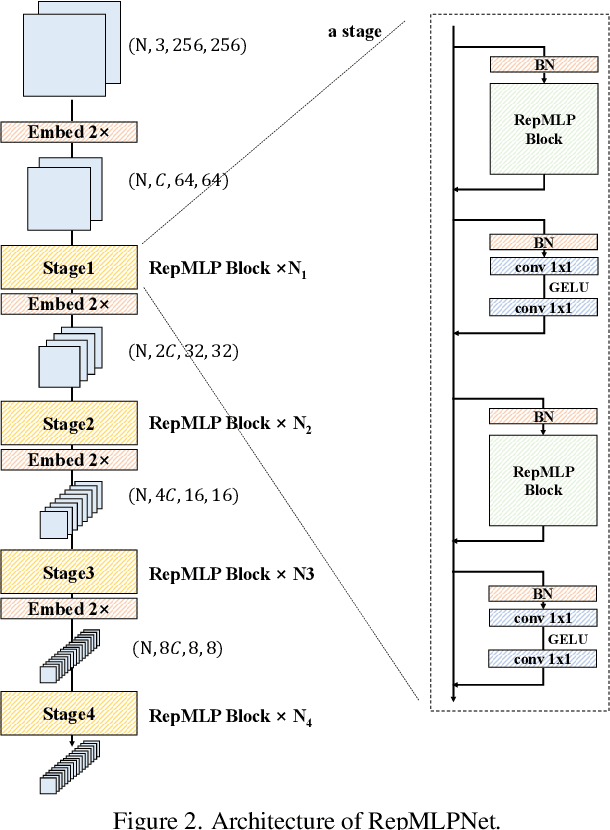
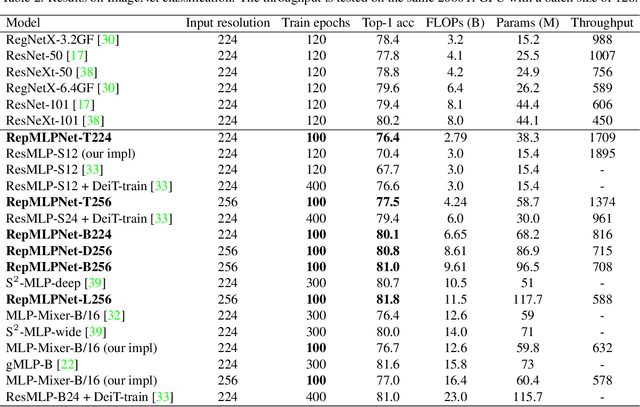
Compared to convolutional layers, fully-connected (FC) layers are better at modeling the long-range dependencies but worse at capturing the local patterns, hence usually less favored for image recognition. In this paper, we propose a methodology, Locality Injection, to incorporate local priors into an FC layer via merging the trained parameters of a parallel conv kernel into the FC kernel. Locality Injection can be viewed as a novel Structural Re-parameterization method since it equivalently converts the structures via transforming the parameters. Based on that, we propose a multi-layer-perceptron (MLP) block named RepMLP Block, which uses three FC layers to extract features, and a novel architecture named RepMLPNet. The hierarchical design distinguishes RepMLPNet from the other concurrently proposed vision MLPs. As it produces feature maps of different levels, it qualifies as a backbone model for downstream tasks like semantic segmentation. Our results reveal that 1) Locality Injection is a general methodology for MLP models; 2) RepMLPNet has favorable accuracy-efficiency trade-off compared to the other MLPs; 3) RepMLPNet is the first MLP that seamlessly transfer to Cityscapes semantic segmentation. The code and models are available at https://github.com/DingXiaoH/RepMLP.
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images
Jan 01, 2022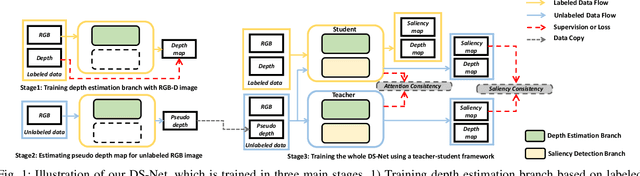
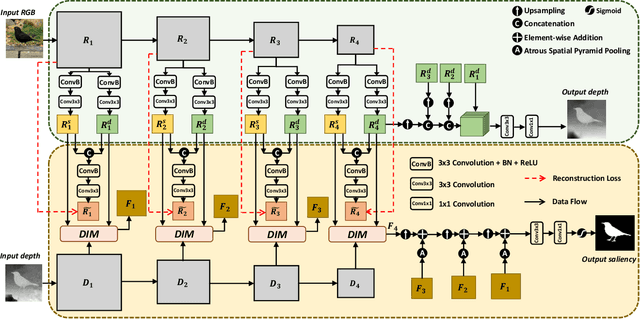
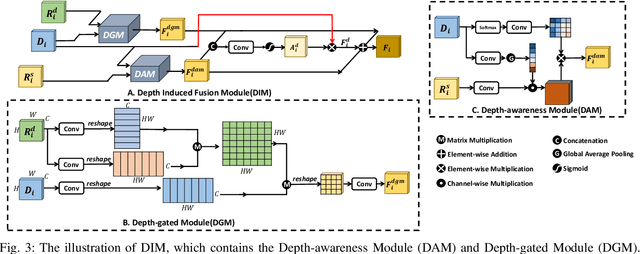

Training deep models for RGB-D salient object detection (SOD) often requires a large number of labeled RGB-D images. However, RGB-D data is not easily acquired, which limits the development of RGB-D SOD techniques. To alleviate this issue, we present a Dual-Semi RGB-D Salient Object Detection Network (DS-Net) to leverage unlabeled RGB images for boosting RGB-D saliency detection. We first devise a depth decoupling convolutional neural network (DDCNN), which contains a depth estimation branch and a saliency detection branch. The depth estimation branch is trained with RGB-D images and then used to estimate the pseudo depth maps for all unlabeled RGB images to form the paired data. The saliency detection branch is used to fuse the RGB feature and depth feature to predict the RGB-D saliency. Then, the whole DDCNN is assigned as the backbone in a teacher-student framework for semi-supervised learning. Moreover, we also introduce a consistency loss on the intermediate attention and saliency maps for the unlabeled data, as well as a supervised depth and saliency loss for labeled data. Experimental results on seven widely-used benchmark datasets demonstrate that our DDCNN outperforms state-of-the-art methods both quantitatively and qualitatively. We also demonstrate that our semi-supervised DS-Net can further improve the performance, even when using an RGB image with the pseudo depth map.
Projective Skip-Connections for Segmentation Along a Subset of Dimensions in Retinal OCT
Aug 02, 2021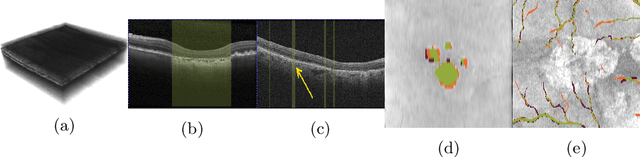
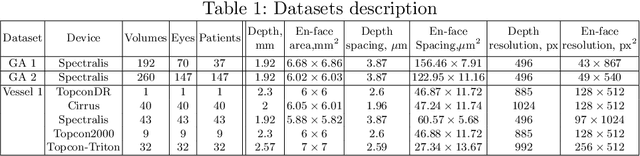
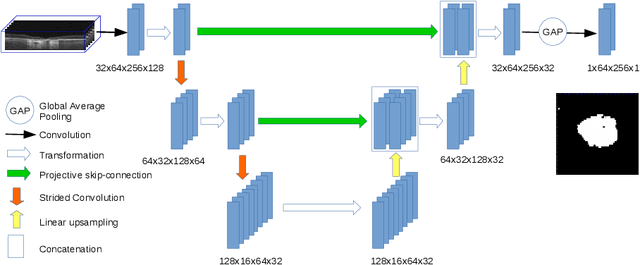
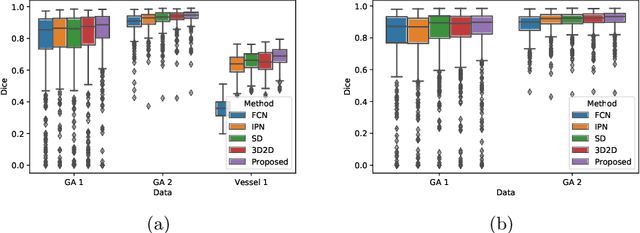
In medical imaging, there are clinically relevant segmentation tasks where the output mask is a projection to a subset of input image dimensions. In this work, we propose a novel convolutional neural network architecture that can effectively learn to produce a lower-dimensional segmentation mask than the input image. The network restores encoded representation only in a subset of input spatial dimensions and keeps the representation unchanged in the others. The newly proposed projective skip-connections allow linking the encoder and decoder in a UNet-like structure. We evaluated the proposed method on two clinically relevant tasks in retinal Optical Coherence Tomography (OCT): geographic atrophy and retinal blood vessel segmentation. The proposed method outperformed the current state-of-the-art approaches on all the OCT datasets used, consisting of 3D volumes and corresponding 2D en-face masks. The proposed architecture fills the methodological gap between image classification and ND image segmentation.
From Noise to Feature: Exploiting Intensity Distribution as a Novel Soft Biometric Trait for Finger Vein Recognition
Dec 15, 2021
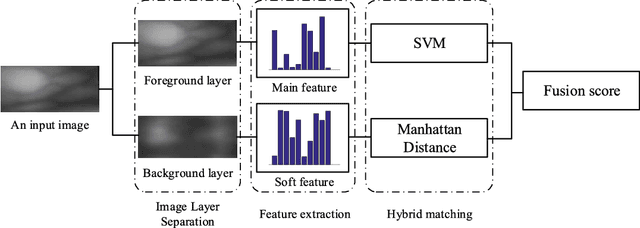
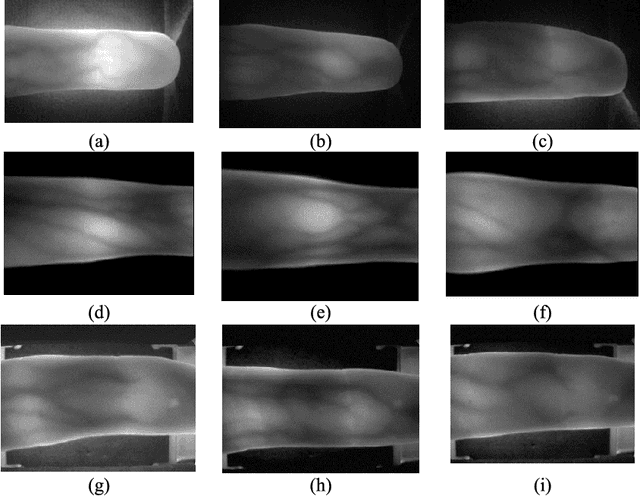

Most finger vein feature extraction algorithms achieve satisfactory performance due to their texture representation abilities, despite simultaneously ignoring the intensity distribution that is formed by the finger tissue, and in some cases, processing it as background noise. In this paper, we exploit this kind of noise as a novel soft biometric trait for achieving better finger vein recognition performance. First, a detailed analysis of the finger vein imaging principle and the characteristics of the image are presented to show that the intensity distribution that is formed by the finger tissue in the background can be extracted as a soft biometric trait for recognition. Then, two finger vein background layer extraction algorithms and three soft biometric trait extraction algorithms are proposed for intensity distribution feature extraction. Finally, a hybrid matching strategy is proposed to solve the issue of dimension difference between the primary and soft biometric traits on the score level. A series of rigorous contrast experiments on three open-access databases demonstrates that our proposed method is feasible and effective for finger vein recognition.
* 11 pages
Cold Posteriors Improve Bayesian Medical Image Post-Processing
Jul 12, 2021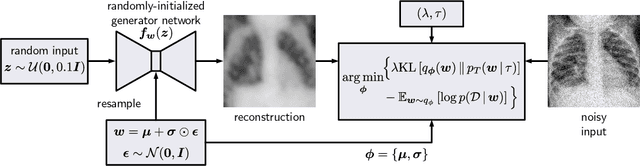
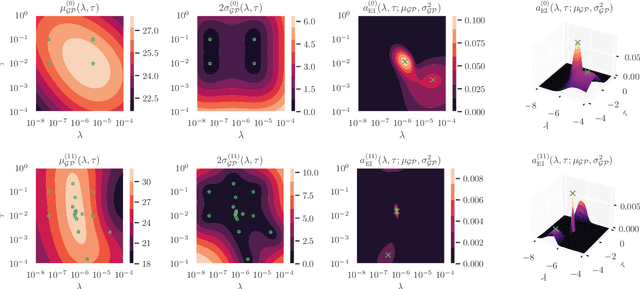
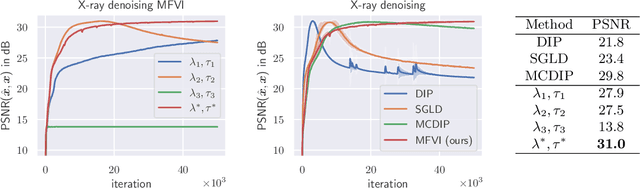
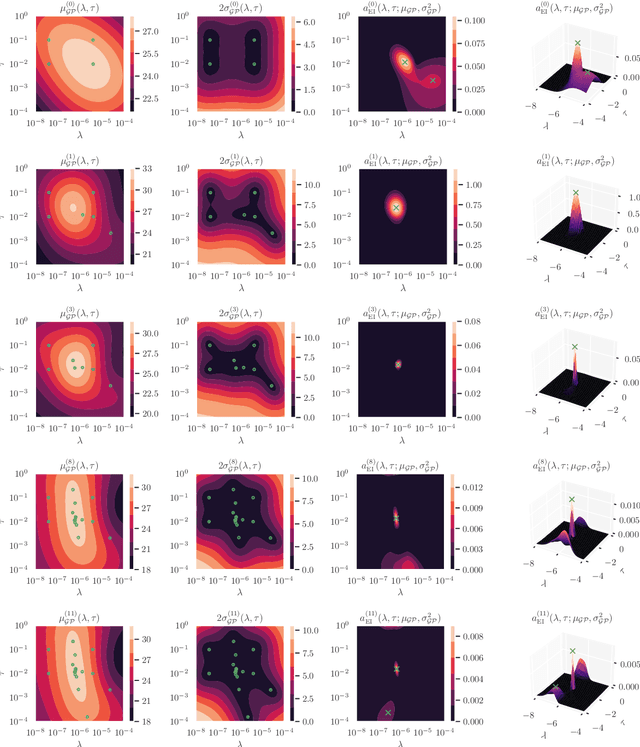
Cold posteriors have been reported to perform better in practice in the context of Bayesian deep learning (Wenzel et al., 2020). In variational inference, it is common to employ only a partially tempered posterior by scaling the complexity term in the log-evidence lower bound (ELBO). In this work, we optimize the ELBO for a fully tempered posterior in mean-field variational inference and use Bayesian optimization to automatically find the optimal posterior temperature and prior scale. Choosing an appropriate posterior temperature leads to better predictive performance and improved uncertainty calibration, which we demonstrate for the task of denoising medical X-ray images.
SPTS: Single-Point Text Spotting
Dec 15, 2021
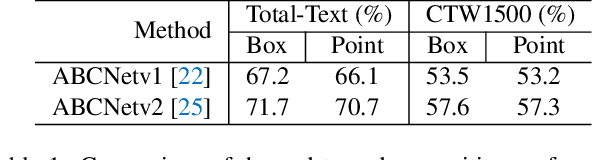

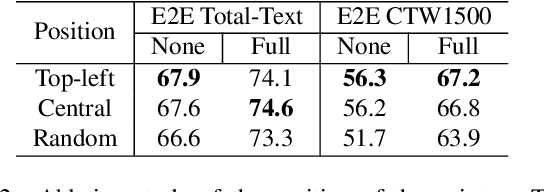
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.
Robust Depth Completion with Uncertainty-Driven Loss Functions
Dec 15, 2021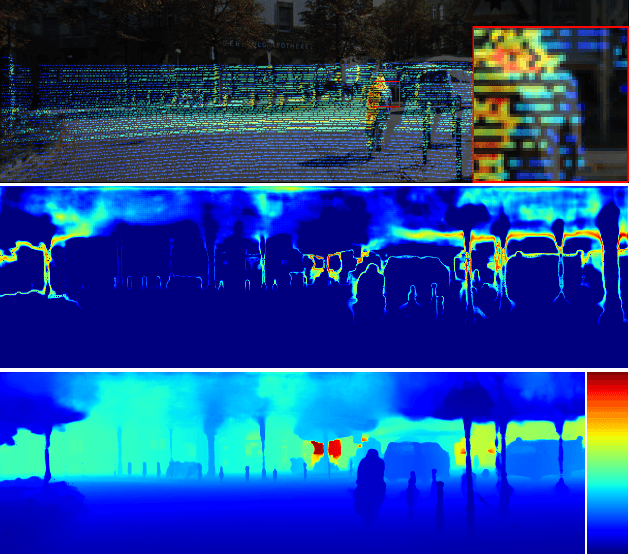
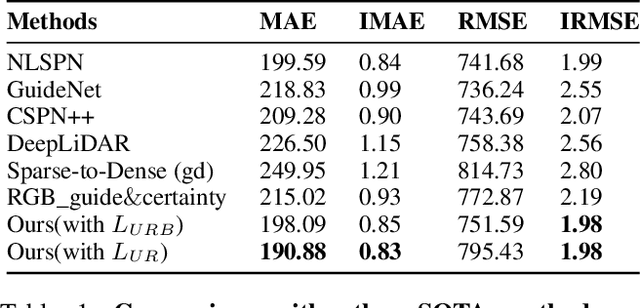
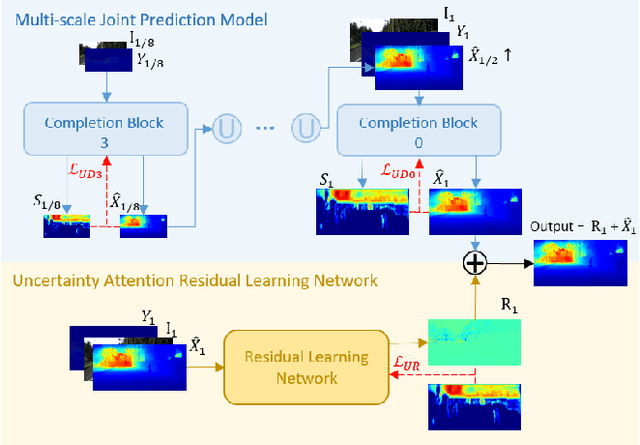
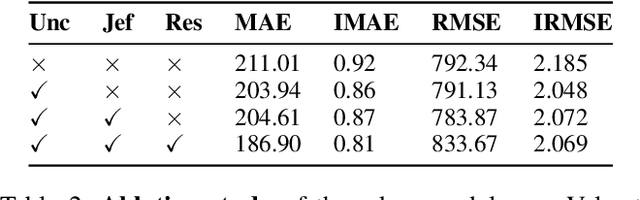
Recovering a dense depth image from sparse LiDAR scans is a challenging task. Despite the popularity of color-guided methods for sparse-to-dense depth completion, they treated pixels equally during optimization, ignoring the uneven distribution characteristics in the sparse depth map and the accumulated outliers in the synthesized ground truth. In this work, we introduce uncertainty-driven loss functions to improve the robustness of depth completion and handle the uncertainty in depth completion. Specifically, we propose an explicit uncertainty formulation for robust depth completion with Jeffrey's prior. A parametric uncertain-driven loss is introduced and translated to new loss functions that are robust to noisy or missing data. Meanwhile, we propose a multiscale joint prediction model that can simultaneously predict depth and uncertainty maps. The estimated uncertainty map is also used to perform adaptive prediction on the pixels with high uncertainty, leading to a residual map for refining the completion results. Our method has been tested on KITTI Depth Completion Benchmark and achieved the state-of-the-art robustness performance in terms of MAE, IMAE, and IRMSE metrics.
Gaze Estimation with Eye Region Segmentation and Self-Supervised Multistream Learning
Dec 15, 2021
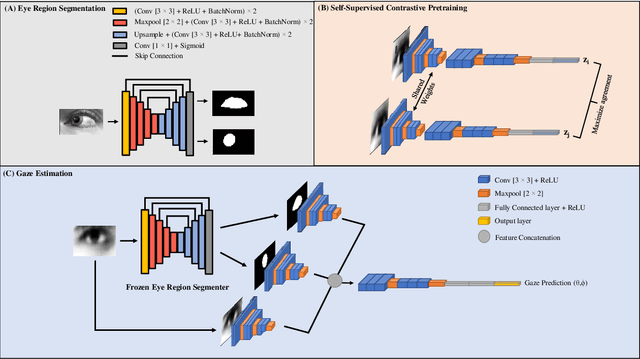


We present a novel multistream network that learns robust eye representations for gaze estimation. We first create a synthetic dataset containing eye region masks detailing the visible eyeball and iris using a simulator. We then perform eye region segmentation with a U-Net type model which we later use to generate eye region masks for real-world eye images. Next, we pretrain an eye image encoder in the real domain with self-supervised contrastive learning to learn generalized eye representations. Finally, this pretrained eye encoder, along with two additional encoders for visible eyeball region and iris, are used in parallel in our multistream framework to extract salient features for gaze estimation from real-world images. We demonstrate the performance of our method on the EYEDIAP dataset in two different evaluation settings and achieve state-of-the-art results, outperforming all the existing benchmarks on this dataset. We also conduct additional experiments to validate the robustness of our self-supervised network with respect to different amounts of labeled data used for training.
Cycled Compositional Learning between Images and Text
Jul 24, 2021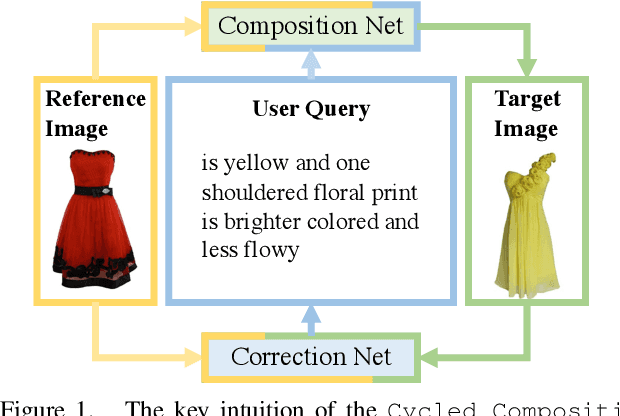
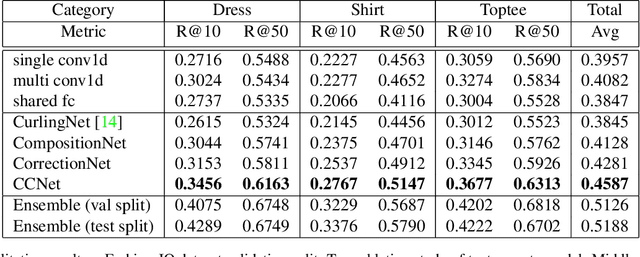
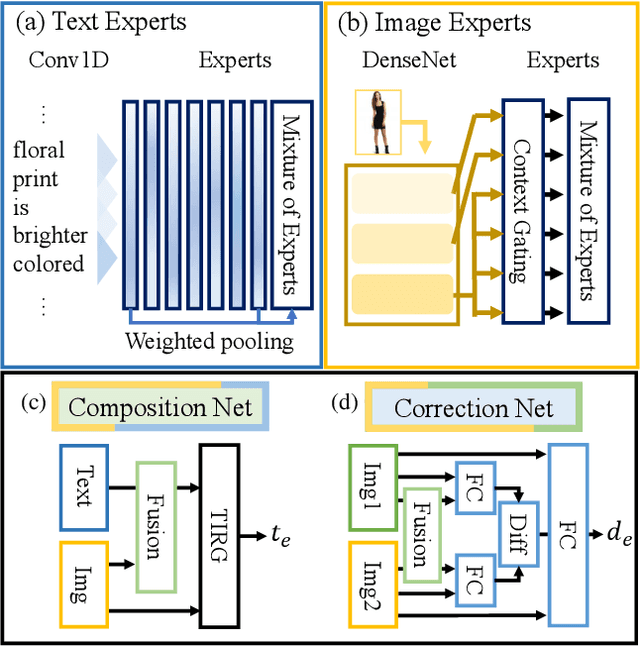
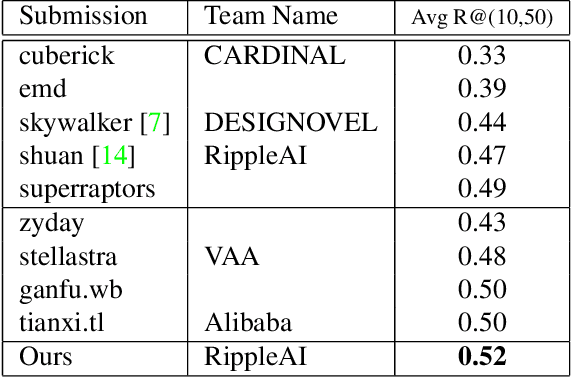
We present an approach named the Cycled Composition Network that can measure the semantic distance of the composition of image-text embedding. First, the Composition Network transit a reference image to target image in an embedding space using relative caption. Second, the Correction Network calculates a difference between reference and retrieved target images in the embedding space and match it with a relative caption. Our goal is to learn a Composition mapping with the Composition Network. Since this one-way mapping is highly under-constrained, we couple it with an inverse relation learning with the Correction Network and introduce a cycled relation for given Image We participate in Fashion IQ 2020 challenge and have won the first place with the ensemble of our model.